The organization¶
Candid provides data and insights about the nonprofit sector. Candid tracks the flow of funding through the network of nonprofit grantmakers and recipients, making the dynamics of the social sector more visible and transparent.
The challenge¶
Candid maintains a database of millions of nonprofit organizations and ingests approximately six million public records annually that document the grants between organizations. Accurately matching entities to funding flows supports multiple Candid tools to search, visualize, and research the nonprofit space.
These tools help nonprofits identify foundations who could support their work and enables researchers to track where philanthropic dollars go. However, public records inevitably contain variations and missing data in names, addresses, and other details, creating a high risk for duplicates and missed connections.
Candid had built a legacy system which used dozens of heuristic rules to automatically determine matches, but this system was straining under the scale of data as well as the variety of data quality issues observed in public records. Candid asked us to improve the accuracy of the matching process and provide more observability into model decisions.
The approach¶
In collaboration with Candid’s Technology and Data Science teams we designed and built Orgmatch, an intelligent software tool which rapidly determines whether a given organization should be matched to an already existing organization in Candid’s databases. We analyzed Candid’s dozens of legacy heuristics and synthesized the most effective down to a small subset. We then supplemented these rules with a machine learning model trained on human-labeled matches to enable Orgmatch to learn matching patterns that extended beyond simple matching rules and which could improve as more data became available.
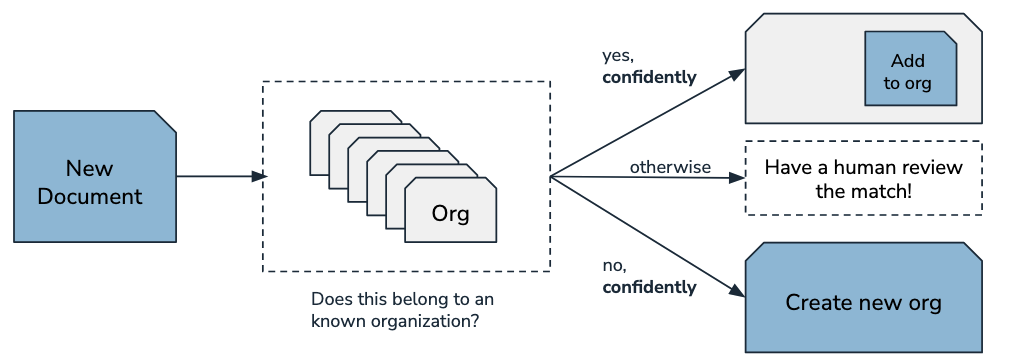
One important design consideration for Orgmatch is the cost of false positive matches. Incorrectly merging two organizations is a far worse outcome than creating a duplicate. The design of Orgmatch accounts for this error sensitivity by automating high-confidence matches and marking less certain but still confident matches for further human review. In collaboration with subject matter experts in the organization, we carefully tweaked decision policies to optimize the tradeoff between automation and human-in-the-loop checks, maximizing high quality matches while minimizing false positives.
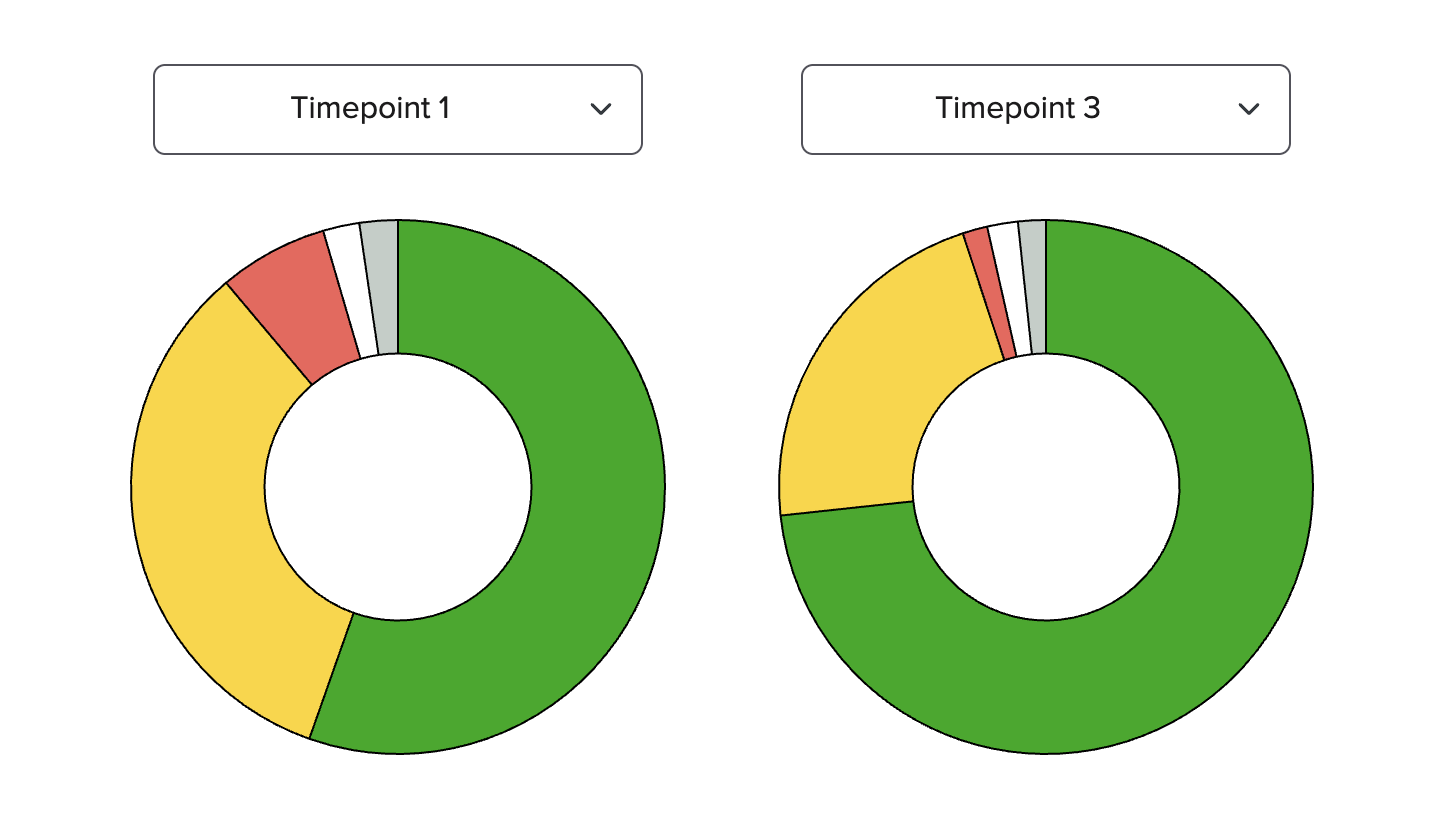
In order to observe, explain, and continuously improve on this process, we built a database to store and search all Orgmatch decisions, including the documents compared and the heuristics/model used in decision making. We built a dashboard and visualization tooling to evaluate model performance and the volume of decisions. Finally, we trained Candid’s data science team on how to maintain Orgmatch, investigate matches, and continuously improve on the process.
The results¶
DrivenData helped Candid significantly improve our entity matching algorithm, which has had a direct impact on the quality of data we provide to the social sector. Beyond the technical deliverables, they worked alongside our team to build lasting capacity in data science and AI, not just deliver a solution.
Shane Ward, VP of Data, Candid
Orgmatch processes over six million documents per year and automatically processes 98% of these documents. By implementing and improving Orgmatch, we were able to remove hundreds of thousands of matches from human review, improving data quality and saving weeks of manual review time.
Orgmatch has improved the accuracy of Candid’s database of organizations and grants. The improved database helps funders and organizations spend and raise money in more efficient, accountable ways.