The organization¶
ReadNet is a multidisciplinary group of cognitive science, speech, education, and data science researchers from MIT Senseable Intelligence Group, MIT Gabrieli Lab at MIT, and FSU Florida Center for Reading Research, focused on utilizing speech data to enhance early detection and prevention of reading difficulties.
The challenge¶
To provide effective early literacy intervention, teachers must be able to reliably identify the students who need support. Currently, teachers across the U.S. are tasked with administering and scoring literacy screeners, which are written or verbal tests that are manually scored following detailed rubrics. Manual scoring methods not only take time, but they may be unreliable, producing different results depending on who is scoring the test and how thoroughly they were trained.

iPad screenshots showing the view of the person administering and scoring the literacy screener.
The approach¶
DrivenData hosted a machine learning competition where competitors developed models to score audio recordings from literacy screener exercises completed by students in kindergarten through 3rd grade across four literacy tasks: deletion, blending, nonword repetition, and sentence repetition.
Participants trained models on audio clips that had been de-identified with voice cloning technology to maintain the privacy of children's voices. At the end of the competition, the top 3 teams on the leaderboard packaged up their training and inference code and their models were retrained and evaluated using the raw, non-anonymized version of the competition data to produce the final scores.
The results¶
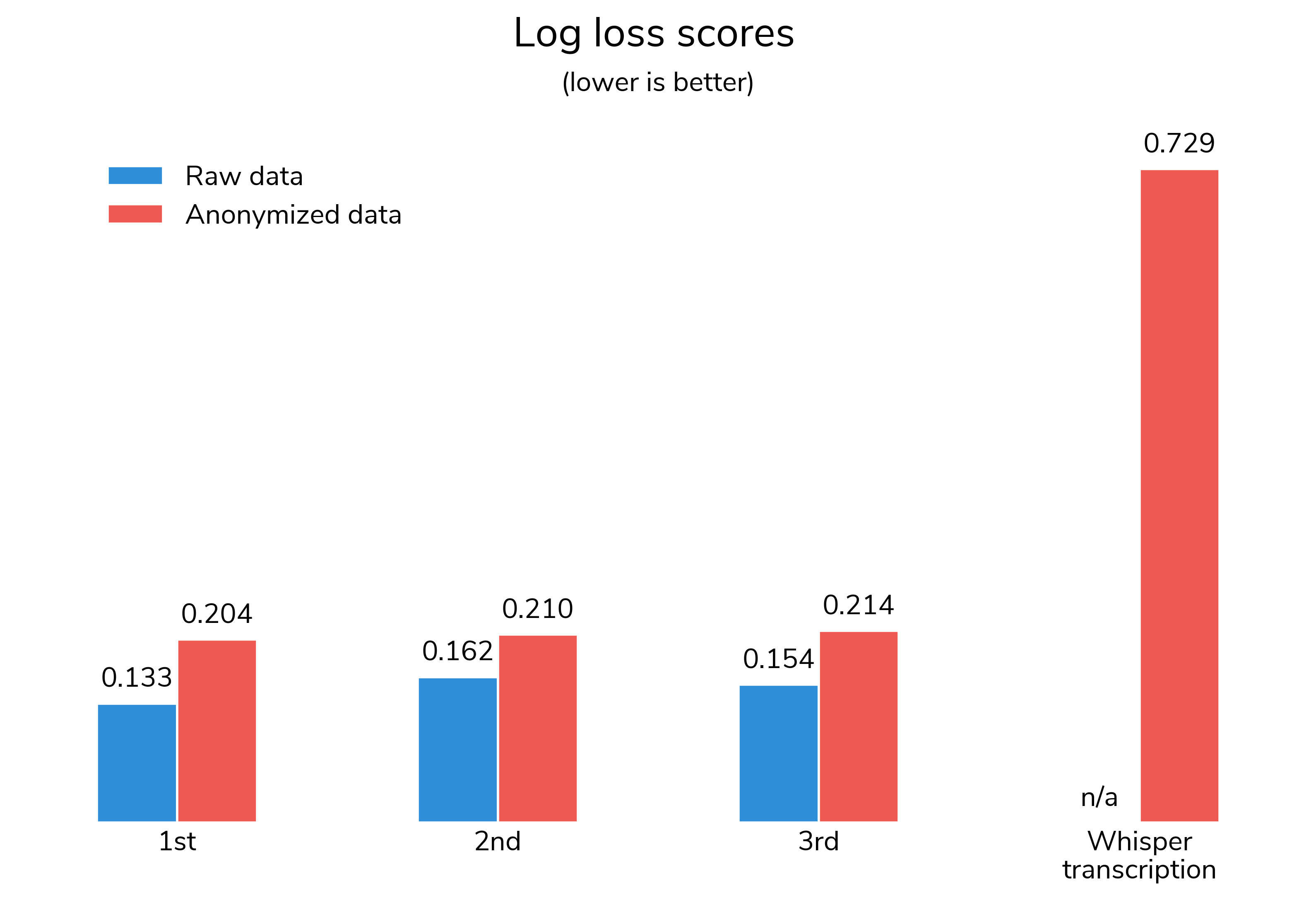
The prize-winning solutions achieved an impressive AUROC of 0.97 on the anonymized test set. Retrained raw models were even more successful and saw around a 30% improvement in log loss compared to the anonymized version. This shows that methods developed on anonymized data generalized well to the raw data, and that machine learning can be an accurate way to score child literacy screening exercises.
Code and documentation from the prize-winning submissions are available for anyone to use and learn from. You can learn more about the winners and their solutions in the Meet the Winners blog post.