

While most speech models focus on adults, this challenge focused on evaluating the speech of young children at an age at which there is significant variation across individuals. By advancing automated scoring for literacy screeners, these innovations have the potential to transform classrooms and improve outcomes for young learners.
Dr. Satrajit Ghosh, Director, Senseable Intelligence Group
Literacy—the ability to read, write, and comprehend language—is a fundamental skill that underlies personal development, academic success, career opportunities, and active participation in society. Many children in the United States need more support with their language skills. A national test of literacy in 2022 estimated that 37% of U.S. fourth graders lack basic reading skills.
To provide effective early literacy intervention, teachers must be able to reliably identify the students who need support. Currently, teachers across the U.S. are tasked with administering and scoring literacy screeners, which are written or verbal tests that are manually scored following detailed rubrics.

Manual scoring methods not only take time, but they may be unreliable, producing different results depending on who is scoring the test and how thoroughly they were trained. In contrast, machine learning approaches to score literacy assessments can help teachers quickly and reliably identify children in need of early literacy intervention. The goal of the Goodnight Moon, Hello Early Literacy Screening Challenge was to develop a model to score audio recordings from literacy screener exercises completed by students in kindergarten through 3rd grade.
The results¶
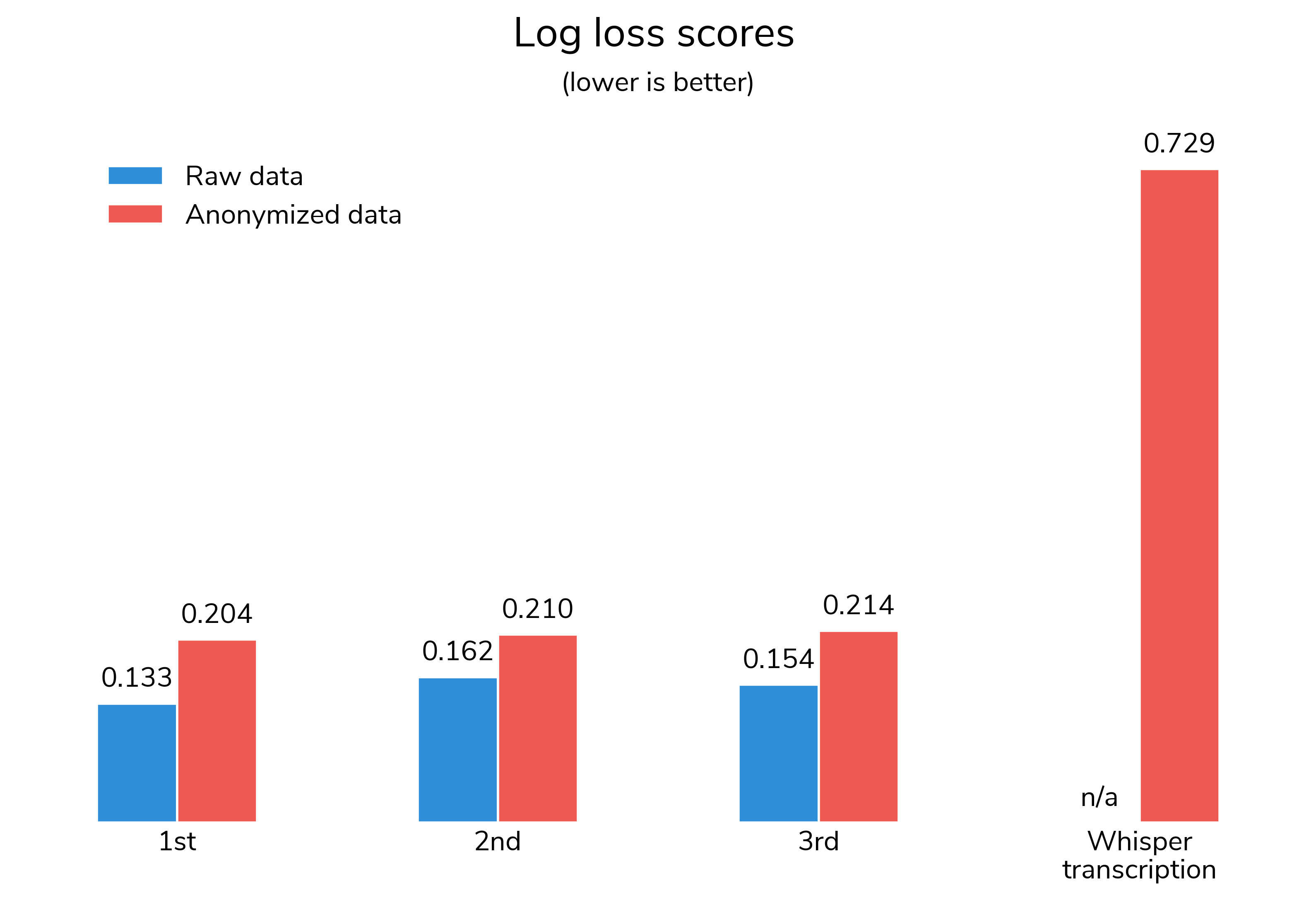
Challenge participants generated 315 submissions, and the winning solutions achieved an impressive AUROC of 0.97 on the competition test set. This was a substantial improvement over the transcription benchmark that used Whisper (a general-purpose speech recognition model from OpenAI) and had an AUROC of 0.59.
This competition was unique in that final prize rankings were determined by model performance on both an anonymized test set and a non-anonymized (raw) test set. During the competition, solvers trained models on anonymized training data to qualify for prizes. The student voices in the audio files were anonymized using voice cloning technology to produce de-identified audio files. Anonymized data was used in the competition because the audio clips contained child voices, which could not be shared. At the end of the competition, the top 3 teams on the private leaderboard packaged up their training and inference code and their models were then retrained on the raw, non-anonymized training data and then evaluated on the raw, non-anonymized test set. Final scores were a weighted average of the anonymized test set score from the private competition leaderboard (70%) and the raw test set score produced by the model retrained on raw data (30%).
Raw models saw around a 30% improvement in log loss compared to the anonymized version. This shows that methods developed on anonymized data generalized well to the raw data and that machine learning can be an accurate way to score child literacy screening exercises.
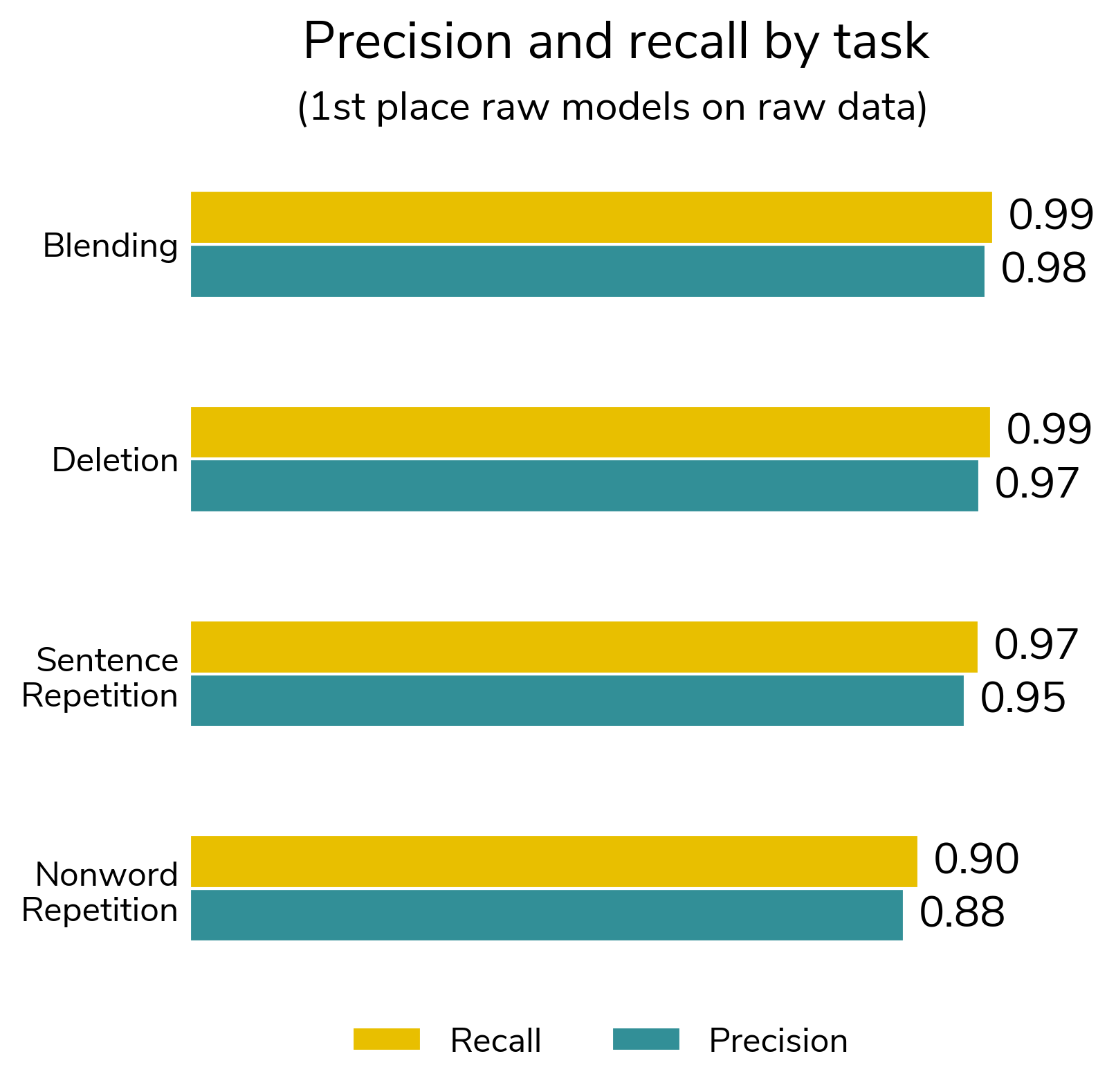
There were four types of literacy exercises (task) in the challenge data. These include:
- Deletion: Delete an identified portion of a word and say the target word after the omission, e.g., "birdhouse without bird"
- Blending: Combine portions of a word and say the target word out loud, e.g., "foot - ball"
- Nonword repetition: Repeat nonwords of increasing complexity, e.g., "guhchahdurnam"
- Sentence repetition: Repeat sentences of varying length and complexities without changing the sentence’s structure or meaning, e.g., "The girls are playing in the park"
Models performed the best on the "blending" task and worst on the "nonword repetition" task. Nonword repetition was expected to be the hardest task for machine learning models since nonsense words are typically not included in the training data for general purpose speech detection models.
Still, precision and recall scores were impressively high across the board and reinforce the applicability of machine learning approaches to automated scoring of literacy screeners.
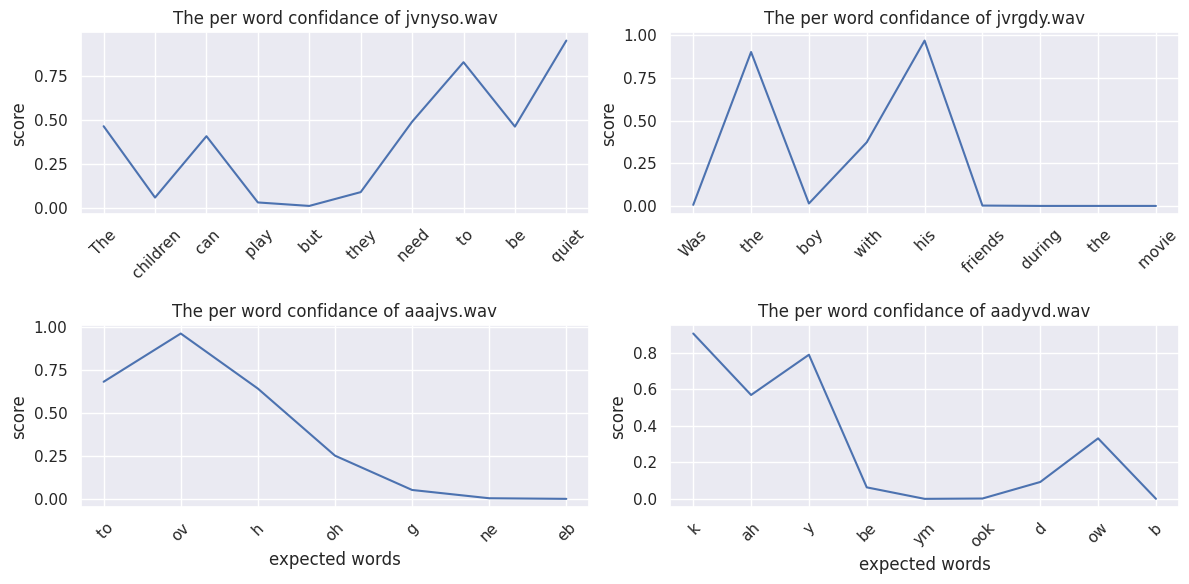
This competition also included a bonus prize for explainability write-ups that describe methods to determine where in the audio stream error(s) occur and provide insight into the model decision-making rationale. For example, the 1st place bonus prize winner demonstrated how token-level logits can be interpreted as confidence scores for words or sounds and can be used to pinpoint mispronunciations.
All winning solution code and reports can be found in the winners repository on GitHub. All solutions are licensed under the open-source MIT license.
Meet the winners¶
| Prize | Overall | Explainability bonus |
|---|---|---|
| 1st Place | sheep | sheep |
| 2nd Place | dylanliu | dylanliu |
| 3rd Place | vecxoz |
Yang Xu¶

Place: 1st place overall + 1st place explainability bonus
Prize: $15,000
Hometown: LiShui, ZheJiang, China
Username: sheep
Social media: https://www.kaggle.com/steamedsheep
Background:
I am an experienced data engineer and work in bioinformatic and computer vision field. I join many data science competitions at both DrivenData and Kaggle, with a Kaggle GrandMaster tie.
What motivated you to compete in this challenge?
First I am interested in both audio and multimodal problems, the emergence of OpenAI’s Whisper provides a good opportunity to solve this kind of problem. Then the dataset of this challenge is well annotated and clean, only few have wrong labels. This makes this challenge a good benchmark for audio-text matching.
Summary of approach:
We fine-tune OpenAI’s Whisper model with a custom loss function. For each word in expected_text, we input its token into the decoder and compute the binary cross-entropy (BCE) loss between the token’s logit and its corresponding score. This approach enables us to evaluate the correctness of each word in a weakly supervised manner.
Check out Yang's full write-up, solution, and explainability submission in the challenge winners repository.
Xindi Liu¶

Place: 2nd place overall + 2nd place explainability bonus
Prize: $10,000
Hometown: Huaibei City, Anhui Province, China
Username: dylanliu
Social media: https://www.kaggle.com/dylanliuofficial
Background:
I’m a freelance programmer (AI related) with 7 years of experience. One of my main incomes now is prizes from data science competitions.
Summary of approach:
At first, I treated this task as a multimodal (speech and text) classification task. I tried to use a speech feature extraction model and a text feature extraction model to extract the features of speech and text respectively, and then used a classifier for binary classification. After trying different models, I chose whisper-medium (only the encoder part) as the speech feature extraction model and bge-large as the text feature extraction model.
I spent some time thinking about the room for improvement: text information has no pronunciation details, how to get the accurate pronunciation of text? I thought of using a text-to-speech (TTS) model to convert text into standard speech, and then compare it with speech data. I used the EN_NEWEST model of MeloTTS to generate standard speech, and then trained a model with it according to the previous method.
In my experience, putting all the information in one model input works best. So I tried combining the speech data and the standard speech into a new unified language input, and treated this task as a speech binary classification task. This solution achieved a cv score of ~0.24. I then tried different data augmentations, which only slightly affected the cv score, reducing it by ~0.01.
In the end, I combined the 10 models from the previously trained models and used a cv-based weight searching script to automatically search for weights. Due to the limitation of inference time, each model only used half of it’s folds, thus forming the final submission.
Check out Xindi's full write-up, solution, and explainability submission in the challenge winners repository.
Igor Ivanov¶

Place: 3rd place
Prize: $5,000
Hometown: Dnipro, Ukraine
Username: vecxoz
Background:
I'm a deep learning engineer from Dnipro, Ukraine. I specialize in CV and NLP and work at a small local startup.
Summary of approach:
My approach is based on the PyTorch and Huggingface Transformers. I used 4 modalities of the data each of which brings significant improvement for the model:
- original audio
- audio generated from expected text (by SpeechT5)
- original expected text
- text transcribed from original audio (by Whisper finetuned on positive examples)
To process these 4 components I built a multimodal classifier which uses the encoder from the finetuned Whisper model as audio feature extractor and Deberta-v3 as text feature extractor. My best final submission is an ensemble of 6 multimodal classifiers each of which uses microsoft/deberta-v3-base and different versions of Whisper.
What are some other things you tried that didn’t necessarily make it into the final workflow:
I tried the following modifications without improvement:
- Add another audio feature extractor (
Wav2Vec2) - Add image model (
EfficientNet-B7) as audio feature extractor based on mel-spectrograms - Replace text feature extractor with:
mDeberta(multilingual),Bert,Roberta,XLM-Roberta(multilingual),SentenceTransformer. - Given that Whisper accepts a fixed sampling rate of 16 kHz, I tried to resample audio into other sampling rates which effectively makes speech slower or faster: 8 kHz, 24 kHz, 32 hHz.
- In the final submission I generated speech from expected text using a single female voice (i.e. the same speaker embedding), but I also tried to generate a different voice for each example without improvement.
Check out Igor's full write-up and solution in the challenge winners repository.
Thanks to all the challenge participants and to our winners! Special thanks to the MIT Senseable Intelligence Group, MIT Gabrieli Lab, and FSU Florida Center for Reading Research for enabling this important and interesting challenge and for providing the data to make it possible!



















