
Organizations run AI competitions for a variety of reasons. They want to engage the expertise of a global community. They want to push the limits of available methods for their needs. They want to explore innovative approaches and surface new ideas. They want to benchmark the level of performance that can be achieved with their data.
At the end of a competition, these organizations get a few things:
- Winning solutions, consisting of research code in a Github repository and often shared openly for ongoing learning and development
- An understanding of the most effective approaches and measurement of what's possible
- Recognition of top teams and their accomplishments, for instance through the leaderboard and winners announcement)
- A well-structured use case for ongoing reference, shared on the challenge website and in materials like benchmark tutorials), and sometimes accompanied by open data

But what happens next?
This is the part that is often unseen by the very community of participants that help power the solutions. For the most part, competitions are research and development. They aim to accelerate the process of developing solutions at a fraction of the cost. Like any R&D project, the answer is sometimes that nothing else happens. Often, though, the results are carried forward beyond the competition.
This part can take time to play out. At this point we've been running competitions for over a decade, so we wanted to take this chance to pull up on some of the things we've seen.
In this post, we'll share a few examples of what happens after competitions end. Let's take a look!

Model deployment and use¶
This is the biggest category. In many cases, the winning solutions from competitions feed directly into deployed models for use.
In some of these cases, competitions partners carry forward the winning solutions themselves. For example:
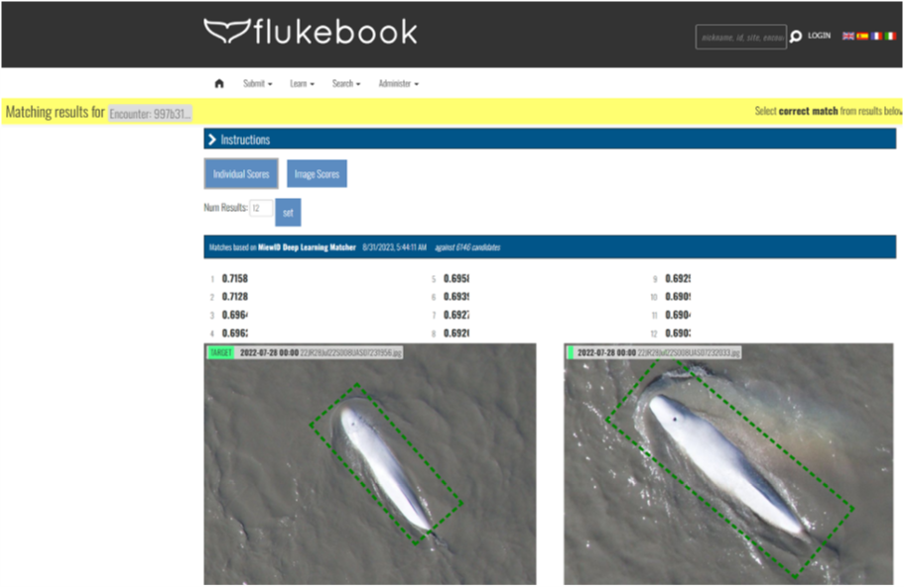
In the Where's Whale-do? competition, winning solutions used deep learning approaches from facial recognition tasks (particularly ArcFace and EfficientNet) to help the Bureau of Ocean and Energy Management and NOAA Fisheries monitor endangered populations of beluga whales by matching overhead photos with known individuals.
The challenge partners at Wild Me (now part of Conservation X Labs) worked with the winning solution not only to deploy the technology through their Wildbook Flukebook platform for monitoring belugas, but also found success extending the approach to other types of wildlife like dolphins and lions.
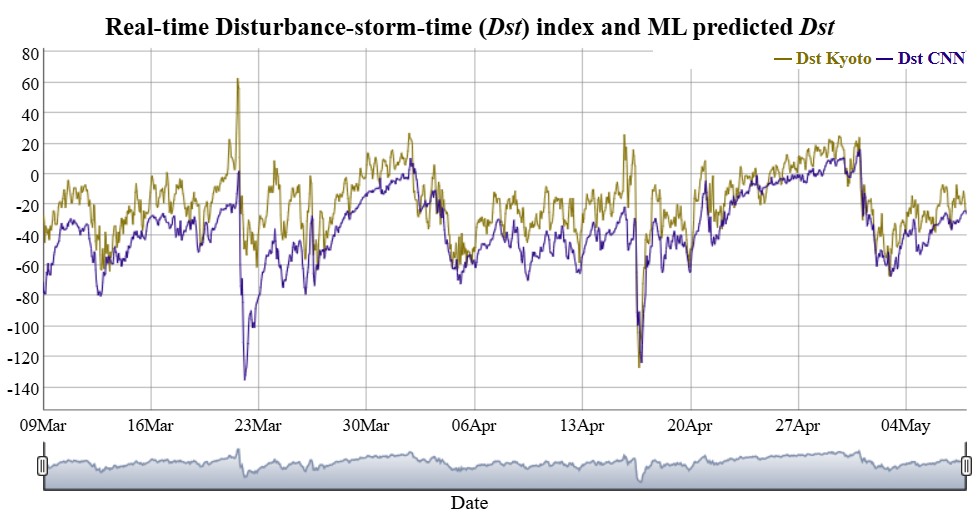
In the MagNet competition, top solutions used Convolutional Neural Networks (CNNs) with other approaches to forecast disturbances in Earth's geomagnetic field from geomagnetic storms. These disturbances can wreak havoc on key infrastructure systems like GPS, satellite communication, and electric power transmission. An ensemble of the top solutions was able to push the state-of-the-art on unseen data, reducing error by 30% compared with the National Centers for Environmental Information (NCEI) benchmark model.
After the challenge, the research team at NOAA and NCEI worked with one of the winners to implement an ensemble of the top two models, incorporating into NOAA's High Definition Geomagnetic Model (HDGM) and making the predictions publicly available in real-time. The challenge and results were also published in the AGU Space Weather journal and was among their top 10% of viewed articles published in 2023.
In the Pose Bowl competition, winning solutions explored ways to implement object detection algorithms on limited hardware for use in space. As part of the setup, code submissions were run on resources that simulated the constraints of the production environment on a NASA R5 spacecraft. The competition was part of a broader effort to provide safe, low-cost methods of assessing and potentially repairing damaged ships in space using an inspector spacecraft. Following the competition, NASA integrated the 2nd place object-detection solution onto a CubeSat running in realtime.

In other cases, our technical team works with partners to carry forward solutions so they are ready for use. For example:
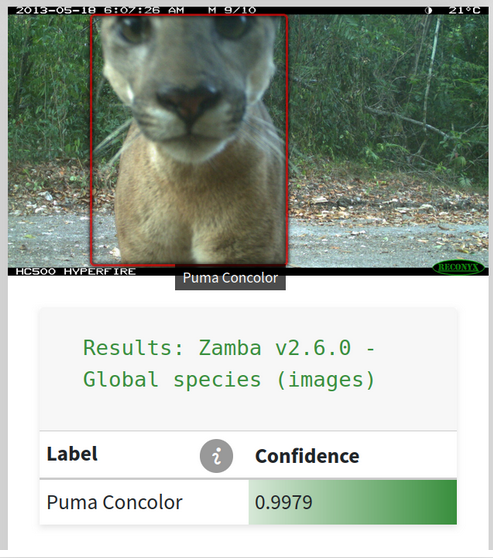
In the Pri-matrix Factorization challenge, the best solution was able to identify wildlife in camera trap footage with over 95% accuracy. Following the competition, DrivenData worked with the winner and partners at the Max Planck Institute for Evolutionary Anthropology, the Wild Chimpanzee Foundation, and WILDLABS to simplify and adapt the top model in an open source Python package and no-code web application for monitoring wildlife. The application now has over 350 users and has processed more than a million images and videos.
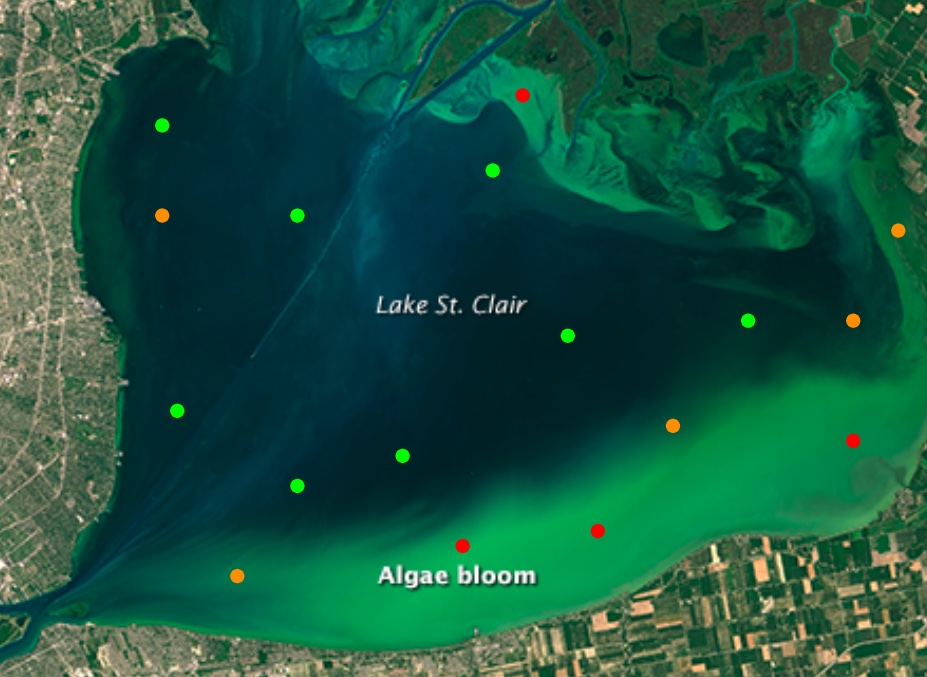
In the Tick Tick Bloom challenge, winning solutions used satellite imagery to detect dangerous concentrations of cyanobacteria, a type of harmful algal bloom, in small inland lakes and reservoirs. After the challenge, our team worked with NASA and users monitoring public health at state agencies to develop CyFi (Cyanobacteria Finder), a command line tool that streamlined winning algorithms and makes it easy to generate cyanobacteria estimates for new data. The resulting tool makes state-of-the-art machine learning available to water quality managers, achieves better results than existing tools with 10x more coverage, and was published in SciPy Proceedings in 2024.
Proof of concept for investment¶
Sometimes, the results of a competition serve as a demonstration of what's possible with current technology, even if the solutions themselves are not the ones getting directly implemented. This demonstration is used to make the case for further investing in developing new solutions.
This is a pattern we've seen come up again and again. For example:
In the N+1 Fish, N+2 Fish challenge, winning solutions used computer vision techniques to count, measure, and identify fish caught by fishing vessels. The goal of these algorithms is to begin reducing the burden of human video review in helping sustainable fisheries monitor their catch.
The results of the competition fed into OpenEM, an open source library for electronic monitoring. Above all, the challenge successfully showed that computer vision approaches were ready to help with accurate electronic monitoring - not in 10 years, but today. This led to increased investment by companies in this space along with our partner at The Nature Conservancy, such as through work with AWS among others.

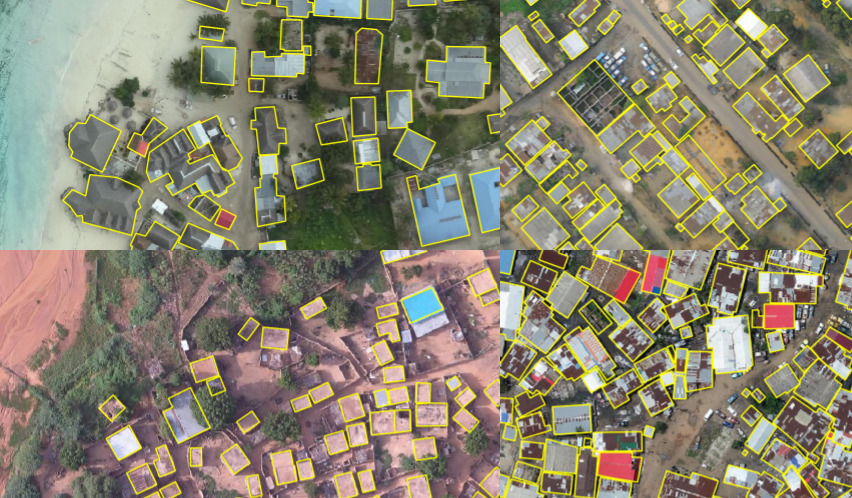
In the Open Cities AI Challenge, winning solutions worked with drone imagery to map building footprints in support of disaster risk management efforts in urban settings across Africa. Afterwards, the challenge training data was combined with other data to develop an open-source deep learning model to extract building footprints against satellite imagery. The project, called Ramp, partnered with the World Health Organization (WHO) to deploy the model in support of emergency response scenarios.
The participatory data approach from the challenge (for instance, through initiatives like OpenStreetMap and OpenAerialMap), also served as an example to build out other labelled data in a range of projects, such as those in the World Bank's digital public works initiative.
Benchmark data for assessing and demonstrating tools¶
For many challenges, considerable effort goes into bringing together a well-annotated dataset, clearly structured use case, and effective metrics for evaluating solutions. The resulting competition package is useful beyond the immediate solutions developed during the challenge. It often serves as an ongoing reference to benchmark and demonstrate development efforts in the broader ML/AI ecosystem.
For instance, the Differential Privacy Temporal Map Challenge featured a series of three challenge sprints, each with a set of data and metrics designed to test algorithmic approaches for maximizing the utility of a dataset while protecting individual privacy. The challenge partners at the National Institute of Standards and Technology (NIST) and Knexus Research built two of these sprints into SDNist, a set of benchmark data and evaluation metrics for deidentified data generators. The python package includes a report tool for summarizing the performance of a generated deidentified dataset across utility and privacy metrics.

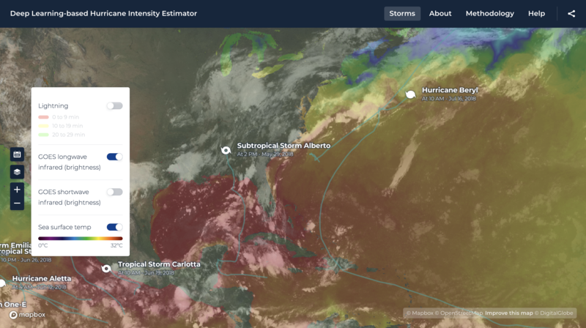
As another example, several different challenges have been included as benchmark datasets for TorchGeo, a PyTorch domain library for geospatial data. Wind-dependent Variables was an early demonstration example as the library was getting started, alongside the benchmarking work of the NASA IMPACT team to test and eventually host the winning CNN model on its website to estimate hurricane intensity. Even more recently, the dataset has been used to evaluate TorchGeo's pretrained models, which are available as starting points for many different geospatial tasks. The package also features datasets from The BioMassters and Cloud Cover Detection competitions.
Research advancement¶
In many cases, competitions represent an opportunity to push forward state-of-the-art research and accelerate what can be achieved and learned in a short amount of time. The results are often well-suited for research publication and supporting ongoing advancement after the challenge ends.
For example, following the Hateful Memes challenge, the research team at Meta AI published the results in the Proceedings of Machine Learning Research and discussed them at NeurIPS 2020. Challenge participants also published their individual approaches. The winning approach provided a relatively early demonstration of the effectiveness of using multimodal transformers for tasks involving text and images.

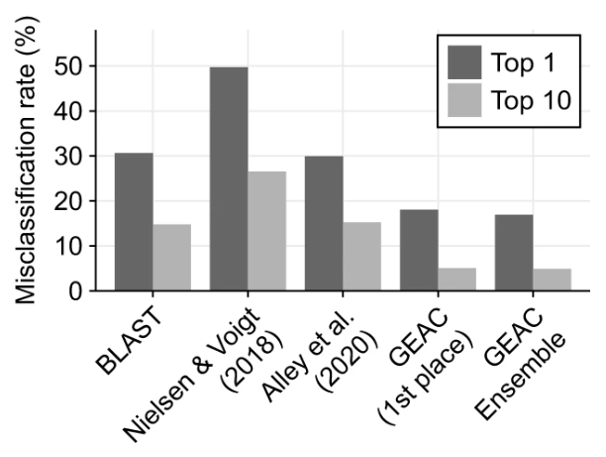
Another example is the Genetic Engineering Attribution Challenge, a first-of-its-kind competition where participants built tools to help trace genetically engineered DNA back to its lab-of-origin. The winning solutions drastically outperformed previous models at identifying true labs-of-origin. An analysis of the results was published in Nature Communications in 2022, highlighting the impressive performance and techniques used to push forward the state-of-the-art in this domain.
Talent discovery¶
Competitions are often used not only to advance solutions, but also as a way to engage a wide talent pool with a problem and elevate strong performers. In some cases, this helps participants demonstrate their skills at their current organizations or in job interviews. In others, it has translated directly into being discovered for a new career.
For example, in the Pover-T Tests competition, participants built machine learning models to identify the strongest predictors of poverty using detailed household survey records. As part of the contest, the World Bank offered a bonus award to the top contributor from a developing country. The list including 84 qualifying countries from the World Bank's classification of low-income and lower-middle-income economies.
The winner was Aiven Solatorio, a data scientist from the Philippines, who finished 5th on the leaderboard from among 2,300 participants and 6,000 submissions. Following the competition, Aiven was hired by the World Bank's development data group behind the challenge, where he has now been working for seven years.

Conclusion¶
Competitions may end when the leaderboard locks, but their influence does not. Winning code may evolve into a production model, a published paper, or an open-source tool. Even when a solution isn’t deployed immediately, the knowledge gained, the data curated, and the people engaged all contribute to the greater momentum of progress.
It's worth noting that, while extension of a competition can depend on the results, there are also a few ways that partners and participants can support ongoing development. For example:
- Organizing and documenting winning solutions so they are easy to understand, reproduce, and build upon
- Making a plan around the competition so that if it yields strong results, there is a path to carry them forward or write them up for research
- Incorporating realistic code constraints on submissions to help select for the best viable performance, if relevant
- Where possible, sharing the solutions and competition data openly for ongoing development and learning
The competition examples here represent a snapshot in time. The effects from competitions often take years to play out, and it takes effort to track them down. This is worth doing every once in a while, though, because ultimately this is one of the primary reasons to run competitions in the first place.
With a well-crafted challenge, a fantastic community, and a little luck, there are many ways solutions can take on life beyond the leaderboard.


















