In April of 2015 the 7.8 magnitude Gorkha earthquake occured near the Gorkha district of Gandaki Pradesh, Nepal. Almost 9,000 lives were lost, millions of people were instantly made homeless, and \$10 billion in damages––about half of Nepal's nominal GDP––were incurred. In the years since, the Nepalese government has worked intensely to help rebuild the affected districts' infrastructures. Throughout this process, the National Planning Commission, along with Kathmandu Living Labs and the Central Bureau of Statistics, has generated
One of the largest post-disaster datasets ever collected, containing valuable information on earthquake impacts, household conditions, and socio-economic-demographic statistics.
 For more information, check out the [open data portal](https://opendata.klldev.org/#/).
For more information, check out the [open data portal](https://opendata.klldev.org/#/).
In our brand new intermediate practice competition, your goal is to predict the level of damage a building suffered as a result of the 2015 earthquake. The data comes from the 2015 Nepal Earthquake Open Data Portal, and mainly consists of information on the buildings' structure and their legal ownership. Each row in the dataset represents a specific building in the region that was hit by Gorkha earthquake.
In this post, we'll walk through a very simple first pass model for predicting earthquake damage from structural and legal data, showing you how to load the data, make some predictions, and then submit those predictions to the competition.
To get started, we import the standard tools of the trade.
%matplotlib inline
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
DATA_DIR = Path("..", "data", "final", "public")
Loading the Data¶
 Destroyed temple area in Pashupatinath.
Destroyed temple area in Pashupatinath.
On the data download page, we provide everything you need to get started:
- Training Values: These are the features you'll use to train a model. There are 38 features, including structual information such as the number of floors (before the earthquake), age of the building, and type of foundation, as well as legal information such as ownership status, building use, and the number of families who live there. Each building is identified by a unique (random)
building_id, which you can use as an index. - Training Labels: These are the labels. Every
building_idin the training values data has a corresponding label in this file. A1represents low damage, a2represents a medium amount of damage, and a3represents almost complete destruction. - Test Values: These are the features you'll use to make predictions after training a model. We don't give you the labels for these samples, it's up to you to generate predictions of the level of earthquake damage for these
building_ids! - Submission Format: This gives us the filenames and columns of our submission prediction, filled with all
1as a baseline. Your submission to the leaderboard must be in this exact form (with different prediction values, of course) in order to be scored successfully!
Since this is a benchmark, we're only going to use a subset of the features in the dataset. It's up to you to take advantage of all the information!
train_values = pd.read_csv(DATA_DIR / "train_values.csv", index_col="building_id")
train_labels = pd.read_csv(DATA_DIR / "train_labels.csv", index_col="building_id")
train_values.dtypes
Explore the Data¶
(
train_labels.damage_grade.value_counts()
.sort_index()
.plot.bar(title="Number of Buildings with Each Damage Grade")
)

selected_features = [
"foundation_type",
"area_percentage",
"height_percentage",
"count_floors_pre_eq",
"land_surface_condition",
"has_superstructure_cement_mortar_stone",
]
train_values_subset = train_values[selected_features]
A quick look at the relationships between our numeric features and labels
sns.pairplot(train_values_subset.join(train_labels), hue="damage_grade")

Pre-process the Data¶
train_values_subset = pd.get_dummies(train_values_subset)
The Error Metric – Micro F1¶
The metric for the competitions is F1 score, which balances the precision and recall of a classifier. Traditionally, the F1 score is used to evaluate performance on a binary classifier, but since we have three possible labels we will use a variant called the micro averaged F1 score.
In Python, you can easily calculate this loss using sklearn.metrics.f1_score with the keyword argument average='micro'. Here are some references that discuss the micro-averaged F1 score further:
Build the Model¶
This probably isn't your first data science competition (and if it is––welcome!), so you know as well as we do that random forests are often a good first model to try. We'll give random forests a shot here, and leave the stacked classifiers and deep learning models up to you.
Random Forest¶
In Scikit Learn, it almost couldn't be easier to grow a random forest with a fiew lines of code. We'll also show you how to throw in some mean standardization of the features and assemble it all into a pipeline.
# for preprocessing the data
from sklearn.preprocessing import StandardScaler
# the model
from sklearn.ensemble import RandomForestClassifier
# for combining the preprocess with model training
from sklearn.pipeline import make_pipeline
# for optimizing the hyperparameters of the pipeline
from sklearn.model_selection import GridSearchCV
The make_pipeline function automatically names the steps in your pipeline as a lowercase version of whatever the object name is.
pipe = make_pipeline(StandardScaler(), RandomForestClassifier(random_state=2018))
pipe
From here we can easily test a few different models using GridSearchCV.
param_grid = {
"randomforestclassifier__n_estimators": [50, 100],
"randomforestclassifier__min_samples_leaf": [1, 5],
}
gs = GridSearchCV(pipe, param_grid, cv=5)
gs.fit(train_values_subset, train_labels.values.ravel())
Take a look at the best params.
gs.best_params_
And the in-sample F1 micro score.
Note that we use the class predictions (
.predict()), not the class probabilities (.predict_proba()).
from sklearn.metrics import f1_score
in_sample_preds = gs.predict(train_values_subset)
f1_score(train_labels, in_sample_preds, average="micro")
Remember, a perfect micro F1 score would be 1, so this is not a bad start given that we have 3 classes. Let's make some predictions on the test set!
Time to Predict and Submit¶
For the F1 Micro metric, we'll be using the class predictions, not the class probabilities. Let's load up the data, process it, and see what we get on the leaderboard.
test_values = pd.read_csv(DATA_DIR / "test_values.csv", index_col="building_id")
Select the subset of features we used to train the model and create dummy variables.
test_values_subset = test_values[selected_features]
test_values_subset = pd.get_dummies(test_values_subset)
Make Predictions¶
Note that we use the class predictions, not the class probabilities.
predictions = gs.predict(test_values_subset)
Save Submission¶
We can use the column name and index from the submission format to ensure our predictions are in the form.
submission_format = pd.read_csv(
DATA_DIR / "submission_format.csv", index_col="building_id"
)
my_submission = pd.DataFrame(
data=predictions, columns=submission_format.columns, index=submission_format.index
)
my_submission.head()
my_submission.to_csv("submission.csv")
Check the head of the saved file
!head submission.csv
Submit to leaderboard¶
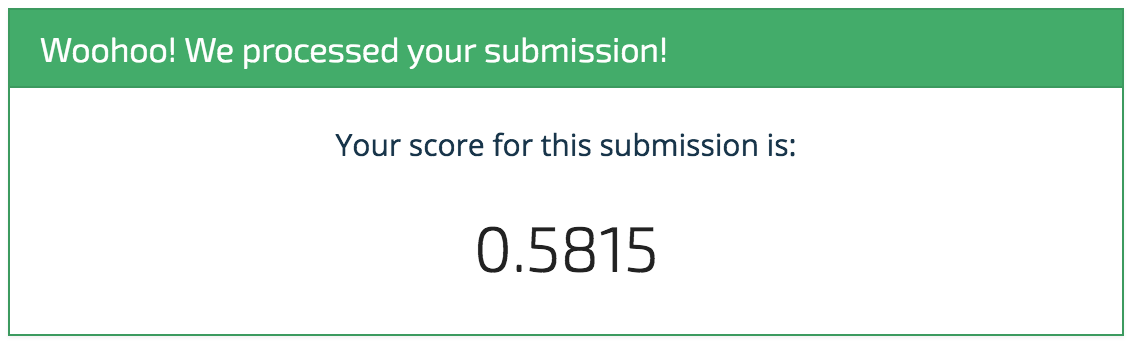
Woohoo! It's a start! And that's exactly what we intend with these benchmarks. We're sure you'll be able to top this model in no time, and we can't wait to see what you come up with. Happy importing!