The Challenge¶
Alzheimer's disease and Alzheimer's disease-related dementias (AD/ADRD) are a group of brain disorders characterized by progressive cognitive impairments that severely impact daily functioning. Early prediction of AD/ADRD is crucial for potential disease modification through emerging treatments, but current methods are not sensitive enough to reliably detect the disease in its early or presymptomatic stages.
The PREPARE: Pioneering Research for Early Prediction of Alzheimer's and Related Dementias EUREKA Challenge seeks to advance solutions for accurate, innovative, and representative early prediction of AD/ADRD. To achieve this goal, the challenge features three phases that successively build on each other.
| Phase | Description |
|---|---|
| Phase 1 [Find IT!] | Find, curate, or contribute data to create representative and open datasets that can be used for early prediction of AD/ADRD. |
| Phase 2 [Build IT!] | Advance algorithms and analytic approaches for early prediction of AD/ADRD, with an emphasis on explainability of predictions. |
| Phase 3 [Put IT All Together!] | Top solvers from Phase 2 demonstrate algorithmic approaches on diverse datasets and share their results at an innovation event. |
In Phase 2, participants created models to predict cognitive decline. Participants competed in two modeling tracks. In the Acoustic Track, participants predicted an AD/ADRD diagnosis based on voice recordings. In the Social Determinants of Health Track, participants predicted someone's score on a cognitive screening based on survey data. Winners were selected based on a combination of leaderboard score and a model methodology report.
During Phase 3, Phase 2 winners will refine their models and share learnings from the process.
Results¶
Over 400 participants joined each competition track, generating over 200 submissions total. In the Acoustic track, winners achieved a multiclass log loss of 0.63, demonstrating strong signal in rich acoustic data. In the Social Determinants of Health track, winners reduced root mean squared error (RMSE) to 38.2, an impressive achievement given that cognitive assessment scores ranged from 0 to 384.
Below are a few takeaways from the submissions.
Acoustic Track¶
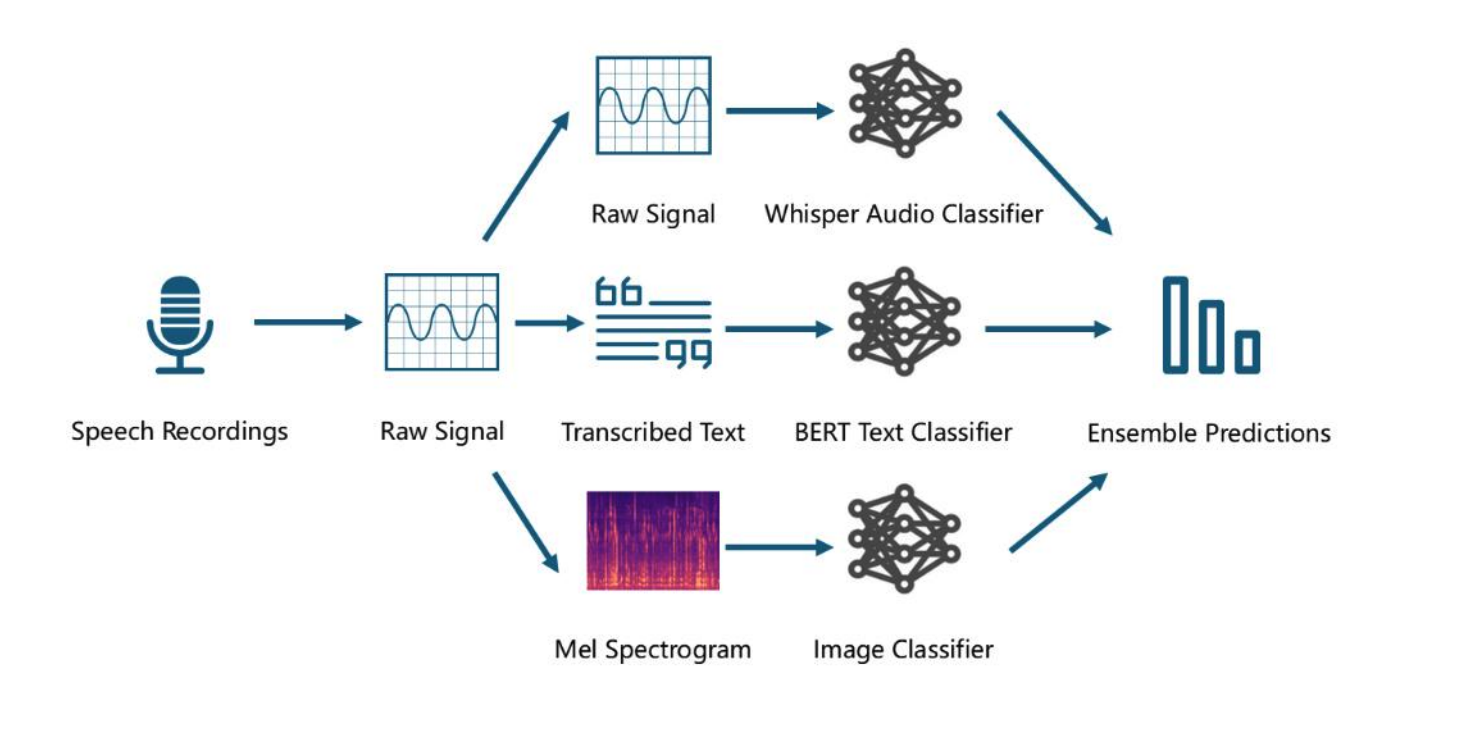
In the Acoustic Track, participants used voice data to predict people's current diagnosis: control, mild cognitive impairment, or an advanced AD/ADRD diagnosis. The data for this track came from DementiaBank, an open database for the study of communication progression in dementia that combines data from different research studies. Solvers had access to raw audio of different types of communicative interactions (e.g., language research tasks) as well as traditional acoustic features derived from the audio.
The most effective approaches used transformer models pre-trained on lots of speech data. All of the top models used the encoder of a pretrained model to generate embeddings, and added their own classification layer. The most common model was Whisper, followed by Wav2Vec and HuBERT. Some participants combined a transformer neural network with a tree-based model or support vector machine (SVM).
For more practical guidance about extracting ML features from speech data, including example code to generate transformer embeddings, see this blog post!
Interpreting model features in a real-world context is difficult with voice data. This is particularly difficult with transformer-generated embeddings. Traditional acoustic features like pitch are manually engineered based on our understanding of speech. Transformer embeddings, on the other hand, are generated solely to optimize predictive power. Some top models combined transformer embeddings with traditional acoustic features like pitch, while others used transformer embeddings alone.
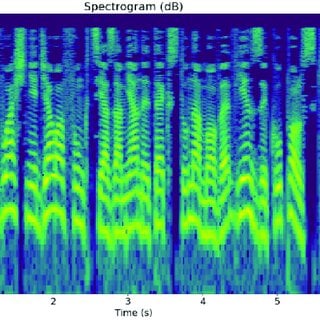
We can apply techniques for working with image data effectively to voice data spectrograms. A spectrogram is a visual representation of how much each frequency contributed to a sound over time. Many learnings about working with image data generally hold true for spectrograms. For example, class activation mappings (CAMs) are heatmaps commonly used in computer vision to study how much different parts of an image influence a neural network. Participants used CAMs effectively to identify which frequency ranges and times influenced their models.
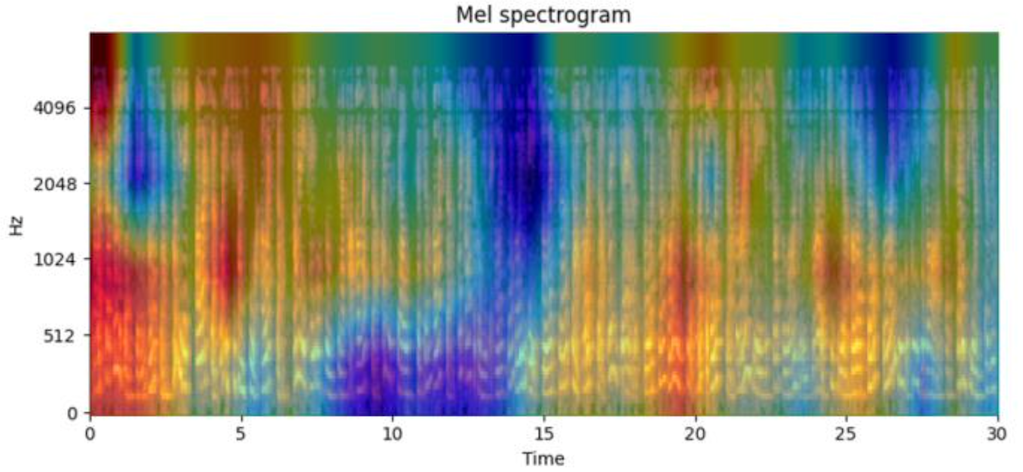
Winner SALEN learned from CAM that their model trained to detect healthy samples relied most on the mid-frequency range, while their model trained to predict mild cognitive impairment placed more attention on lower frequencies. Their model predicting advanced decline placed heightened attention on both extremely low and high frequencies.
Social Determinants of Health Track¶
In this track, participants predicted cognitive function using longitudinal survey data from the Mexican Health and Aging Study (MHAS), a population-representative national study of older adults in Mexico. The competition data came from a sub-sample that completed in-depth cognitive assessments as part of the Cognitive Aging Ancillary Study (Mex-Cog). Solvers used 2016 demographics, economic circumstances, migration, physical limitations, self-reported health, and lifestyle behaviors to predict a composite cognitive function score in 2021.
The top submissions all used tree-based models, most commonly LightGBM, CatBoost, and XGBoost. The data is high dimensional, with over 150 variables, many of which correlate. Tree-based models excel at capturing interactions between variables. A downside of using trees is the risk of overfitting, particularly in this case with relatively few samples. Participants took a variety of creative approaches to improve generalizability. Some set model parameters like maximum tree depth. Winner Cassandre selected a smaller set of features by testing which were still statistically significant when controlling for age and education.
Education is a strong predictor of decline. Education and (unsurprisingly) age had high feature importance across winning models. One winner, NxGTR, fit separate models to predict the speed and acceleration of decline. When looking at acceleration, they found that income began to play a larger role than education. Generally, winners found that their models performed similarly well across other demographic variables like gender and urban/rural.
Winner overview¶
Acoustic Track overall winners:
| Prize | Winner | Multiclass log loss |
|---|---|---|
| 1st Place | sheep and cecilia | 0.6299 |
| 2nd Place | Harris and Kielo | 0.6343 |
| 3rd Place | team SALEN | 0.6523 |
Social Determinants of Health Track overall winners:
| Prize | Winner | RMSE |
|---|---|---|
| 1st Place | RASKA-Team | 38.2030 |
| 2nd Place | NxGTR | 38.4827 |
| 3rd Place | Cassandre | 38.4932 |
Special Recognition prize winners:
- SpeechCARE for data processing (Acoustic)
- IGC Pharma for generalizability (Acoustic)
- BrainSignsLab for generalizability (Acoustic)
- GiaPaoDawei for feature selection (Social Determinants of Health)
Explainability Bonus prize winners:
- Nick and Ry (Social Determinants of Health)
- SpeechCARE (Acoustic)
- team SALEN (Acoustic)
Community Code bonus prizes:
- Team ChongYa (users hairongwhr, lingchm, sn_ks, jingyuli, marciemao, and wangdadong)
- Team Uky_Team (users moghis, qiangcheng8, and aseslamian)
- Team Health AI (users xvii and chi-chi)
Four additional posts, not eligible for a prize, were also identified as most helpful to the community: shaulab, igel, emreatilgan, and bjornjjs.
Meet the Winners of the Acoustic Track¶
sheep and cecilia¶

Team members: Yinglu Deng, Yang Xu
Place: 1st Overall
Prize: $40,000
Hometowns: San Diego, California and LiShui ZheJiang, China
Usernames: sheep, cecilia12312
Social Media: linkedin.com/in/yinglu-cecilia-deng
Background:
We are experienced engineers at a medical company, all holding Master of Science degrees. Our professional work involves processing and analyzing medical data, particularly focusing on image and audio data. Beyond our primary roles, we are enthusiastic participants in data science competitions and have achieved multiple victories in these contests.
Summary of approach:
Our prediction pipeline integrates the OpenAI Whisper pre-trained encoder with a classifier augmented by clinical features. Our pipeline incorporates a two-stage training approach designed to mitigate language bias and enhance generalizability. To enhance model interpretability, we employ a CAM-based explanation method that pinpoints temporal regions critical to decision-making.
Harris and Kielo¶


Team members: Matthew Kielo and Harris Alterman
Place: 2nd Overall
Prize: $25,000
Hometowns: Kingston, Ontario and Denver, Colorado
Usernames: harrisalterman, mkielo
Background:
Matthew Kielo is currently completing a Master’s in Computer Science from Georgia Tech and has spent his professional career working in quantitative finance.
Harris Alterman has a bachelor’s degree in arts with a focus on communication from the University of Waterloo. He currently works as a content creator in New York and has an avid interest in all forms of communication.
Summary of approach:
The approach was inspired by the idea that all speech contains two types of information: 1) what was said, and 2) how it was said. We developed multiple sub-models to try and capture information across both of these types. The final sub-models use broad semantic clustering, an ensemble of the provided acoustic features, a Whisper classification fine-tune, and a contrastive Whisper fine-tune, designed to focus the model on identifying features independent of age, gender, and semantic group.
Use visualizations from the process:
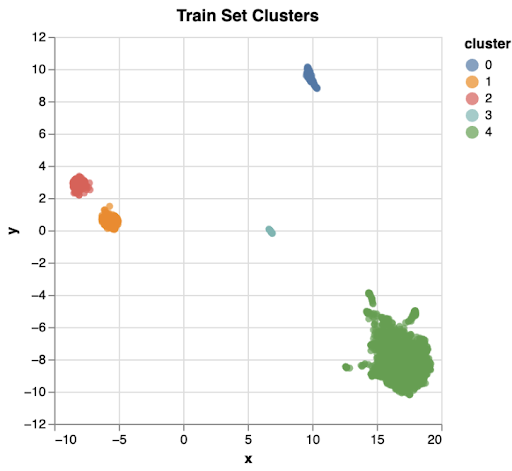
The plot below shows a 2-dimensional embedding of the semantic content of the audio transcripts. Seeing this plot in the first few days of the competition was a small “ah-ha” moment. Cluster 0 was in English and included many people talking to an Alexa. Cluster 1 and 2 were both Spanish. Cluster 3 was Mandarin. Cluster 4 was English and included many people describing a scene with an overflowing sink (which we later learned to be the famous Cookie Theft picture/test).
This had a few concrete impacts. 1) The clustering motivated the triplet loss approach (ex: how to encourage the model to find intra-cluster differences), 2) Finding changes that improved performance across clusters indicated generalizability, 3) Seeing how similar many transcripts were led us away from linguistic approaches, given that there was less linguistic variety than we initially anticipated.
team SALEN¶


Team members: Ruxin Zhang, Jie Tian, and Fangjing Wu
Place: 3rd Overall and Explainability Bonus
Prize: $15,000 + $10,000
Usernames: SALEN, SeanML001, RUXINZ3
Background:
Ruxin Zhang (captain) is a psychology and biology junior student. Jie Tian is a practicing physician. Fangjing Wu is a data science master's student.
Summary of approach:
We developed a multimodal model for early prediction of Alzheimer’s disease (AD) and Alzheimer’s disease-related dementias (ADRD), integrating voiceprint, timbre, and semantics. Guided by a physician on our team, the model prioritizes clinical applicability and aligns with established diagnostic guidelines. To support practical implementation, we designed a clinical decision support system (CDSS) for deployment in hospitals, health centers, and screening programs.
Meet the Winners of the Social Determinants of Health Track¶
RASKA-Team¶



Team members: Suhas D. Parandekar, Ekaterina Melianova, Artem Volgin
Place: 1st Overall
Prize: $40,000
Hometowns: Washington, DC and London, UK
Usernames: artvolgin, Amelia, sparandekar
Background:
Suhas D. Parandekar is a Senior Economist at the World Bank’s Global Education Practice, where he leads cross-functional teams on projects in education, science, technology, and innovation.
Ekaterina Melianova recently completed a PhD in Advanced Quantitative Methods at the University of Bristol, UK. Her work focuses on applying innovative statistical methods to real-world social challenges, particularly in social epidemiology, health, and education.
Artem Volgin recently completed a PhD in Social Statistics at the University of Manchester, UK. His research focuses on applications of Network Analysis and Natural Language Processing, and he has extensive experience working with real-world data across diverse domains.
Summary of approach:
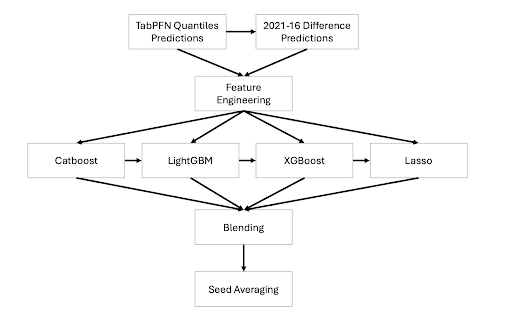
Our approach had several key components:
- TabPFN: We used TabPFN, a pre-trained transformer model for small tabular data, to generate quantile-based features that enriched downstream models.
- Feature Engineering: We engineered features to capture socio-demographic, temporal, and group-level effects (e.g., changes between 2003 and 2012).
- Sequential Modeling: We predicted cognitive scores using a sequence of models (LightGBM → XGBoost → CatBoost → Lasso), with each model refining the output of the previous one.
- Group-Based Blending: We used age-based and prediction quantile-based groupings to blend predictions from multiple models using SoftMax-weighted averages.
NxGTR¶

Team members: Carlos Huertas
Place: 2nd Overall
Prize: $25,000
Hometown: Seattle, WA
Social Media: https://www.linkedin.com/in/carloshuertasgtr/
Background:
I am originally from Tijuana Mexico. I studied Computer Science and really enjoyed the AI space, although hardware resources were always limited, which shaped my push to always simplify. Following this path, I completed my PhD in the area of feature selection for high-dimensional spaces. Currently I work for Amazon as an Applied Scientist where we develop Machine Learning technology to protect Amazon and customers from fraudulent activity.
What motivated you to compete in this challenge?
As a scientist, I always look for evidence of state-of-the-art (SOTA). I believe that it's hard to truly define the real SOTA until a well-controlled experiment with no bias is designed. I found competitions in general meet this requirement. This event uses data from the Mexican Health and Aging Study (MHAS), which is an additional motivator since I was born there. I am constantly looking for ways I could contribute to a large society to give back when I can. This was a nice opportunity to do so.
Summary of approach:
I relied mostly on feature engineering, cleaning and formatting the data so that any algorithm could take advantage of it. “Simplicity is the ultimate sophistication”, I pushed myself to build a tiny 9-lines of code solution that can still get top position. The more I focus on the data, the less hardware requirements matter, this can allow my solution to help more people, for less cost.
Cassandre¶

Team members: Leonid Chuzhoy
Place: 3rd Overall
Prize: $15,000
Hometown: Glenview, IL
Background:
I have a background in astrophysics, data science, and geopolitical forecasting.
Summary of approach:
I used LightGBM decision tree algorithm to predict the difference between test participants’ scores from different years. Next, for participants who had been tested in 2016, I estimated their 2021 scores by adding the predicted score difference to their 2016 scores. These estimates were then combined with the actual 2021 scores to train a decision tree model for predicting test scores in 2021. Similarly, estimated scores from 2016 were combined with the actual scores to train a decision tree model for predicting test scores in 2016.
Meet the bonus prize winners¶
SpeechCARE¶

Team members: Maryam Zolnoori, Hossein Azad Maleki, Ali Zolnour, Yasaman Haghbin, Sina Rashidi, Mohamad Javad Momeni Nezhad, Fatemeh Taherinezhad, Maryam Dadkhah, Mehdi Naserian, Elyas Esmaeili, Sepehr Karimi, Seyedeh Mahdis Hosseini
Place: Special Recognition for data processing + Explainability Bonus (Acousic track)
Prize: $10,000 + $10,000
Hometown: New York, NY
Social media: Maryam Zolnoori
Usernames: maryamzolnoori, yasaman.haghbin, armin_naserian, elyasesmaeili, azadmaleki, sinarashidi
Background:
SpeechCARE team has extensive experience developing speech processing pipelines for cognitive impairment detection. Given the variability in speech corpus characteristics (e.g., speech tasks, languages) and audio quality, no single approach consistently yields optimal performance. Therefore, our team is actively exploring and refining diverse methodologies to address the critical unmet need for early detection of cognitive impairment. Our team is based out of Columbia University Irving Medical Center.
What motivated you to compete in this challenge?
We were motivated by the critical public health need for equitable, early detection of cognitive impairment—especially in underdiagnosed populations. The PREPARE Challenge offered a unique opportunity to test our models on real, multilingual, and diverse speech data, which mirrors the complexity we encounter in clinical practice. Our team is particularly passionate about developing accessible and explainable tools for frontline healthcare providers and caregivers.
Summary of approach:
SpeechCARE is a multimodal speech processing pipeline leveraging pretrained, multilingual acoustic and linguistic transformer models to capture nuanced acoustic and linguistic cues associated with cognitive impairment. Inspired by Mixture of Experts (MoE) paradigm, its core architecture dynamically weights transformer-driven acoustic and linguistic features, enhancing performance and generalizability across different speech production tasks (e.g. story recall, sentence reading). SpeechCARE’s robust preprocessing pipeline includes automatic transcription, LLM (Large Language Model)-assisted data anomaly detection, and LLM-assisted speech task identification. Various techniques (e.g., oversampling, weighted loss) were used for bias mitigation.
IGC Pharma¶




Team members: Ram Mukunda, Paola Ruíz Puentes, Nestor González, Daniel Crovo
Place: Special Recognition for generalizability (Acousic track)
Prize: $10,000
Hometowns: Potomac, MD; Bogotá, Colombia; and Washington, DC
Usernames: IGCPHARMA, PaolaRuiz-IGC, ngonzalezigc, dcrovo.
Social media: Ram Mukunda, Paola Ruiz Puentes, Nestor Gonzalez, Daniel Crovo
Background:
IGC Pharma is at the forefront of clinical-stage biotechnology, passionately dedicated to revolutionizing Alzheimer’s disease treatment. Our flagship drug, IGC-AD1, targets agitation in Alzheimer’s dementia and is showing remarkable promise in Phase 2 trials. Unlike traditional medications that may take 8-10 weeks to show effects, IGC-AD1 has the potential to provide significant relief within just two weeks, a breakthrough that could profoundly enhance patient care. In addition to our therapeutic advancements, we are leveraging cutting-edge AI models to predict early biomarkers for Alzheimer’s and optimize clinical trials. Our AI research also investigates potential interactions with receptors like GLP-1, GIP, and CB1.
Ram is the passionate CEO of IGC Pharma, whose decade-long journey in medical and pharmaceutical research reflects his commitment to transforming the lives of those affected by Alzheimer's disease. Ram is driven by a heartfelt mission to develop affordable medications and identify early biomarkers.
Paola, the AI/ML team manager at IGC Pharma, is a Biomedical Engineer with a profound dedication to transforming medical care through technology. Her work involves developing innovative machine learning tools to advance the diagnosis of Alzheimer’s and related disorders.
At IGC Pharma, Nestor plays a crucial role in integrating and harmonizing extensive Alzheimer's disease-related databases. His contributions include developing and refining machine learning and deep learning models using these datasets and optimizing state-of-the-art large language models.
Daniel Crovo is a dedicated Electronics Engineer with a passion for applying artificial intelligence to medical research, focusing on early detection of Alzheimer’s disease. Currently pursuing a double master’s degree in AI/ML and Electronics Engineering, Daniel has honed his skills in developing deep learning models for medical image analysis.
Summary of approach:
Audio inspection revealed significant background noise, loudness variability, and intelligibility issues. To address these quality challenges, we implemented an audio preprocessing pipeline including stationary and dynamic noise gate reduction, equalization, dynamic range processing, and loudness normalization, significantly enhancing speech clarity and minimizing interference. Furthermore, we applied data augmentation techniques, including pitch modification, adding colored noise, and random gain adjustments, to enhance model robustness and generalization capabilities. Finally, we leveraged transfer learning with more advanced architectures, like wav2vec, HuBERT and Whisper. We performed several experiments in which we used the raw audios, text transcriptions and the provided acoustic features and implemented different modality fusion techniques, however the distilled whisper v3 model using just the raw audios produced the best results.
BrainSignsLab¶


Team members: Abhay Moghekar and Siavash Shirzadeh
Place: Special Recognition for generalizability (Acousic track)
Prize: $10,000
Hometown: Baltimore, MD
Usernames: abhaymog, SiavashShirzadeh
Social media: https://www.brainsigns.net/
Background:
Abhay is a neurologist, and Siavash is a physician and data scientist currently a post-doctoral fellow in Abhay's lab.
Summary of approach:
Audio data were standardized and downsampled to optimize feature extraction, leveraging both traditional acoustic parameters extracted via OpenSMILE's eGeMAPSv2 (e.g., MFCCs, chroma, spectral characteristics) and advanced transformer-based embeddings from Wav2Vec2 and Whisper models, combined with demographic information. A structured feature selection method identified the most informative features, preventing overfitting, followed by training an optimized XGBoost classifier validated through cross-validation to find the best performing model.
Nick and Ry¶


Team members: Nick Nettleton and Ryan Carson
Place: Explainability Bonus prize (Social Determinants of Health track)
Prize: $10,000
Hometown: London, UK and Greater Hartford, CT
Social media: Nick Nettleton, Ryan Carson
Usernames: NickNettleton, ryancarson
Background:
Nick is an independent tech, data and AI specialist. Ryan is a founder, entrepreneur, and CEO for 20 years, and currently works at Intel on Global Commercial Influencer Strategy. He is also the founder of Maple, a personal AI sales coach.
Nick and Ryan worked together at Ryan's first startup, DropSend. When Nick reached out to Ryan about this challenge, Ryan was excited to support him in it.
Summary of approach:
I experimented with lots of different algorithms and found that I was able to get the best results with a trio of gradient boosters - LGBM, XGBoost and CatBoost - and intensive hyperparameter tuning. I experimented with many different ways of organizing and preprocessing the data, but in the end found that a light touch delivered the best results.
Given the complexity of these - the model takes the means of several thousand decision trees for each prediction - I became really interested in the explainability and interpretability aspect.
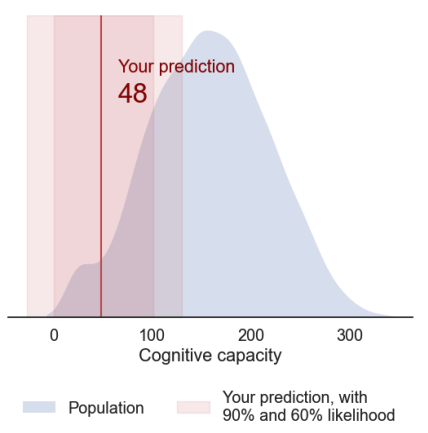
I brought Design Thinking from my studies at IDEO U to explore how to make a prediction insightful and helpful to an end user. I realized that we need to provide context, rather than a solitary number: what is my likely cognitive range, how is that prediction made, how reliable is it, how does it compare to the overall population, and what are the key factors. I experimented with a range of techniques to answer these questions, settling on MAPIE to provide a prediction range for each individual, and SHAP to explain the key factors in each case. These were brought to life in individual explainer reports with facts, figures, visual charts, and a simple language explanation of how to interpret it.
GiaPaoDawei¶
Team members: Gianpaolo Tomasi and Dawei Ye
Place: Special Recognition for feature selection (Social Determinants of Health track)
Prize: $10,000
Hometown: Padova, Italy
Usernames: giampiportatile, dxphoto
Background:
Gianpaolo has been working in finance for 12 years, trying to find patterns in the noise. Dawei is an AWS cloud architect in the Data and Security arena, who designs solutions to process big data in real or near realtime manner.
Summary of approach:
We created new features from the given set and used an ensemble of GBDT for the final forecast.
Thanks to all the challenge participants and to our winners! And thank you to the National Institute on Aging (NIA), an institute of the National Institute of Health (NIH), for sponsoring this challenge!