Results from Pri-Matrix Factorization and a New Open Source Tool for Wildlife Research and Conservation¶
Using AI to study the natural world¶
Camera traps are a critical part of wildlife monitoring but analyzing those videos are a big bottleneck in our conservation activities. Developing an automated procedure is of the utmost importance to conservation research in sub-Saharan Africa and across the globe.
Dr. Christophe Boesch, Wild Chimpanzee Foundation / Max Planck Institute for Evolutionary Anthropology
The DrivenData Pri-matrix Factorization Challenge brought advances in computer vision to chimpanzee habitats in West and Central Africa. In this competition, data scientists from more than 90 countries around the world drew on more than 300,000 video clips in an attempt to build the best machine learning models for automatically identifying wildlife in camera trap footage.
While camera traps have become powerful non-invasive tools in research and conservation efforts, they can't yet autonomously label the species they observe. It takes a lot of valuable time to determine whether or not there are any animals present in the videos, and if so, which ones. Sometimes camera traps are triggered by animals of interest, others by falling branches or passing winds.
This is where machine learning can help. Advances in artificial intelligence and computer vision hold enormous promise for taking on intensive video processing work and freeing up more time for humans to focus on interpreting the content and using the results.
This project combined the distributed efforts of two amazing online communities:
-
Thousands of citizen scientists manually labeled video data through the Chimp&See Zooniverse project. In partnership with experts at The Max Planck Institute for Evolutionary Anthropology (MPI-EVA), this effort fed into a well-labeled dataset of nearly 2000 hours of camera trap footage from Chimp&See's database.
-
Then, using this dataset, the ARCUS foundation generously provided funding for DrivenData and MPI-EVA to run a machine learning challenge where hundreds of data scientists competed to build the best algorithms for automated species detection. The top 3 submissions best able to predict the presence and type of wildlife across new videos won the challenge and received €20,000 in monetary prizes.
The winning algorithm from the challenge achieved 96% accuracy identifying presence of wildlife, and 99% average accuracy identifying species. Meanwhile, the algorithm recorded an average recall of 70% across species, up to 96% for the three most common labels (blank, human, and elephant). This and the other winning solutions are openly available for anyone to learn from or use in the DrivenData winners GitHub repository.

But wait, there’s more! In an effort to make these advances more widely available to ecologists and conservationists, the top algorithm was also simplified and adapted for use in an open source command-line tool. An overview of “Project Zamba” with links to the project repository and instructions for getting started is available at zamba.drivendata.org.
Read more about Project Zamba, the approaches that fed into it and beat out the competition, and meet the primates who built them below!
Project Zamba¶

Zamba means forest in Lingala. For centuries researchers have argued that a thorough understanding of the wildlife ecology in African zambas could reveal critical insights into our origins as humans.
As aritificial intelligence advances our capabilities in image and video processing, a task central to many wildlife research efforts, we need tools that are more accessible for ecologists and conservationists. Project Zamba is an open source command-line tool and Python library designed to take a step towards making state of the art AI technology more widely available not just for data scientists, but also for the practitioners that can benefit most from their use.
Learn how to install and get started using Zamba by visiting the documentation page, or check out the latest version of the project codebase on GitHub!
Meet the winners¶
Dmytro Poplavskiy¶

Place: 1st
Prize: €12,000
Hometown: Brisbane, Australia
Username: dmytro
Background:
I’m an experienced software engineer with the recent interest in machine learning.
Dmytro also finished 1st in the recent N+1 Fish, N+2 Fish competition to analyze fish from on-board videos to support sustainable fishing practices!
Summary of approach:
- Fine-tuned multiple ImageNet pre-trained convolutional neural networks on randomly selected frames from video clips using stratified 4 folds split
- Predicted classes for 32 frames per clip and combined predictions in a way time specific information is dropped and only combined prediction statistics used.
- Trained the second level models (xgboost, neural network, lightgbm) on out of fold CNN model predictions.
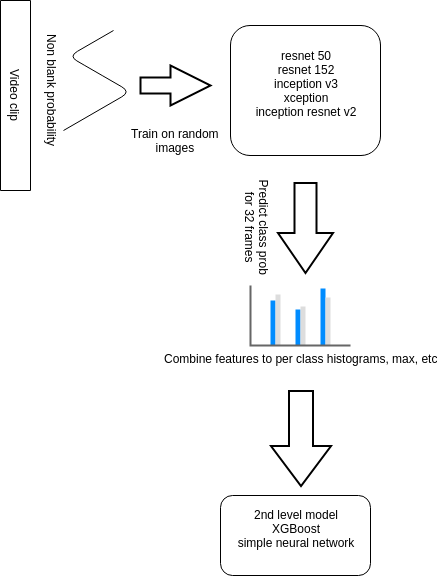
Check out dmytro’s full write-up and solution in the competition repo.
Roman Solovyev¶

Place: 2nd
Prize: €6,000
Hometown: Moscow, Russia
Username: ZFTurbo
Background: I’m Ph.D in microelectronics field. Currently I’m working in Institute of Designing Problems in Microelectronics (part of Russian Academy of Sciences) as Leading Researcher. I often take part in machine learning competitions for last 2 years. I have extensive experience with GBM, Neural Nets and Deep Learning as well as with development of CAD programs in different programming languages (C/C++, Python, TCL/TK, PHP etc).
Roman also finished 2nd in the recent N+1 Fish, N+2 Fish competition to analyze fish from on-board videos to support sustainable fishing practices!
Summary of approach:
The solution is divided into the following stages:
- preprocessing
- metadata extraction
- extract image hashes
- extract features with pre-trained neural nets
- train neural net models based on 3D convolutions
- train neural net models for audio data
- train neural net models for extracted features from pre-trained nets
- train recurrent neural net models for image hashes
- validation for all neural nets
- process test data for all neural nets
- generate neighbor features
- run models of second level
- final weighted ensemble
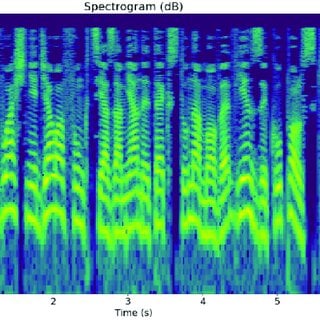
Full dataflow in one image:
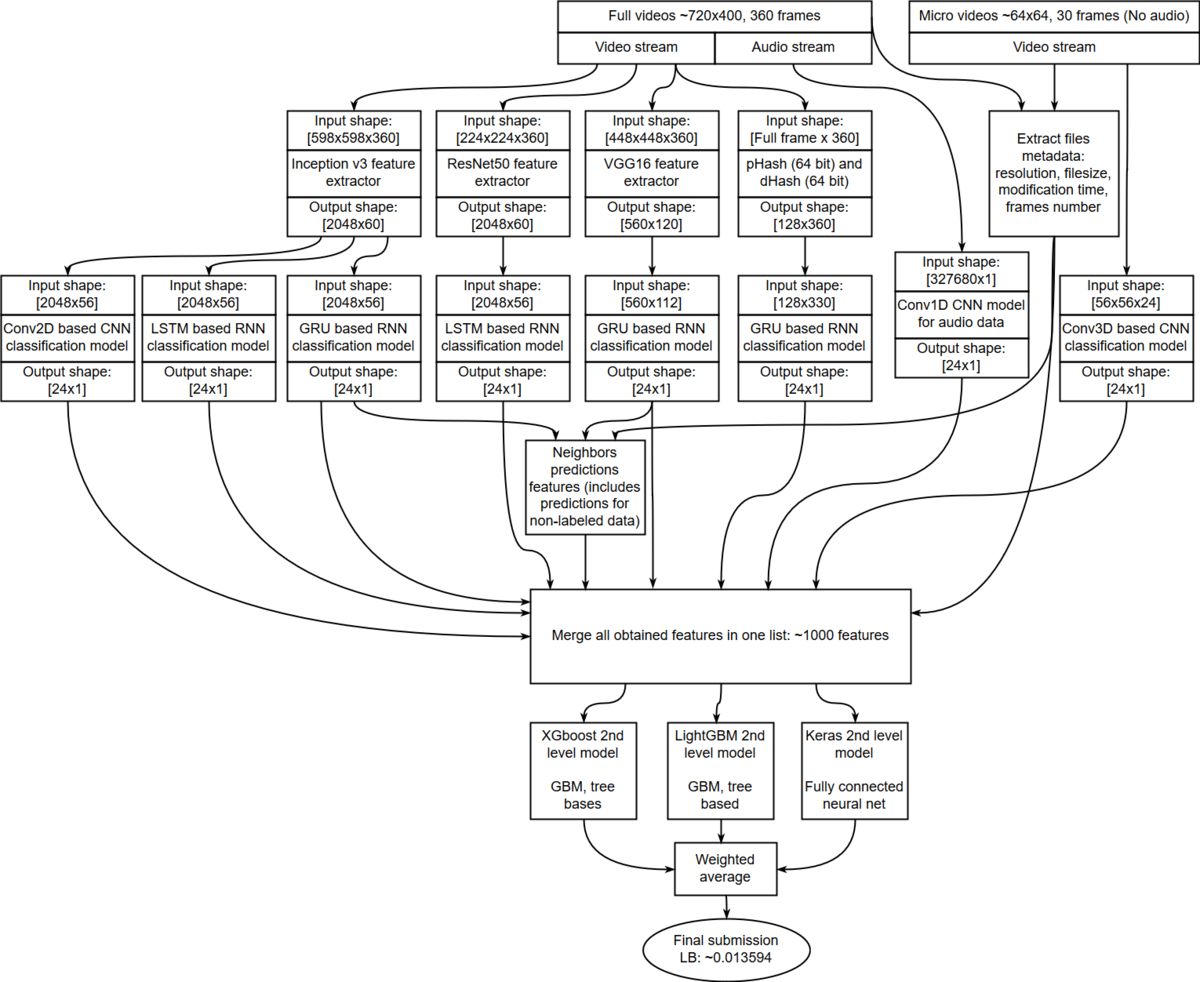
Check out ZFTurbo's full write-up and solution in the competition repo.
Team: Alexander Veysov and Savva Kolbachev¶

|

|
Place: 3rd
Prize: €2,000
Hometown: Moscow, Russia and Minsk, Belarus
Usernames: aveysov and thinline72
Background:
Alexander:
- BA (IT + math department in MGIMO) and MA in Economics + foreign languages (I graduated from MGIMO University - they mostly give you 2 degrees - your major + 2-3 foreign languages);
- My career more or less in a nutshell (note the pivots):
- ~3 years in finance / VC;
- ~3 years management / product management / internet / IT;
- ~1 year in Data Science;
- Now I work for Sequoia backed American company as a data scientist;
Savva:
- I'm a ML Engineer with software engineering and math background at ObjectStyle https://www.objectstyle.com/.
- I graduated from BSU with a degree in Computer Mathematics and Systems Analysis.
Summary of approach:
Notes from Alexander:
- Extract skip features from best modern CNNs (resnet, inception v4, inception-resnet 2, nasnet among others);
- Use meta-data and attention layer (in essence trainable pooling) for classification on each set of features;
- Use all the features together for an ensemble models;
- Use several folds + weak semi supervised approach + blend the resulting models;
Notes from Savva:
- Attention and Max-Min pooling gave us great results, much better than default Max/Avg poolings
- Different kind of RNNs didn't really provide better score and they required much more time to train. But we used few trained RNN models in the final stacking though
- Proper stratified multi-label validation splitting. Usually our result on validation was a bit worse than result on LB
- Concatenating different extracted features
- Training separate model for blank/not blank classes
- Pseudo-labeling always gave a slight boost for our models
- Stacking trained models together gave us final
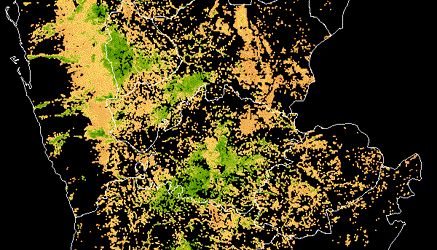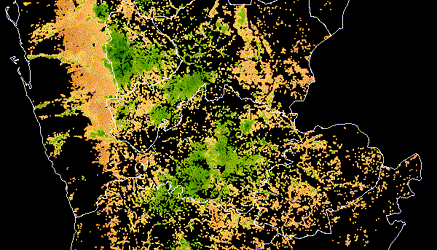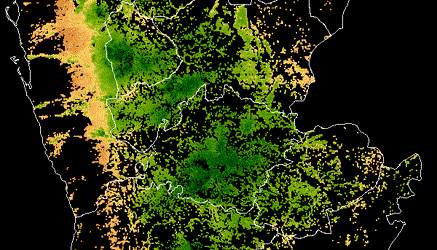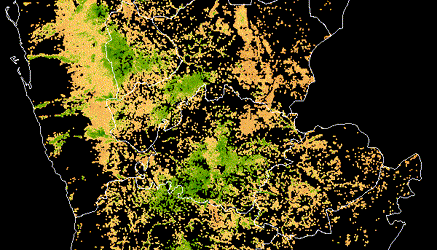
Also this is the chart for our solution - it may be handy.
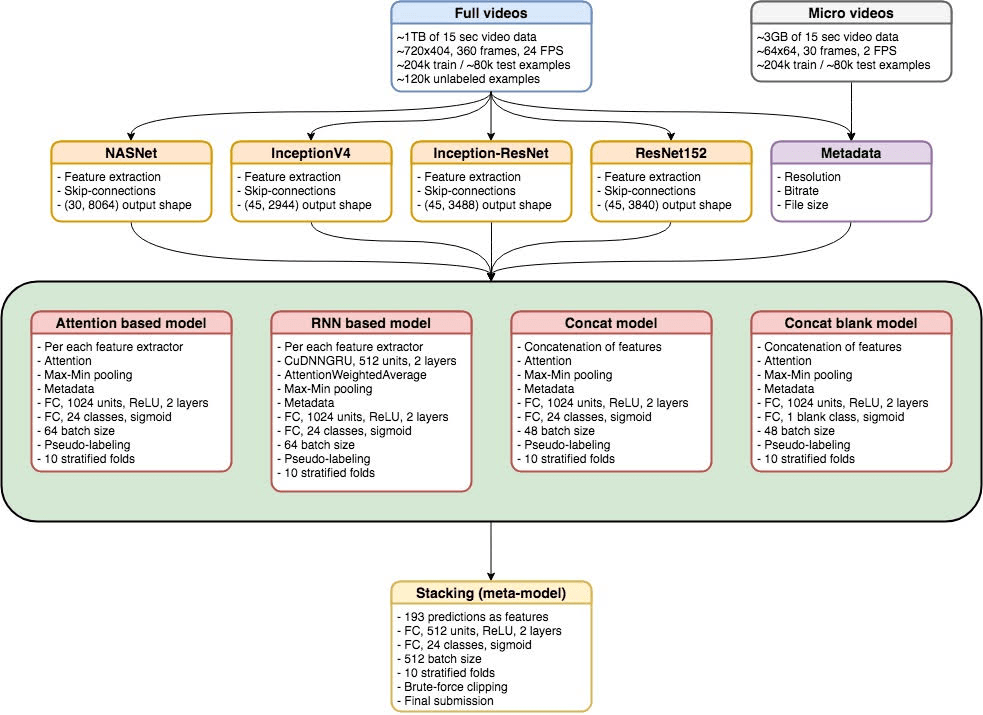
Check out Team AVeysov SKolbachev’s full write-up and solution in the competition repo.
Thanks to all the participants and to our winners! Special thanks to the Project Team for providing data and support throughout this challenge, and to the ARCUS foundation for providing the funding to make this fantastic project possible!