DrivenData’s web deployments are supported by our friends at Heroku. This post highlights the ways Heroku underlies our Minimum Viable Process for deployments. We also recently recorded a podcast that explores this topic further including some deployed projects we’ve been working on, which you can find here.
Our Minimum Viable Process for deployments¶
At DrivenData, we operate a production platform with tens of thousands of users. We are always working on adding features and improving the software, so we often make changes to our codebase.
Of course, making changes in software can sometimes introduce bugs, and bugs are not fun. Another thing that is not a lot of fun is process, but some amount of process is necessary to prevent bugs.
Ah, the glamorous life of an engineer: making tradeoffs to balance negatives!
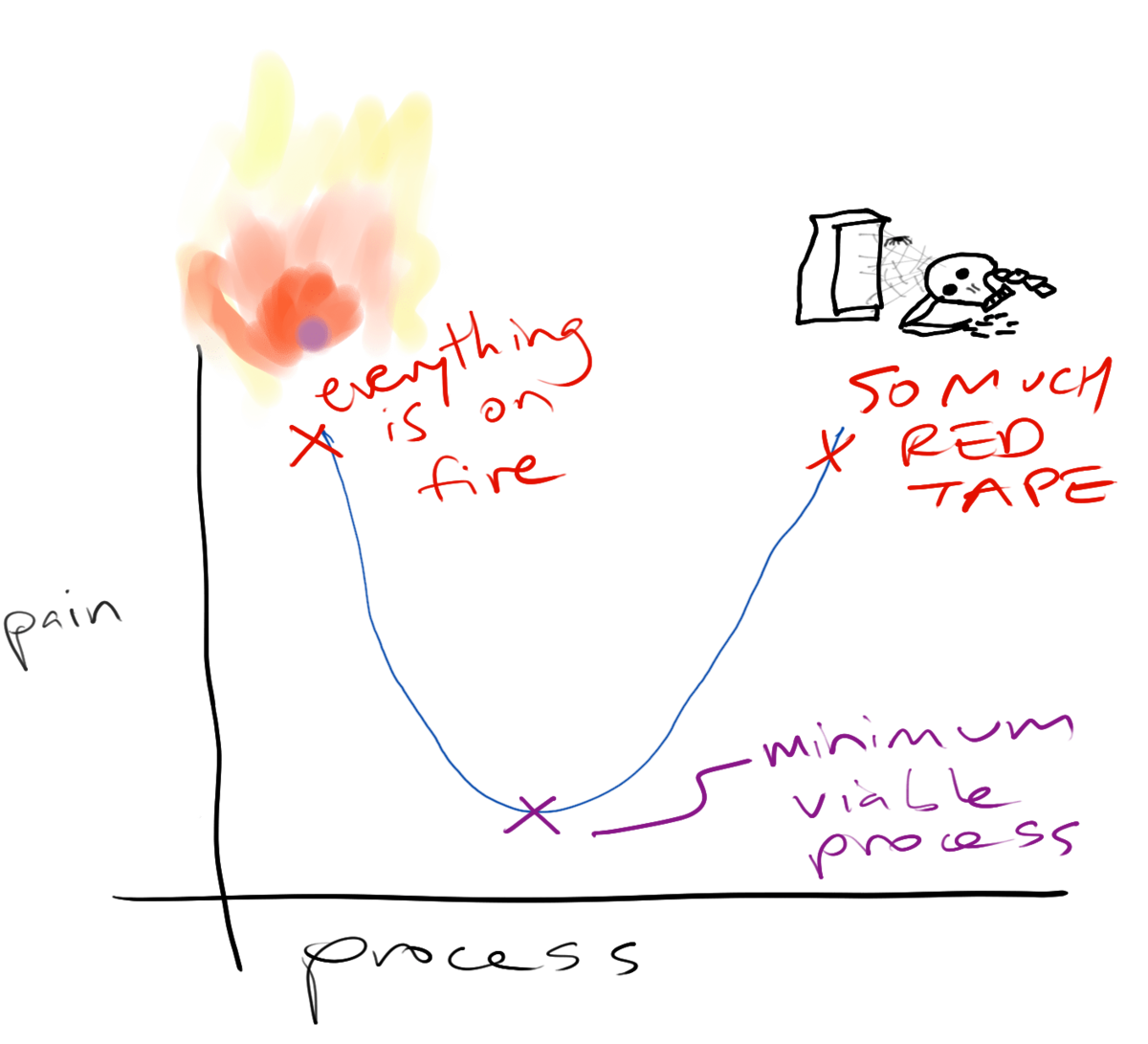
Over the years, we have gradually settled on a process for changing and releasing software that is robust enough to prevent common failure modes but lightweight enough to be minimally annoying. Here’s what it looks like when we make a change.
- Checkout a branch to work on.
- Change or write a test relevant to the change.
- Change the actual code to make the change.
- Push the named branch to our repo, open a PR against master, and assign a fellow engineer to do a code review.
- Our CI will automatically run the test suite. Any of the following conditions will fail the build:
- If the build succeeds, it will place a green checkmark on the PR. If it fails, there will be a scary red ‘x’ icon.
- If the build succeeds and was on the
masterorstagingbranch, it will get deployed to Heroku.
Let’s break this process down piece by piece.
Branching¶
We use an extremely lightweight version of feature branches. What this means in practice is that we almost never make changes without a well defined Github issue specifying the changes to be made.
When we make a new branch, we use the name to refer back to the Github issue tracking the desired change (e.g. 254-add-error-message-on-timeout).
When we open the pull request, the commit message or PR description will finish with a string like Closes #254, which automatically closes the relevant issue when merged to master.
Writing tests and code coverage¶
Though we have never dipped below 95% test coverage on our platform, a figure we take some pride in, we are not sticklers for particular code coverage numbers. Nor are we sticklers for test-driven development (TDD) in that we don’t mandate that the tests get written first.
But we are sticklers for exercising most of the plausible pathways that the code can take. It’s not great if a certain conditional in the code never gets triggered by any of the tests, and as developers we have definitely been burned in the past by assuming that a change doesn’t need a test because it’s "not that complicated."
A failing test is not a slap in the face. It’s your past self saying "you’re welcome" to your future self for preventing you from having to fix a bug in the middle of the night.
Code reviews, linting, and style¶
Ordinarily, nothing goes to the master branch without a second set of eyes — even if that review is just a gut check.
In our code review, we don’t usually have to worry about nitpicking code style because the build was already the jerk and complained if anything was off. This way, we can focus more on core concepts like security and functionality.

Unless the change is trivial, we often ask each other open ended questions such as "how would this affect [other piece of the system that is marginally concerned here but might get overlooked]" These questions aren’t gotchas, they are recognition that simple questions are often extremely important for checking assumptions.
Effective code reviews are a huge topic in their own right, and we don’t address how to do those here, but we feel strongly that not doing code reviews at all is a smell — even in data science work.
Deployment¶
We deploy our code on Heroku, and have been since the beginning of 2014. For us, it was a great way of abstracting away the machine so that we could stay focused on building the software, and our use of Heroku has scaled up as we have grown from an early alpha to tens of thousands of users.
One of the nice things about a git-based deploy workflow is that we have automated pretty much everything based on our branch strategy. For example, a passing build on our staging branch automatically deploys to our staging instance. A passing build on master automatically deploys first to staging and then production.
Not only does our CI deploy the application, but it triggers a snapshot of the database using Heroku’s PG Backups, runs any database migrations, does static asset uploads, and does a post-deploy HTTP 200 health check at the same time. These are exactly the types of action that get missed when deployment is a manual process.
This is a very boring deployment workflow. There is nothing novel about this deployment workflow. We prefer it that way.
Closing thoughts¶
One of the gratifying things about working directly with many organizations is getting to see how they work. We have worked with two-person startups all the way up to Fortune 50 companies, and the sheer variety in software development and deployment process between organizations is incredible.
There is a popular belief that all startups are nimble and older "enterprise" companies are stultifyingly slow, but the relationship between size and software practices is not always straightforward.
We have worked with new-ish startups that have a staggering amount of process: thousands of JIRA tickets in dozens of repositories, organized into epics, communicated about over email/Slack/Bitbucket and more. Meanwhile, we have worked with teams that are part of giant organizations where a tiny handful of people make ad hoc changes and carry out deployments however they feel like.
Process can be a liberating tool to reduce stress and worry, or it can be a crushing burden that makes engineers start looking for work at other companies. This is a classic case not just of diminishing returns with increasing amounts of process but also of a parabola of sadness with output vanishing as bureaucracy increases.
For our small team, we are always experimenting with ways to introduce tiny amounts of process that have an outsized impact on reducing our stress levels and making work more enjoyable. This post has only described how we actively make changes and not even scratched the surface of how we plan and prioritize work, but the same principle applies across the board.