


Suicide is one of the leading causes of death in the United States for 5-24 year-olds. Researchers and policymakers study the circumstances of youth suicides to better understand them and reduce their occurrence. One key source of information is the National Violent Death Reporting System (NVDRS). The NVDRS captures information about violent deaths across the United States that has been abstracted from sources including law enforcement reports, coroner/medical examiner reports, toxicology reports, and death certificates. The NVDRS contains narrative summaries drawing from those sources as well as standard variables that are useful to researchers.
The goal of the Youth Mental Health Narratives Challenge was to improve the quality and coverage of the standard variables in the NVDRS. In the Automated Abstraction track, participants submitted code to ingest NVDRS narratives and predict 23 standard NVDRS variables. Winners were selected on the basis of multi-variable average F1-score across all variables.
In the Novel Variables track, solvers explored narratives in the NVDRS data and identified new standard variables that could advance youth mental health research. Winners were selected by a panel of expert judges on the basis of technical novelty, subject matter insight, methodological rigor, and communication.
This blog post discusses circumstances of youth suicide, which can be upsetting and difficult to discuss.
If you or someone you know is struggling with mental health, you can call or text the 988 Suicide & Crisis Lifeline for 24/7, free, and confidential support. The 988 Lifeline website has additional advice and links to specialized resources.
The Results¶
Over 750 participants joined the challenge. Participants represented a great variety of backgrounds. Most solvers were data science professionals, professors, and students, but there were also many data analysts, project managers, and people working in public health and healthcare. In the quantitative Automated Abstraction track, there were 588 participants and 1,598 submitted solutions. In the Novel Variables, there were 372 participants, 31 midpoint submissions, and 24 final submissions.
Below are a few takeaways from the winning submissions:
All winning solutions relied primarily on general-text large language models (LLMs). Winners used LLMs for a variety of tasks, as shown below. All of the models used are general language models, rather than domain-specific models trained to work well on medical or legal text. This suggests that while narratives are derived from technical coroner and legal reports, they are still similar to everyday language. In the Automated Abstraction track, all winners used LLMs for fine-tuning and inference. 3rd and 4th place also used LLMs to generate more training data to augment the provided narratives.
| Task | Pretrained LLMs used |
|---|---|
| Fine-tuning and inference | BigBird, Longformer, DeBERTa, Gemma, Llama, Qwen |
| Data generation & augmentation | Qwen, Mistral, Llama, Phi, Yi |
| Segmentation & classification | FLAN-T5, Llama |
| Sentence embedding | RoBERTa |
| Topic modeling | BERTopic, SBERT |
| Summarization | Llama |
LLMs with sophisticated attention mechanisms may have helped parse long narratives. One challenge for participants was managing the context window limits for LLMs. Two of the most common models used by the winners, DeBERTa and Longformer, have specialized "attention mechanisms" that may have helped identify and focus on the relevant part of a narrative for each variable.
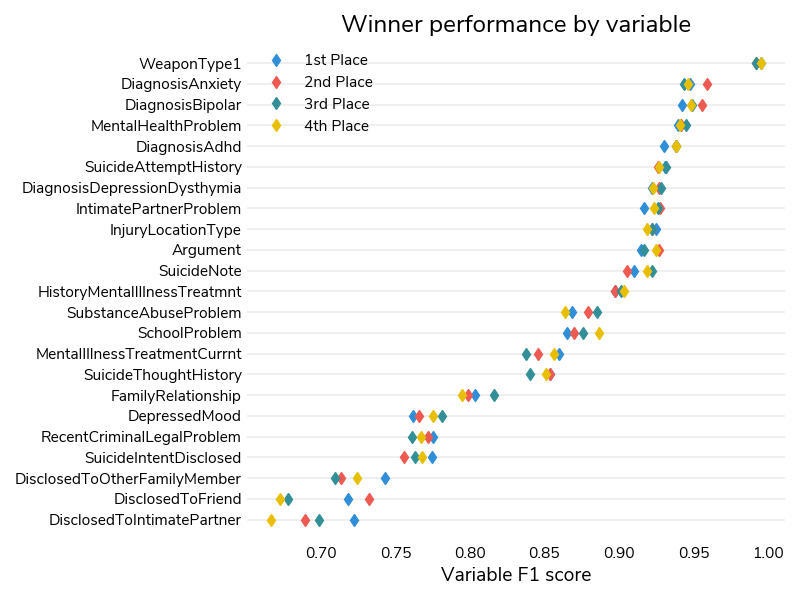
In the Automated Abstraction track, the most difficult variables to predict required understanding of word usage context. These variables tracked disclosure of suicide intent to specific groups (family member, friend, and intimate partner). Prediction required not only detecting mention of the group, but also determining whether it was mentioned in the context of disclosure, rather than last contact, an argument, or another reason. The easiest variables could be more confidently identified based solely on the mention of keywords, and included weapon type used and diagnoses of anxiety, bipolar, and ADHD.
In the Novel Variables track, many suggested variables related to modern factors like internet use, social media, and video games. Participants often focused on influences that have become more relevant to youth mental health in recent years. Other common topics were:
- Gender and sexuality
- Sleep
- Military experience
- Religion
- Direct measures of concepts related to theories of suicide, such as belongingness, rejection, impulsivity, and community
Winner overview¶
Automated Abstraction winners:
| Prize | Winner | F1 Score |
|---|---|---|
| 1st Place | kbrodt | 0.8660 |
| 2nd Place | D and T | 0.8650 |
| 3rd Place | dylanliu | 0.8636 |
| 4th Place | bbb88 | 0.8624 |
Novel Variables winners:
| Prize | Winner | Summary |
|---|---|---|
| 1st Place | verto | Extracted temporal information to determine preceding events and create a time series leading up to a suicide |
| 2nd Place | HealthHackers | Identified common concepts often mentioned in the narratives, but not yet tracked in the standard variables |
| 3rd Place | UM-ATLAS | Studied different types of online engagement that indicate non-normative behavior |
Novel Variables midpoint bonus prizes were awarded to Jackson5, who identified panic attacks, and MPWARE, who detected inconsistency between law enforcement and coroner report narratives. All three final winners also received midpoint bonus prizes.
All winning solution code and reports can be found in the winners repository on GitHub. All solutions are licensed under the open-source MIT license.
Meet the Winners from the Automated Abstraction Track¶
Kirill Brodt¶

Place: 1st
Prize: $18,000
Hometown: Almaty, Kazakhstan
Username: kbrodt
Social Media: https://github.com/kbrodt
Background:
I am doing research at the University of Montreal in the field of computer graphics. Before I received my master's degree in mathematics from Novosibirsk State University in Russia. Recently, I became interested in machine learning, so I was enrolled in the Yandex School of Data Analysis and Computer Science Center. Machine learning is my passion and I often participate in competitions.
Summary of approach:
We addressed a multilabel text classification problem for long documents using BigBird and Longformer models. Fine-tuning employed the symmetric Lovász loss, with binary cross-entropy and focal losses yielding comparable performance. We trained with a learning rate of 1e-5, a linear scheduler with 2 warmup epochs, batch sizes of 4 (BigBird) and 2 (Longformer) per GPU, and for 200 and 400 epochs, respectively. Optimal thresholds were determined for each binary variable, and a 5-fold ensemble improved generalization.
Check out Kirill's full write-up and solution in the challenge winners repository.
D and T¶


Team members: Tuan Dung Le, Thanh Duong
Place: 2nd
Prize: $13,000
Hometown: Vietnam
Usernames: dzunglt24, tronid777
Social Media: /in/tuan-dung-le-676841190/, /in/thanh-duong-2b6400156/
Background:
- Tuan Dung Le is currently a PhD student in Computer Science at University of South Florida. His research focuses on applying natural language processing techniques to extract information from unstructured clinical and medical texts, especially in low-resource settings.
- Thanh Duong is currently pursuing a PhD in Computer Science at the University of South Florida,. His research focuses on the application of language models to medication-related tasks, particularly in processing electronic health records (EHRs).
Summary of approach:
We proposed using prompt-based finetuning to tackle the problem. We created prompt templates based on variable descriptions. For example: Depress Mood [MASK] Current Mental Illness Treatment [MASK] … [MASK]. NarrativeLE +NarrativeCME.
The model is trained to predict "yes" or "no" tokens for the [MASK] positions by optimizing the masked language modeling (MLM) objective. The difference between the logits for "yes" and "no" at each [MASK] position is used as the score. A threshold of 0 is applied to classify predictions as "yes" or "no".
Check out D and T's full write-up and solution in the challenge winners repository.
Xindi Liu¶

Place: 3rd
Prize: $9,000
Hometown: Huaibei City, Anhui Province, China
Username: dylanliu
Background:
I’m a freelance programmer (AI related) with 7 years of experience. I love participating in various competitions involving deep learning, especially tasks involving natural language processing or LLMs.
Summary of approach:
At first, I saw that there were only 4000 samples. To increase the amount of data, I tried to generate data using some LLMs in a few-shot way. I generated unlabeled data for semi-supervised learning with Deberta-v3, then the Deberta-v3-large model was used to predict soft labels for the unlabeled data. The semi-supervised learning was repeated using the gemma2-9b model as the soft labeling model.
20000 pieces of data (including official data) were used for training the final model. Finally, 2 more gemma2-9b models and 1 gemma2-2b model with different lora parameters were trained and combined with the final model in the weighted way.
Check out Xindi's full write-up and solution in the challenge winners repository.
bbb88¶
Place: 4th
Prize: $5,000
Hometown: China
Username: legend
What were the most impactful parts of your code?
Enable Lora to save memory and disk:
if args.use_lora:
target_module = find_all_linear_names(args, model)
model = FastLanguageModel.get_peft_model(...)
Enable unsloth to save about half computing:
if args.use_unsloth:
model, tokenizer = load_unsloth_model(args, model_id)
Check out bbb88's full write-up and solution in the challenge winners repository.
Meet the Winners from the Novel Variables Track¶
verto¶



Team members: Hossein Yousefi, Issac Chan, and Cho Yin Yong
Place: 1st and a midpoint bonus
Prize total: $11,000
Hometown: Toronto, Canada
Usernames: hosseinyousefii,ichan_verto, cyong
Social Media: /in/choyin, /in/hossein-yousefi-55364729b, /in/sik-hin-chan-b70b74195
Background:
- Hossein Yousefi is a machine learning engineer with a focus on NLP and time series forecasting at Verto Health since January 2023. His journey in AI began in 2015 with a master's in computer vision for biomedical image analysis.
- Issac Chan is a Machine Learning Engineer at Verto where he leverages advanced machine learning techniques to create impactful healthcare solutions. He holds a Master of Philosophy (M.Phil.) in Mechanical and Automation Engineering, with a research focus on unsupervised learning and representation learning.
- Cho Yin Yong is an Engineering Manager at Verto Health and a sessional lecturer at University of Toronto teaching undergraduate Software Engineering courses. At Verto, he leads research and development on population health analytics.
What motivated you to compete in this challenge?
Patient stories are rarely documented as part of their medical chart (Rimkeviciene et al., 2016) yet “About half of people who die by suicide visit their primary care provider (PCP) within 1 month of doing so, compared with fewer than 1 in 5 contacting specialty mental health.” (Dueweke and Bridges, 2018) To better guide suicide prevention, we must first understand the series of events that victims go through in the days, weeks, or even months prior to death.
Summary of approach:
First, we identified 3200 narratives with temporal information using string matching on words like "month", "day", and "ago". We used sequential Q&A through 3 flan-t5-xl prompts to segment the narrative into sentences and construct a structured temporal concept like {'number': '1', 'unit': 'hour', 'before_or_after': 'before'}. We used topic modeling at the sentence level to classify sentences into categories based on the existing structured variables.
Next, each free-text temporal variable was reformatted into an integer representing the relative hours prior to death. For example, “2 days ago” is reformatted into -48 (hours) and “2 months prior” is -1460 (hours).
Finally, we aggregated timelines per victim and constructed a Sankey diagram, where each node represents a significant event, such as relationship problem, suicide attempt. The transitions contain the median time to move to the next state, as well as the count of patients that moved to the next state.

Check out verto's final submission and solution code in the challenge winners repository.
HealthHackers¶



Team members: Lasantha Ranwala, Dinuja Willigoda Liyanage, Benjamin Ung, Poorna Fernando
Place: 2nd and a midpoint bonus
Prize total: $7,000
Hometown: Adelaide, Australia and Colombo, Sri Lanka
Usernames: lasantha13, dinuja, ben.ung, Poorna_F
Social Media: /in/lasantha-ranwala-15b51323/, /in/dinujas/, https://people.unisa.edu.au/Ben.Ung, /in/poorna-a-fernando/
Background:
- Lasantha Ranwala is a medical doctor, health informatician, and PhD fellow at the University of South Australia. His research focuses on explainable AI-based clinical decision support systems.
- Dinuja Willigoda Liyanage is a dedicated AI developer with a keen interest in healthcare technology. Dinuja is passionate about quality and secure programming. He loves to follow the KISSS principle, which stands for "Keep it Simple, Stupid, and Secure".
- Benjamin Ung currently works at the Quality Use of Medicines and Pharmacy Research Centre at UniSA. He was previously a Product Specialist at Carl Zeiss Microscopy Australia until 2019, when he joined the Mechanisms in Cell Biology and Disease Research Group under Prof Doug Brooks at UniSA as a Research Fellow.
- Poorna Fernando is a Consultant in Health Informatics from Sri Lanka contributing towards bridging the gap between the health field and information technology. She is currently working as a visiting scholar at the Australian institute of health Innovation (AIHI), Macquarie University, Sydney, Australia.
What motivated you to compete in this challenge?
Our team's active engagement in digital health research projects has highlighted the significant challenges posed by unstructured data, such as clinical notes, radiology reports, and patient records. These data sources, while rich in information, are often difficult to analyze due to their unstructured nature. We are motivated to participate in this challenge to address these challenges, contribute to the advancement of healthcare, expand our knowledge and skills, and collaborate with like-minded individuals.
Summary of approach:
We extracted variables from the NVDRS dataset using three connected approaches: Topic Modeling to uncover hidden patterns, LLM Response Clustering to directly identify variables, and a Combined Method that merged insights from both. Two physicians independently reviewed each approach's findings and agreed on which variables were clinically meaningful. This two-doctor review process helped ensure our selected variables were medically valid while reducing any individual reviewer's potential biases.
We've designed our system to be adaptable and expandable. While we're currently focused on suicide-related factors, our framework can be applied to other healthcare analysis needs, from mental health studies to broader public health monitoring.
Check out HealthHacker's final submission and solution code in the challenge winners repository.
UM-ATLAS¶








Team members: Aparna Ananthasubramaniam, Elyse J. Thulin, Silas Falde, Lily Johns, Viktoryia Kalesnikava, Jonathan Kertawidjaja, Alejandro A. Rodríguez-Putnam, Emma Spring
Place: 3rd and a midpoint bonus
Prize total: $5,000
Hometown: Troy, MI; Jackson, WY; Jackson, MI; Ypsilanti, MI; Mogilev, Belarus; Berrien Springs, MI; San Juan, Puerto Rico; Brooklyn, NY
Social Media: aparna-ananth.github.io, @ejthulin, /in/silas-falde-25945b216/, /in/ar-putnam/
Background:
- Aparna Ananthasubramaniam (team co-lead) is a joint PhD student in the Schools of Information and Social Work. I use methods from data science to study the effects of housing loss and socioeconomic shocks on mental health, wellbeing, and other outcomes during the life course.
- Elyse J. Thulin (team co-lead) is a Research Assistant Professor with the U-M Institute for Firearm Injury Prevention. Dr. Thulin uses mixed behavioral science and data science methods to understand factors that enhance the risk of firearm-related injury, and ways that technology and online spaces can exacerbate or be leveraged to reduce the risk of harm.
- Silas Falde is a sophomore undergraduate at the University of Michigan School of Engineering studying Data Science.
- Lily Johns is a Research Coordinator at the University of Michigan School of Public Health. Her research interests include suicide prevention, mental health promotion, and health communication.
- Viktoryia Kalesnikava conducts research on social determinants of physical and mental health.
- Jonathan Kertawidjaja is an undergraduate at the University of Michigan studying data science, with an interest in deep learning and statistics.
- Alejandro A. Rodríguez-Putnam is passionate about public health interdisciplinary research and social justice, and interested in research focused on health administration, social epidemiology, emergency preparedness, and other topics.
- Emma Spring is a pre-medical undergraduate student at U-M, majoring in Biopsychology.
What motivated you to compete in this challenge?
Social media is a major influence in contemporary lives, with national leaders such as the Surgeon General calling for a greater understanding of the ways in which social media exacerbates worse mental health outcomes. While NVDRS has an existing variable related to suicide disclosure on social media, we found that there were multiple other themes related to social media in the LE and CME narratives, which provide critical contextualizing information as to the role social media played relative to an adolescent decedent’s death.
Summary of approach:
We used mixed qualitative and computational methods in our project. First, we used human intelligence (via thematic content analysis) to develop a codebook based on information present in the CME and LE narratives on social media. Then we leveraged the benefits of NLP algorithms (e.g., large language models) to apply this codebook to thousands of cases. We were then able to use classical statistics to examine trends by experiences on social media to generate novel insights related to social media and adolescent suicide.
Check out UM-ATLAS's final submission and solution code in the challenge winners repository.
Midpoint bonus prizes¶
Five midpoint bonus prizes of $1,000 were awarded to the most promising midpoint submissions, judged using the same criteria as the final submissions. Bonus prize winners included the three ranked prize winners and two additional teams:
- MPWARE, who developed a ReportsDiscrepancy variable to detect inconsistency between law enforcement and medical examiner report narratives
- Jackson5, who explored methods to identify panic attacks based on information in the narratives.
Thanks to all the challenge participants and to our winners! This challenge is organized on behalf of CDC with support from NASA. The contents do not necessarily represent the official views of the CDC.



















