








Looking back¶
When we started DrivenData in 2014, the application of data science for social good was in its infancy. There was rapidly growing demand for data science skills at companies like Netflix and Amazon. Prominent use cases focused on marketing and content recommendations. Applications of data science for nonprofits, NGOs, social enterprises and government services were nearly nonexistent.
Meanwhile, data science talent was hard to come by and expensive to hire, driving a talent gap in private companies that was vastly more acute for those working on social problems. Working out of the Harvard Innovation Lab, our initial focus was to address this talent gap for social applications. The goal, as we wrote at the time, was to bring cutting-edge practices in data science and crowdsourcing to some of the world's biggest social challenges and the organizations taking them on.
It wasn't just us thinking about this. Two of our favorite quotes around that time reflected two sides of the same coin:
Finding ways to make big data useful to humanitarian decision makers is one of the great challenges and opportunities of the network age.
UN Office for the Coordination of Humanitarian Affairs (OCHA)
The best minds of my generation are thinking about how to make people click ads… That sucks.
Jeff Hammerbacher, Former Data Manager, Facebook
The world has changed since then. Over the past ten years, we've gotten to see a lot of attempts to apply data science and AI for social impact. On our end, we’ve worked on over 160 projects with 120+ partners including The World Bank, Bill & Melinda Gates Foundation, Candid, Microsoft, IDEO.org, and NASA. We’ve run 80+ data science competitions awarding $4.3 million in prizes to impact-minded developers around the world. Through this work we've built up best practices and battle scars. We've seen a lot of practices that accelerate progress, and others that hold it back.
Big birthdays are always a good chance to step back and reflect. We want to take this chance to distill some of our overarching observations on doing data for good over the last ten years. Join us in reflecting on what has worked, what has not, and where the path towards a better future lies.
Here’s a preview of the ten takeaways we’ll cover in this post:
What has worked well
- Data science has had a meaningful impact on social challenges.
- Good data drives good solutions — and data of all kinds has become more available than ever.
- Efforts are most successful when grounded in an applied problem & targeted to a human need.
- Solutions work best when they incorporate the different strengths of machines and humans.
- Organizations benefit from a cross-domain perspective & the flexibility to meet them where they are.
What is still challenging
- Data science is iterative & the social sector under-invests in R&D.
- Data scientists can be hard to hire and support well (and it’s no fun being a lone data scientist).
- Open source under-develops solutions for non-developers.
- Attention is too often steered by hype waves.
- Data science and AI have huge ethical implications, but rapid adoption has outpaced tools and practices supporting ethical use.
Bonus: Want to see how AI tools like NotebookLM work? Listen to the AI-generated podcast based on this post. It's not perfect, but it's a fun listen!
Times they are a-changin'¶
Before we dive in, a word on the two-trillion-parameter elephant in the room. One unavoidable observation from the past ten years is that the pace of technological innovation, especially in data and AI, has been dizzying. A number of breakthroughs are enabling this progress, and here are a few key ones:
-
Compute and storage - The increased availability of cloud compute and storage has made it easier and cheaper to get the compute resources organizations need. The startup cost is now lower to deploy everything from a GPU-enabled virtual machine for a one-off experiment to a scalable cluster for real-time model execution.
-
Deep learning - It is hard to overstate how deep learning has transformed data science. The past decade has witnessed an explosion of novel, effective architectures: generative adversarial networks, transformers, variational autoencoders, graph neural networks, and many more. In tandem, software for deep learning has grown into a rich and mature ecosystem with PyTorch and TensorFlow as the keystones, along with an impressive host of tools, libraries, pre-trained models and datasets that accelerate progress.
-
Democratized skill access - With data science being the sexiest job of the 21st century, there has been a massive expansion in ways to build skills. Two of our co-founders were part of Harvard’s first Master’s program in Computational Science and Engineering in 2014, now one of many such programs at universities. The rise of these programs along with MOOCs, bootcamps, and applied opportunities like data competitions have resulted in far more people globally trained in basic data science skills to help meet the rising demand.
-
Generative AI - And of course, now generative AI is on the scene. While we're still collectively figuring out how much of gen AI is hype versus real, there's no question that large language models have already changed how we work. These models can dramatically reduce the time and effort needed to accomplish once challenging tasks, and make other previously unfathomable tasks (like AI podcasts) possible. It is clear from our work with clients and in competitions that gen AI in some form is here to stay.
Even with all these changes, what we have seen is that many patterns transcend the specific technology of the moment. This post will focus on these observations, considering over the past decade what we have seen work well and what remains challenging.
What has worked well¶
1. Data science has had a meaningful impact on social challenges.¶
Ten years ago, it was increasingly clear that data science tools were powerful and had huge potential to help with the biggest social challenges. However, applications of data science for social impact were still limited. Discussions always cited the same few examples, and most of the discourse focused on ideas for what might be possible in the future.
Today, machine learning models influence on-the-ground decisions across diverse domains, from inpatient healthcare to managing natural resources. Data science is used to protect people from dangers like harmful algal blooms and unsustainable fishing practices, and to monitor effects of a changing climate on natural disasters, financial inclusion, and wildlife conservation. In the public sphere, data visualization has become a common medium for journalistic reporting and messaging, such as the COVID-19 flatten the curve campaign and live dashboards by the World Health Organization.
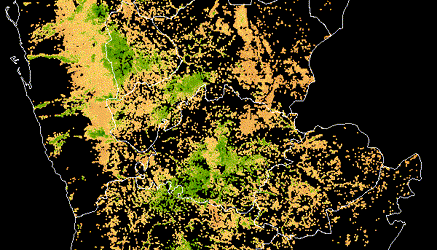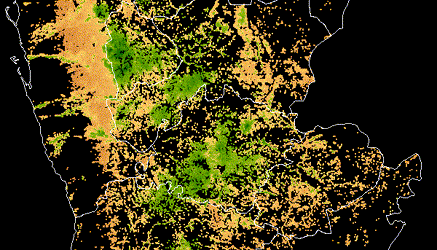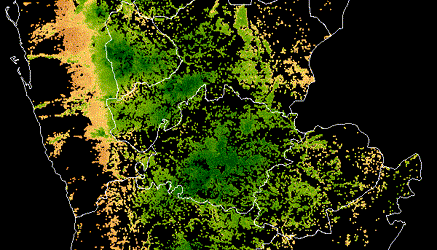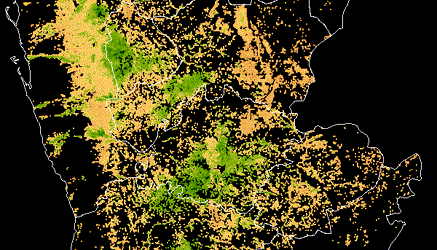
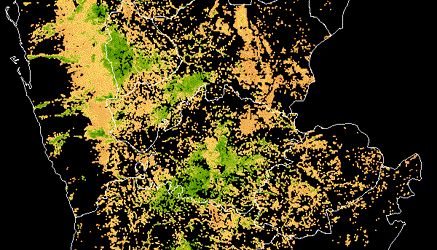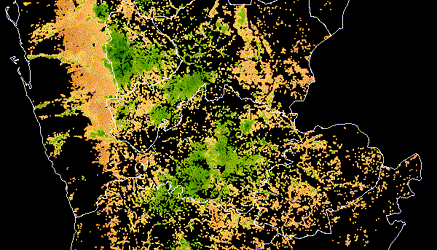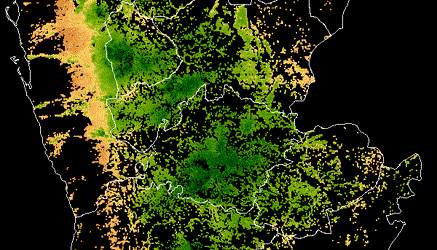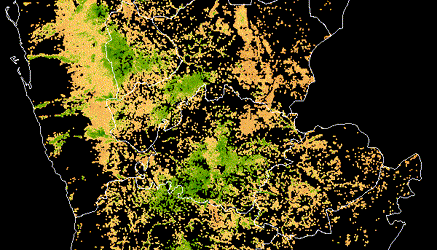 Satellite imagery is used to identify crop extent, crop types and climate risks to agriculture in Yemen, informing World Bank food security programs in the country after years of civil war.
Satellite imagery is used to identify crop extent, crop types and climate risks to agriculture in Yemen, informing World Bank food security programs in the country after years of civil war.
AI methods are also advancing scientific progress against a range of complex problems. Many leading solutions have been elevated through open innovation competitions. AlphaFold, a protein folding prediction model for which a Nobel prize was recently awarded, can do work in hours that previously took years, and the AlphaFold Protein Structure Database makes all known protein structures freely available to all scientists. An early demonstration of transformers was applied to detect hate speech in multimodal memes. Technology for identifying individuals helped improve the tracking of endangered whales and has since been extended to a wide range of other species.
In the mid-2010s, when social sector organizations thought about data, the conversation often began and ended with measuring impact. While this continues to be an important question that requires data, it has also become clear that data for good is about more than impact measurement. Data science tools can change the way organizations operate, acting as a force multiplier for the work they do and enabling new capabilities. The vast majority of discussion about the impact of data science and AI today is not just about what they can measure, but what they can do.
2. Good data drives good solutions — and data of all kinds has become more available than ever.¶
Over the past decade, data has made its way into everyday life. Data is generated every time you make a purchase, call emergency services, or go to the doctor. Home appliances, wearable devices, cars, laptops, phones, and apps are collecting detailed data about usage. Sensors and cameras have become much cheaper and easier to use, leading to a proliferation of image and video data. As more records and communications have become digitized through the spread of the internet and the use of software, vastly more information is available as computer-readable data.
The first step change in capturing all this data digitally was having that information available so we could observe what was happening. The second step change has been to use that information to learn from. Data science, machine learning and AI rely on data. The existence of better data—and in cases like ChatGPT, simply more data—has led to new ways to find patterns across populations, powering algorithms from cancer detection to your Spotify recommendations.
Transforming an organization or an industry by using this data takes time and a good strategy. One of the tools we have found useful in our work is Monica Rogati’s Data Science Hierarchy of Needs. It can be tempting to talk about the flashier capabilities higher up the hierarchy, but what is often needed first is the data foundations those capabilities require. Smart investment in available data has in turn laid the foundation for much more to be built on top.
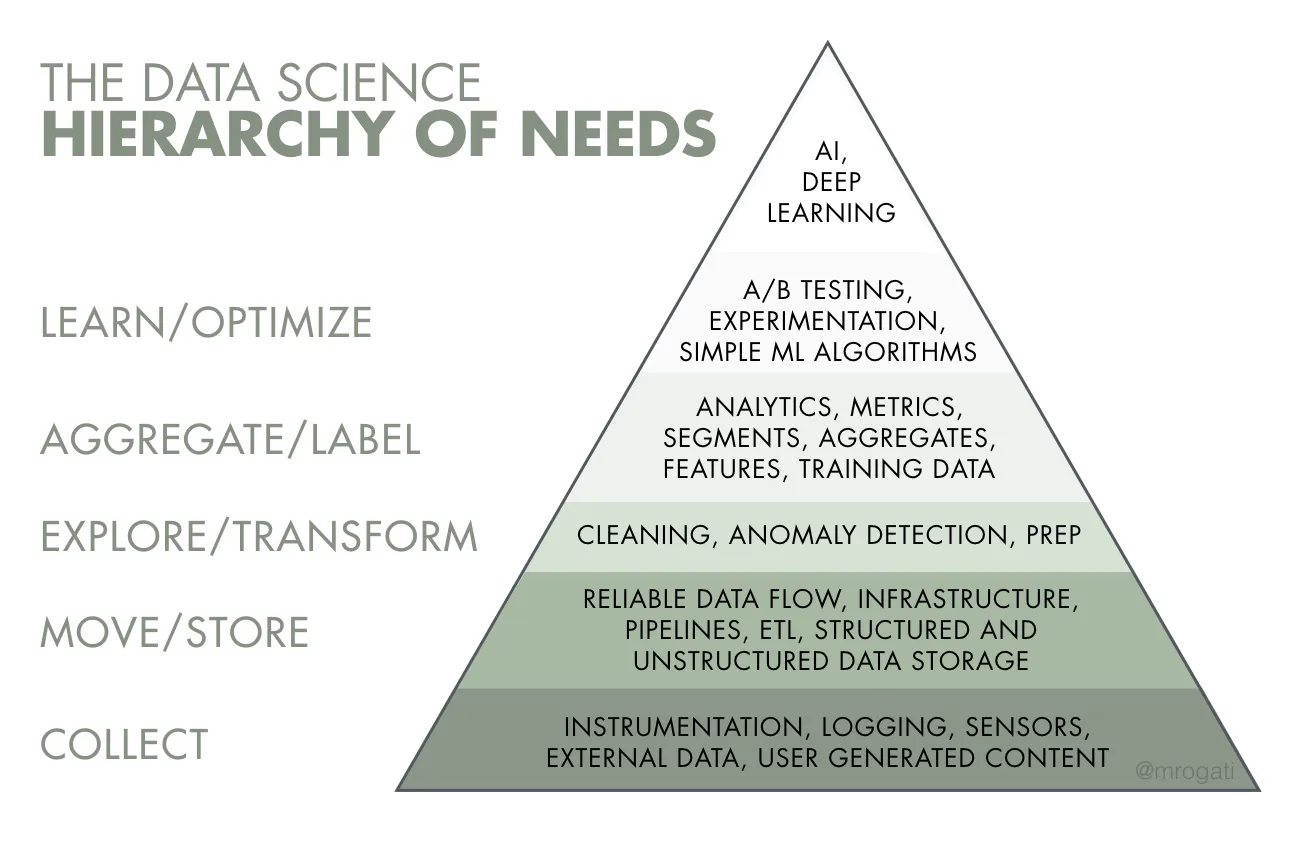 Monica Rogati’s Data Science Hierarchy of Needs. Analytics, machine learning, and AI rely on good underlying data and data systems.
Monica Rogati’s Data Science Hierarchy of Needs. Analytics, machine learning, and AI rely on good underlying data and data systems.
More and more data is also being made available for causes that matter. Governments and other large institutions now produce and publish a lot of data for the common good, and others make data available for research and learning. For example, we’ve used many of these types of data in our work:
- Public service data, like weather data, transportation data, and OpenStreetMap data, often provides baseline information for applications like air traffic planning and disaster resilience
- Satellite images can be used to map flood extent and estimate forest biomass
- Mobile transaction data can be used to understand financial behaviors and attitudes
- Survey data, both privately and publicly collected, can give insight into opinions and behaviors on a large scale
- Audio recordings can be used to classify childhood literacy levels
- High-res images can be used to predict the likelihood of melanoma relapse
- Text data can be used to automatically analyze clinical concepts in doctors’ notes
One thing we have seen is the importance of making data accessible, not just available. For example, datasets in a machine-readable format that come with clear documentation and a demonstration of use are much better at getting attention and engagement. From running challenges, we have come to believe that the dataset documentation and demonstrated application do as much to drive forward the impact as the challenge prize pool. Too often organizations make substantial investments in collecting data and stop short of the incremental investments that support its use, ultimately limiting the value it delivers to themselves and others.
3. Efforts are most successful when grounded in an applied problem & targeted to a human need.¶
With the wider availability of data and the increasing power of AI, social impact organizations sometimes find themselves desperate to “catch up” to the latest and greatest in the tech hype cycle. “Big” datasets end up looking a lot like a large pile of nails, and AI tools like a set of automated hammers. It’s enticing to think that throwing them into a pit together will produce a perfectly constructed solution. In our work, however, we have found that rather than leading with technology and data, the most effective data science projects involve solving a specific problem for a specific user.
For us, designing a successful project means working with our partner to identify a specific, measurable need or set of needs that they want to improve. Defining this objective requires a focus on identifying the key problem and the user with that problem, and then creating ways to measure how well a machine learning model solves it. The tools of human-centered design have been especially helpful in identifying what is desirable to people, rather than what is simply feasible, and building the right kinds of tools that help the technical solution succeed.
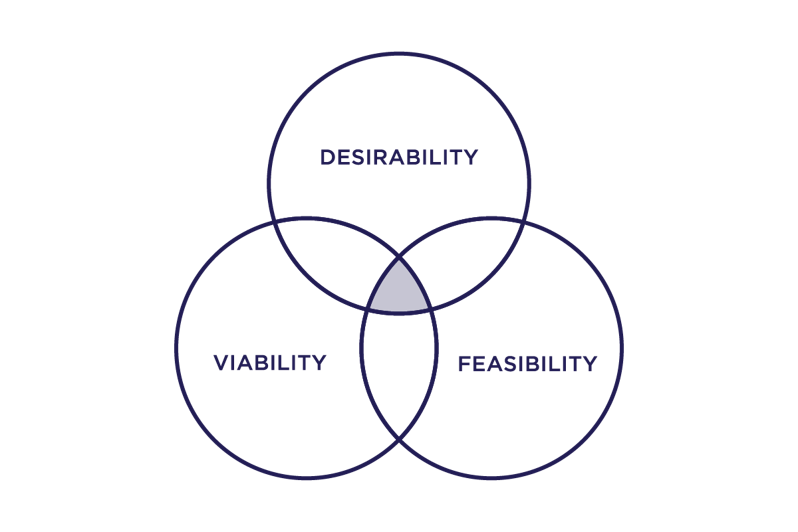 IDEO's Desirability, Viability, Feasibility Framework. The tools of human-centered design can help solutions start from what is desirable to solve a real problem, not just what is feasible with technology.
IDEO's Desirability, Viability, Feasibility Framework. The tools of human-centered design can help solutions start from what is desirable to solve a real problem, not just what is feasible with technology.
For example, let’s look at a couple concrete applications where hosting a competition around a specific human need has led to the creation of purpose-built open-source solutions:
-
Detecting harmful algal blooms (HABs): Algal blooms threaten water supplies and water recreation. Water resource managers currently use manual sampling techniques to detect these blooms, which are accurate but time-intensive. Together with NASA we hosted the Tick Tick Bloom competition to identify harmful cyanobacteria blooms from satellite imagery using machine learning. The winning solutions were built into a tool called CyFi (Cyanobacteria Finder) that enables water resource managers to more accurately estimate the presence of harmful blooms in different bodies of water and allocate their time and resources more efficiently.
-
Identifying wildlife from trail cameras: Wildlife camera traps provide valuable information to conservation researchers. However, the videos they capture are time-intensive to review and label with the correct species, requiring many hours of paid expert or trained volunteer time. With the Max Planck Institute for Evolutionary Anthropology, we hosted the Pri-Matrix Factorization competition to use machine learning to identify which animals are present automatically, then built the winning solutions into an open-source tool called Zamba (“forest” in Lingala). After soliciting feedback from wildlife researchers who used the tool, we also created Zamba Cloud to make it easier to interact with these models through a UI rather than through the command line.
In cases like these, the importance of the user perspective is evident both before and after the machine learning solution is built.
-
Defining the problem: The best way to make solutions that solve real problems is to talk to users. In the process of setting up a data science project, we’ve repeatedly seen the benefit of upfront user interviews and elicitation sessions to understand the processes, needs, and pain points that users face and the human perspectives behind the data points.
-
Translating the solution: It doesn’t matter if the solution works if the target users can’t use it effectively or don’t understand the benefit. It's important to take time to user test the UI/UX, communicate what the tool does and why this is useful, help people build an intuitive sense for what the model gets right and wrong, and illustrate use cases where model outputs can impact real-world decisions.
Ultimately, part of our job as data scientists is connecting the technical capabilities of what we do with why they matter for people and organizations. Our mandate is to find the best tool for the job by understanding the problem and identifying an appropriate technology. Rather than being guided by the latest, coolest methods, the most effective projects focus on demonstrating results.
4. Solutions work best when they incorporate the different strengths of machines and humans.¶
Another reality that can get lost in the hype around AI is that data science models are not infallible and machine learning is not a panacea—all models are wrong in some way and simply incorporating AI into a product or solution is no guarantee of success. Rather than all-or-nothing magical thinking, the best solutions leverage what algorithms and humans do well to create a system that delivers the best results.
Take the Zamba tool we discussed above. One of the models in Zamba estimates the probability that a wildlife camera trap video contains an animal or is blank. But the model is wrong sometimes! Some videos labeled as blank have animals, and vice versa. What is a researcher to do?
Here’s where we can combine the strengths of humans with the strengths of machines. While machines aren’t perfect, they give us a probability that tells us how confident they are. Using the probability is helpful! For example, a chimp researcher can order videos by probability to review videos that are most likely to contain chimps first, or choose a probability threshold for discarding blank videos that strikes an acceptable balance for their analysis. By conducting a targeted search, the researcher can find around 85% of all chimp videos while going through less than 5% of all videos—saving themselves a lot of valuable time to interpret the results.
Increasingly, we’re seeing cases where explicitly designing systems to benefit from machine and human contributions outperforms either alone. For example, radiologists using AI to screen for breast cancer were more effective than without the AI, and the AI was more effective when augmented by the radiologist. In connection, there has been a growing emphasis on the explainability and interpretability of AI solutions. This is not just to inspect what these systems are doing—though that is an important use—but also to give humans more useful information to evaluate their outputs and integrate with other relevant context at their disposal.
 Example visualization from the explainability bonus track of the Where’s Whale-do competition. The image uses a technique to highlight parts of the beluga that the model is using to match individual whales, providing an added tool for human reviewers monitoring the population over time.
Example visualization from the explainability bonus track of the Where’s Whale-do competition. The image uses a technique to highlight parts of the beluga that the model is using to match individual whales, providing an added tool for human reviewers monitoring the population over time.
We’re witnessing a similar pattern emerge in generative AI, where human feedback on generated responses was essential to ChatGPT breaking through as a useful tool. Capturing this human feedback as data can also help progressively improve machine learning systems over time, covering more of the harder and rarer cases that the systems can learn from.
Asking two key questions: “what would you do if you had a model that did [X] perfectly?” followed by “what would you do if that model was a little bit wrong sometimes?” can help to think about the costs of different errors, to identify the parts of the system that are more error-tolerant (and how error-tolerant they are), and the parts of the system that require more human intervention or review.
Unsurprisingly, we have seen some organizations learn this lesson the hard way. For example, in 2021 the Dutch Prime Minister and entire cabinet resigned after investigations revealed that 26,000 innocent families were wrongly accused of social benefits fraud partially due to a discriminatory algorithm. This was a clear case where relying on an algorithm without appropriate human review had an unacceptably high human cost. Of course, the answer is also not to avoid algorithms and automation altogether. There is a clear benefit to using taxpayer dollars more effectively and, especially, providing better benefits with shorter wait times. The organizations that have done this well have figured out how to combine algorithms and humans in the ways that take advantage of the relative strengths of each.
5. Organizations benefit from a cross-domain perspective & the flexibility to meet them where they are.¶
Over the past decade we have regularly asked ourselves if we should narrowly specialize in a specific industry or technical approach. After ten years of doing this work, we’re still generalists. Our projects have spanned a wide variety of issue areas—from financial inclusion to climate action to healthcare, just to name a few. Across this work, we’ve seen a real benefit to having a cross-domain perspective.
For instance, this perspective makes it easier to pattern match and identify places where machine learning can provide value, even in disparate contexts. We’ve employed computer vision models to map kelp forests for conservation efforts and also to detect lesions in cervical biopsies for earlier and more accurate cancer diagnoses. Seemingly unrelated problems like supporting early detection of pests that are threatening crops in Africa and extracting skills from resumes to support job matching are both rooted in named entity recognition. Having applied approaches in one context makes it easier (and cheaper) to bring them to bear on another, building on the experience and lessons learned along the way.
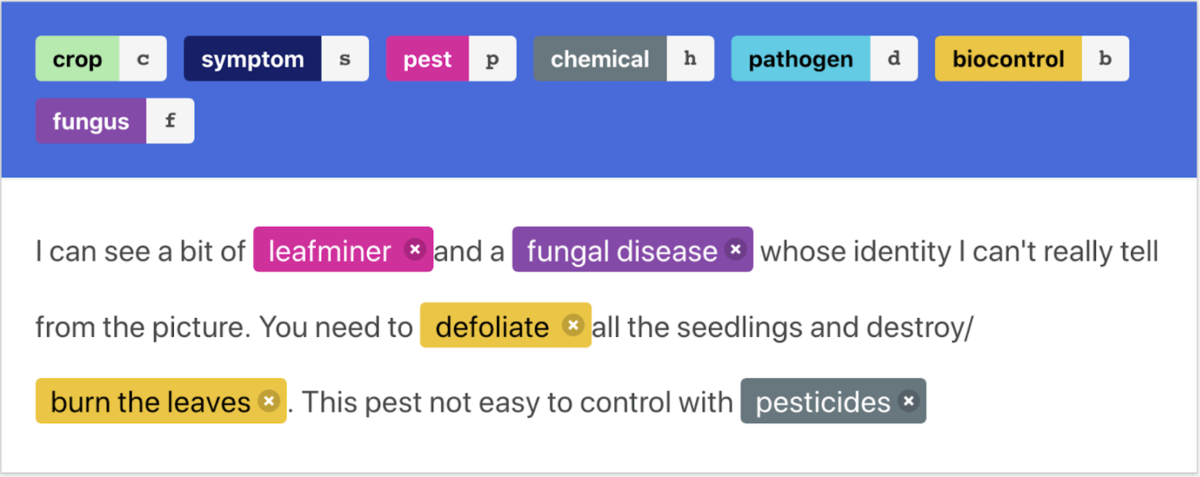 Approaches in natural language processing from a skill development application also help recognize crops, pests, diseases, and chemicals in WhatsApp messages, enabling new ways to surface emerging trends and improve science-based guidance for smallholder farmers.
Approaches in natural language processing from a skill development application also help recognize crops, pests, diseases, and chemicals in WhatsApp messages, enabling new ways to surface emerging trends and improve science-based guidance for smallholder farmers.
Of course, there are clearly benefits to specialization and building on domain experience, especially when it comes to deep understanding of needs and what has been done before. We partner with domain experts on all of our projects to ensure we have the appropriate problem context. We have various expertise represented on our team. And as mentioned above, we’re strong advocates of bringing user perspectives into the data science process.
One of the most important parts of our work is figuring out what the work is that’s worth doing. Technical expertise alone is insufficient for this; you need empathy, communication, curiosity, and flexibility. Having the cross-domain perspective makes it easier to brainstorm places where machine learning can add value, but this must be rooted in a deeper understanding of who the approach serves and how it would actually be used.
This combination of hard and soft skills makes it possible to meet organizations where they are and shape the approach to the problem at hand. Organizations have different needs as work develops from exploratory discovery to research and development to prototyping to production. Similarly, sector partners range from large data-providing organizations like Candid and NASA to others setting up data systems for the first time. Across these cases, partners know their domains well; what they need is someone that understands how to bring data science capabilities to bear on those problems, and that, rather than pigeonholing projects into certain techniques, can instead draw from a rich range of experience.
What is still challenging¶
6. Data science is iterative & the social sector under-invests in R&D.¶
Research and development is a learning process. It takes capital expenditure, experimentation, reflection, and a willingness to fail. What it promises is knowledge that unlocks substantial improvements that we couldn’t have known about otherwise. Sure bets, proven methods, and short time horizons are too limited in their potential to tackle the scope of problems we as a sector need to tackle.
Despite this fact, very little philanthropic capital flows towards research and development activities in the sector. For example, an NSF survey reports that in 2022, 94% of larger non-profits that are not small, local organizations did not have any R&D activity (see the survey technical note for a more detailed breakdown).
What some in the sector may not realize is that data science is most often an R&D activity. It is an iterative process designed to help learn about the products and services that yield the best outcomes and to improve the efficiency of their delivery. Over the last ten years, the data science community has developed a number of frameworks for expressing this property of the data science process. All of these emphasize the feedback loop that is inherent in the data science process.
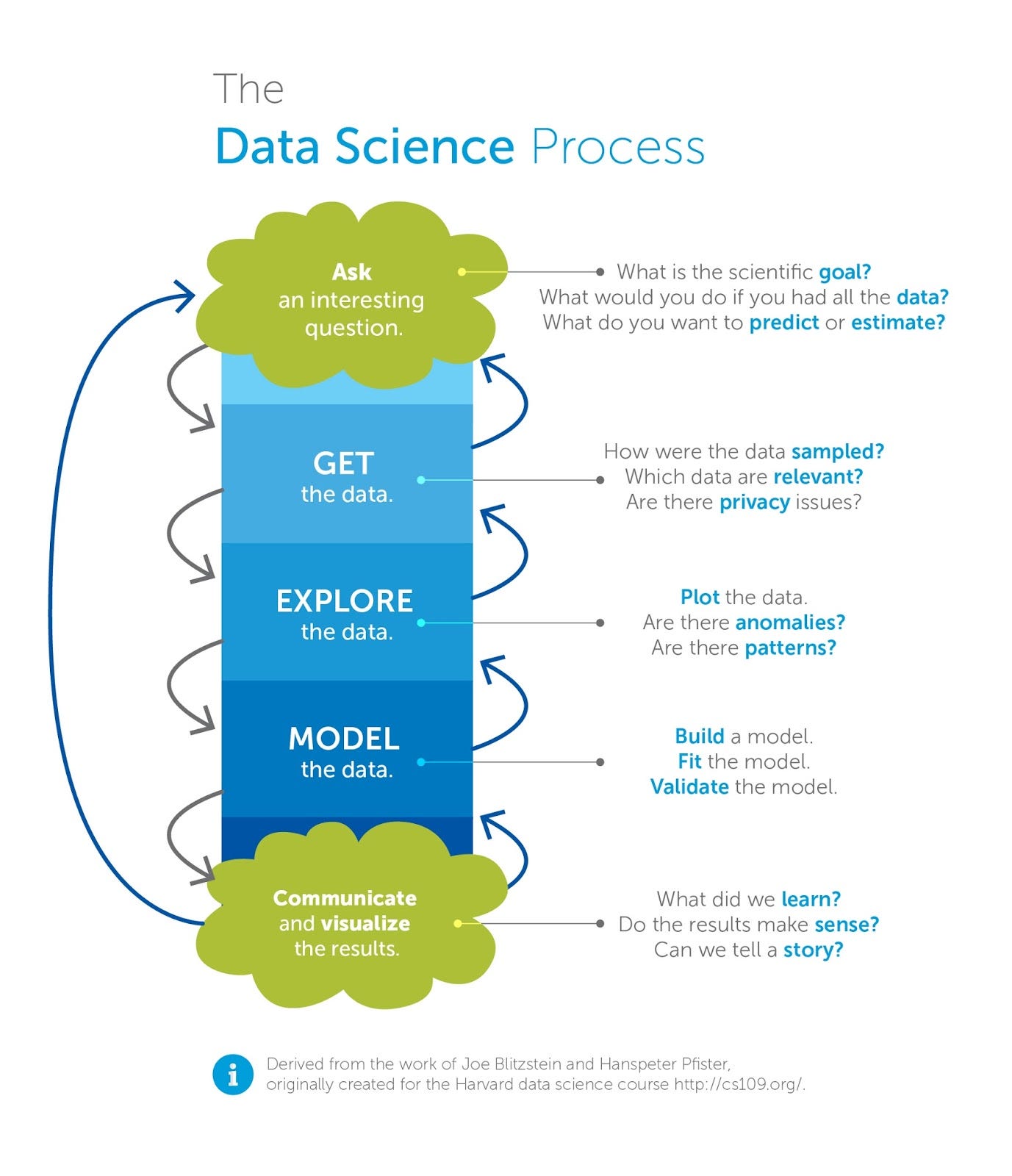 |
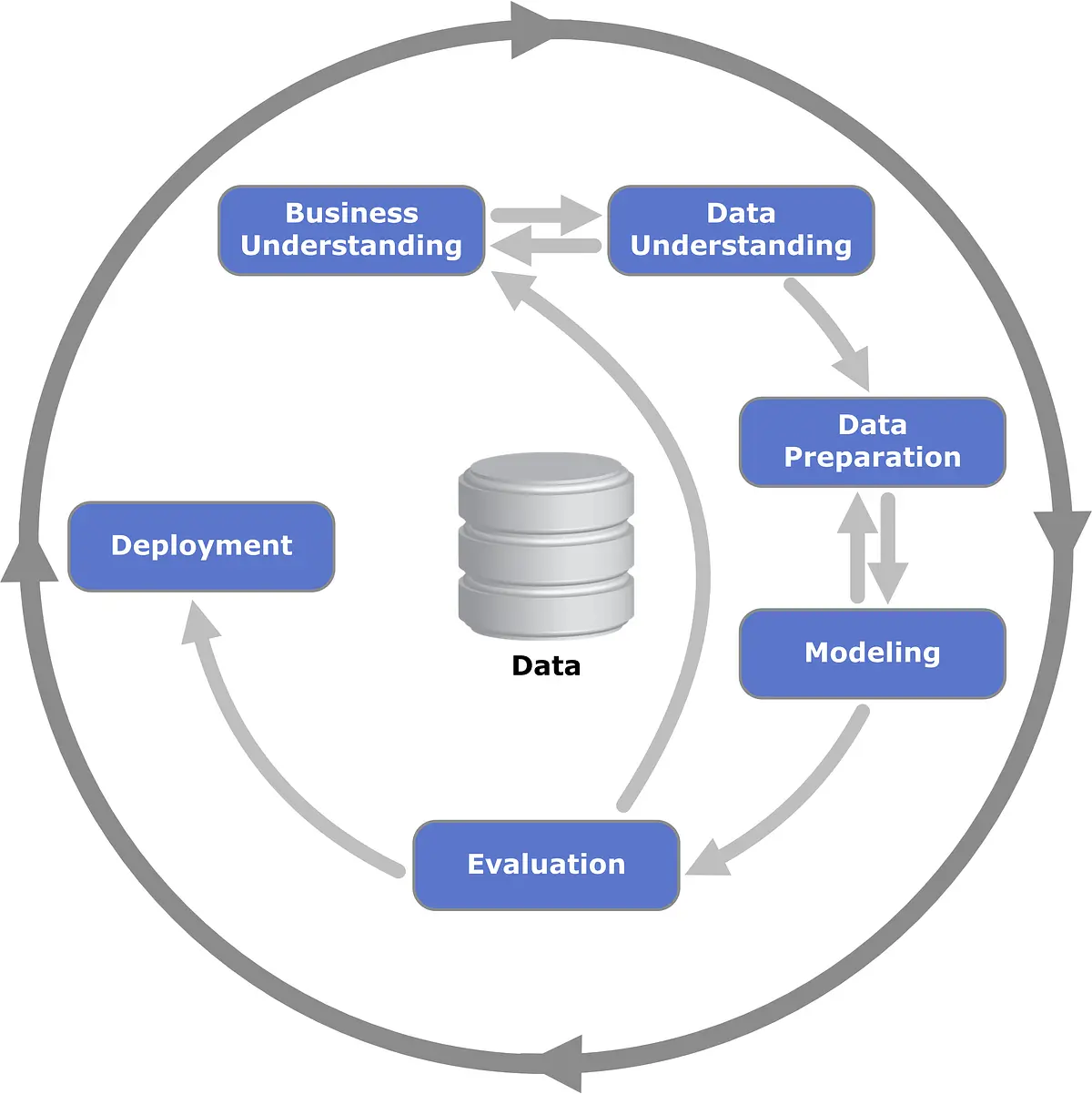 |
|---|---|
Data science processes are canonically illustrated as iterative processes. For example, on the left is the process as taught in Harvard’s Introduction to Data Science course, and on the right is classic data mining industry process CRISP-DM.
As we have discussed, we have preferred a framework of human-centered data science, where the learning process is guided by designing effective solutions. The natural cycles of the design process, a repeatable framework of innovation, complement our data science process.
At this point we can rely on the fact that, while specific outcomes of data R&D projects may be uncertain at the outset, the process of delivering value from data is well-proven. Private companies have clearly realized this. As a sector, we should be inspired by the R&D process and investment that have led to recent AI breakthroughs. These kinds of non-linear step-changes in capabilities are only possible through a sustained investment in R&D, and this is the way we create the innovation that accelerates progress.
7. Data scientists can be hard to hire and support well (and it’s no fun being a lone data scientist).¶
This is a challenge we hear from organizations and data scientists alike. Social sector organizations often do not have the capacity to hire data scientists, but they know they need expertise. Many need around one data scientist rather than a team. When they do look, they find it hard to attract and support a lone data scientist in a way that keeps them productive, and not burned out.
On the organization side, this often translates into a getting-started problem. There are few things that make this hard:
-
Hiring: It’s hard to identify and assess the right candidates effectively without existing data scientists to know what to look for. This is especially challenging given the growing number of applicants that are using the term “data scientist” with a wide variety of skills, training, and experience that this can represent.
-
Attracting and retaining talent: The surge in demand for data scientists has led to a competitive job market for skilled workers. Organizations tackling social challenges often offer motivating problems, but they also need to factor in the interesting technical work, competitive salaries, and professional development opportunities that skilled workers value. Providing this is especially challenging when trying to bring on an early hire.
-
Management: Supporting a data scientist well means helping to scope problems effectively for them to take on, providing direction, infrastructure and data to keep them productive, setting realistic expectations, and assessing their work. These are all difficult without a shared technical background—especially when it’s notoriously hard to estimate the level of effort required to achieve different tasks with the tools of the day.
 xkcd: Tasks. It turns out this particular task has become a lot easier - but there is still wide variability in the difficulty of different data science work that’s often hard for non-developers to estimate.
xkcd: Tasks. It turns out this particular task has become a lot easier - but there is still wide variability in the difficulty of different data science work that’s often hard for non-developers to estimate.
On the developer side, we have heard repeatedly that, for the most part, skilled candidates find it less attractive to be the lone data scientist at an organization. This is not to say that there are not good, satisfied data scientists out there working alone. However from what we’ve seen, this is the exception rather than the rule. This is for a few reasons:
-
Learning and growth: Data science is an expansive field that has been advancing rapidly. Even with a strong foundation, there is always ample room to grow. Developers want to be somewhere they can learn from the knowledge and experience of others on the team. We’ve looked to share some of our best practices and learn from others; but this is still hard when there’s no one to review your code or models, offer feedback, or help carry the load.
-
Direction and support: Data scientists unsurprisingly tend to feel more satisfied and more productive when they are well-supported in their work. With the difficulty in providing these supports described above, even highly skilled data scientists may struggle to add the intended value.
-
Enjoyment: It’s also just more fun to have coworkers that you can discuss and solve problems with. This can be accomplished outside of your organization, but it’s often easier when you have colleagues who have the same shared context and can look through your code or data together.
This is slowly starting to change. We have partnered with more social sector organizations that have their own data team recently, which was almost never the case ten years ago. As part of an effort to build capacity, we’ve also partnered with organizations to help identify their first data science and data engineering hires, onboard those folks, and transition work to them.
Additionally organizations are choosing to work with an external data science practice like us to give them flexible, expert capacity. This works well for organizations and also for data scientists who get to have the benefits of being on a great team while being able to work on problems that matter.
While some organzations are starting to make it work, data skills are still in high demand in the social sector and we expect the challenge of bootstrapping a data team to continue.
8. Open source under-develops solutions for non-developers.¶
Inspired by the success of open-source software, social sector organizations and funders have increasingly championed open solutions that are accessible to everyone. Over the past decade, we've repeatedly learned that “open” alone is not enough. Just because something can be used or learned from doesn't mean it will be.
In open-source software development, the community creating the software is often the same as the community using it. Contributors understand their own needs, can identify shortcomings in existing tools, and are motivated to make improvements because they directly benefit from the changes. Many of the open source tools that we’ve created and maintained for the data science community, like Cookiecutter Data Science, are ones we ourselves use on a regular basis. In cases like these, ongoing contributions are driven by personal use and a desire to improve workflows that contributors understand and empathize with. However, we can’t rely on these same incentives for tools built for others who don’t have the technical capacity to contribute themselves.
In our data science work, we frequently develop methods and tools intended for non-experts—often non-developers or non-data scientists. When these projects are completed, releasing them as open source may seem like the logical next step. However, the reality is that many open-source projects, particularly those funded only to the prototype or experimental stage, quickly become stagnant, less relevant, and ultimately defunct. Without sustained investment, even promising projects often fail to realize their full potential.
What’s needed instead is funding to carry these projects beyond the prototype stage. Prototypes must be iterated upon and tested in real-world pilot scenarios with end users. From there, a roadmap for development and continued focus are necessary to transform them into fully realized, impactful products. Simply being open source does not guarantee this kind of growth.
 An example of the Concept to Clinic demo application, which is the kind of user-facing tool that the open source community does not build and maintain on its own.
An example of the Concept to Clinic demo application, which is the kind of user-facing tool that the open source community does not build and maintain on its own.
We explored ways to address these challenges in our Concept to Clinic challenge in 2017-18. The project focused on developing an open application to assist radiologists in processing CT scans using AI algorithms. To encourage contributions, we implemented a bounty system: contributors earned points for completing tasks, with larger contributions earning more points. At the end of the challenge, participants converted their points into monetary rewards. This kind of structured incentive was crucial to fostering the contributions needed to make the project viable. Without it, the application likely wouldn’t have been developed at all.
While open source is valuable, an open source release should not be the end goal of projects building critical applications for the social sector. Hoping that if you build it (and open source it) developers will come to build and maintain it is a fundamental misunderstanding of how open source works. To ensure success, we must prioritize funding models that support the transition from prototypes to end-user-ready solutions. Open source may be part of that journey, but it is not a strategy for lasting impact.
9. Attention is too often steered by hype waves.¶
We’re approaching the end of our list, so it is time to zoom out from AI and think about the general case of how the social sector handles new tech. Over the past decade, innovation in the social sector has been tightly intertwined with successive waves of emerging technologies. For many organizations, the promise of greater efficiency to deliver results under tight constraints is compelling. For philanthropies, staying responsive to emerging trends feels essential to ensure their grantees aren’t left behind.
A fundamental problem, however, is that it is hard to signal-process a hype wave into just the key impacts for taking action and advancing the missions of the social sector. Often, enthusiastic embrace of emerging technology does not go well. On the ground, organizations are left grappling with overpromises and underdelivery. Philanthropies, meanwhile, find themselves stuck in an endless cycle of revamping strategies to respond to the latest trends.
Nowhere has this been more evident than in blockchain—an innovation that came with sky-high expectations but has so far delivered little practical benefit for the social sector. But, it is even evident with more fundamentally sound technologies like mobile applications. While consumer-facing organizations did well to have a mobile application, many costly mobile apps were built because organizations “had to have one”, even if their use case was better served by improving in their website or investing in more volunteers or staff to interact with beneficiaries.
Amid this landscape, we’ve found that organizations of technology experts who are equipped to handle the incoming waves have the most impactful results. For data and AI, DrivenData is proud to be part of a cohort with organizations like DataKind, the DSSG fellowships, Delta Analytics, and more over the last ten years. But, as the founder of DataKind pointed out earlier this year, this pattern of expert groups popping up to help with a new technology is a part of the cycle of new tech that we have seen before. In general, these new organizations are technical experts, but they don’t have the network and experience to learn hard won lessons from previous hype waves.
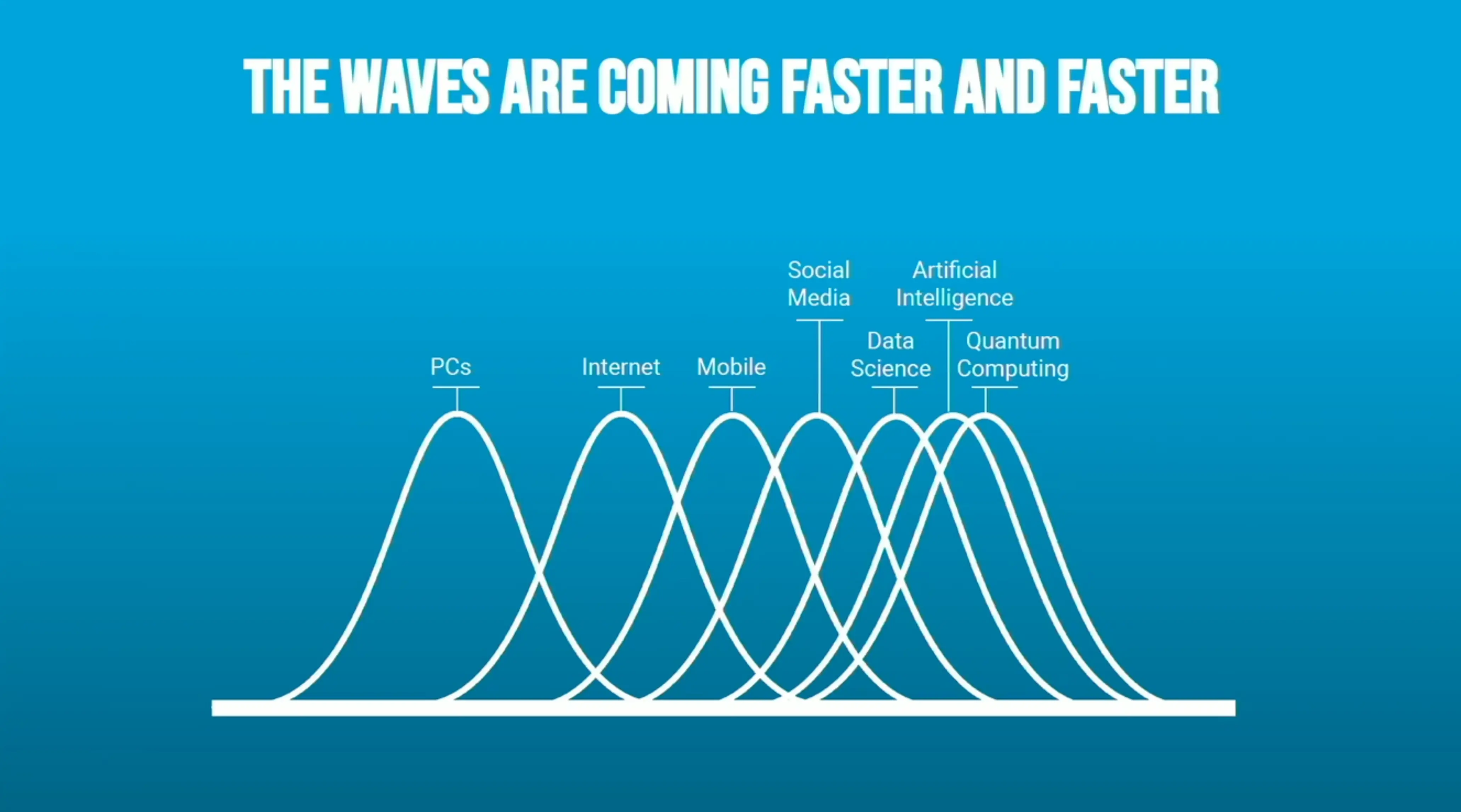 Recent cycles of hype waves of new technologies affecting the social sector (courtesy of Jake Porway).
Recent cycles of hype waves of new technologies affecting the social sector (courtesy of Jake Porway).
What the social sector needs is a breakwater for hypewaves. We need the capacity to separate real innovations from overinflated promises and identify the core advancements that can truly drive progress. This capacity can only be provided by having technologists that are both at the cutting edge of these fields and deeply understand the social sector. This capacity does not exist as an institution or an ecosystem at the moment, and we cannot expect the broader market to distill these lessons for our industry. Without technical leadership that can assess these waves and communicate effectively to the sector, we will continue to be stuck in a cycle of reactivity, constantly refreshing our strategies and piecing together fragmented approaches that struggle to reach maturity, squander resources, and miss opportunities.
This is especially important as AI becomes the latest wave capturing attention. While the potential of AI is vast, navigating it requires more than enthusiasm; it demands thoughtful strategy, deep expertise, and a commitment to investing in the foundational elements that will allow these technologies to flourish. Without this shift, the sector risks becoming paralyzed by hype—drawn into reactive cycles that fail to build the resilient, data-driven foundations we need to thrive.
10. Data science and AI have huge ethical implications, but rapid adoption has outpaced tools and practices supporting ethical use.¶
Compared to when we started, data science and machine learning have been integrated into many more facets of daily life. From medical care to disaster response to criminal sentencing, the stakes when things go wrong are higher than they have ever been.
Our work has shown that data scientists have a unique perspective and understanding of the ethical implications of a model or pipeline. However, bringing that perspective to bear often is not integrated into the life cycle of a data science project. As one way to try and address this gap, we created an open source checklist to integrate discussions of key ethical tradeoffs into a data science workflow. It reflects some key principles that we have observed based on what has gone right – and wrong – in some real-world examples:
- Most decisions with an ethical implication represent tradeoffs. The goal is to be aware of the most important ethical implications in a specific context to make the decisions most likely to support responsible progress and minimize harm.
- There are distinct ethical concerns at each point in the data science project lifecycle, from data collection and storage to analysis, modeling, and deployment. Ethics is not just a checkbox that can be completed at the beginning of a project.
- Ethical discussion can get deprioritized with pressing deadlines and demands. Intentionally budgeting time and integrating ethics questions into other aspects of a data science workflow can help make sure these discussions are happening in fast-moving environments, before things go wrong.
- Best practices of open science can further goals to build a more inclusive and diverse community of practitioners.
In the machine learning research community, more attention has been paid over the last few years to algorithmic fairness. A model trained on data that reflects inequality in the world will learn to be unequal, unless steps are actively taken to correct for bias. Techniques are being developed for identifying, mitigating, and communicating bias. However, these techniques often haven’t made their way into specific applied domains that are using ML in the real world. For example, through a partnership with Wellcome Trust, DrivenData created an annotated example of how bias identification and mitigation can be used in a practical setting to incorporate fairness considerations into a robust model for predicting psychological distress.
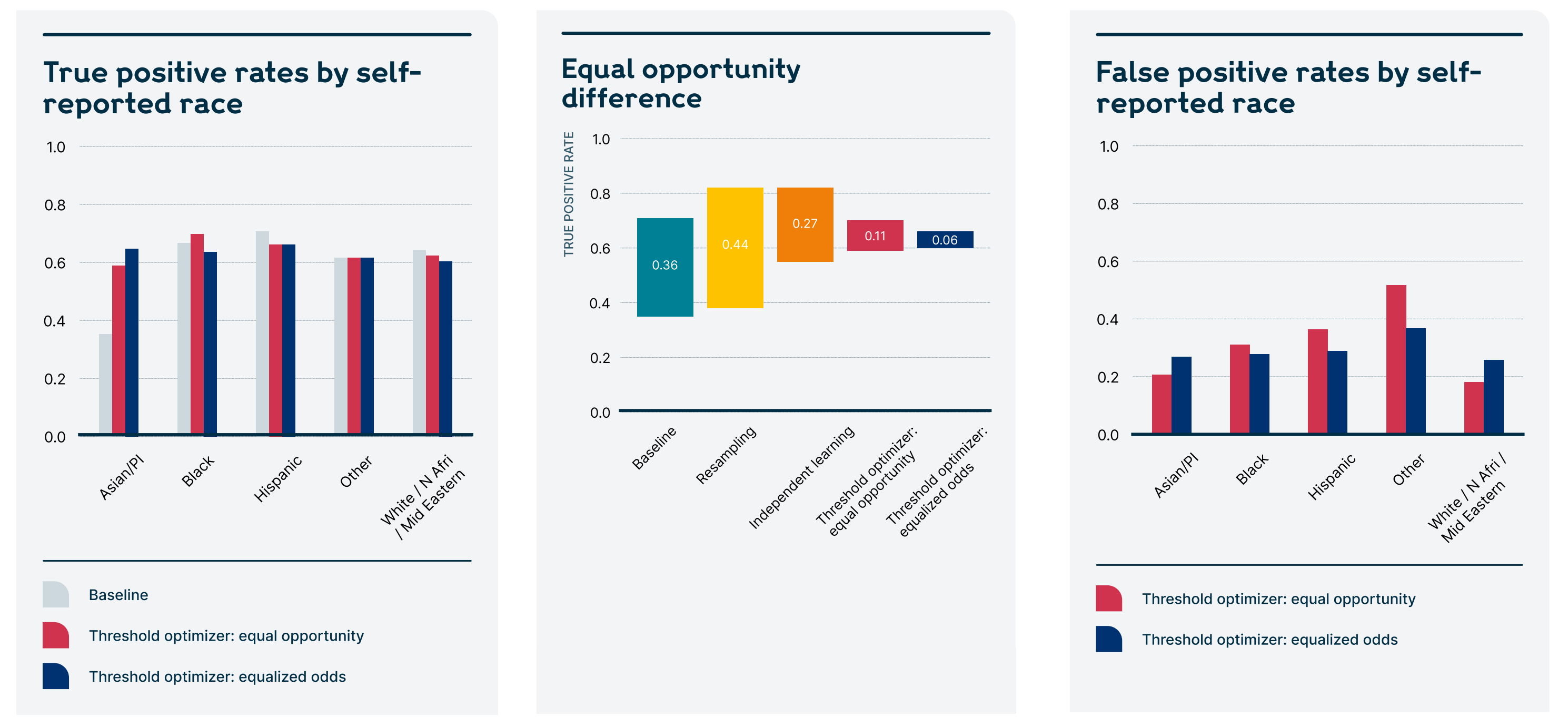 A comparison of quantifiable fairness metrics from the annotated fairness analysis we produced for Wellcome Trust.
A comparison of quantifiable fairness metrics from the annotated fairness analysis we produced for Wellcome Trust.
The stakes of the AI boom are making ethical considerations even more critical. While embracing more and more AI, companies have been simultaneously dismantling their responsible AI teams to cut costs. In the social sector where we feel a deep responsibility to our beneficiaries, the stakes are even higher. Now more than ever we need to build in a way that takes these considerations seriously.
Looking ahead¶
It’s an exciting time to be in this field. The last ten years have been a transformative period for data science in the social sector, with remarkable successes and persistent challenges. There is undoubtedly greater awareness of what data and AI can do. Still, big questions remain. How do we make ongoing advances practically useful to the biggest social problems? How do we make sure the benefits don’t accrue to a handful of big companies? How can we deploy these capabilities in a responsible way for the benefit of nature and humanity?
To take on these questions, we need all the help we can get. We believe efforts benefit when grounded in the lessons learned from experience. We are proud to be part of a fantastic community of partners, clients, and developers that are pursuing ways to use data and AI for social good. If any of the topics above resonate with you, or if you have others to share, we’d love to hear from you.
It’s been a remarkable decade. And with the current pace of progress, it’s not hard to imagine the next decade bringing even more change than the last. There’s a lot more to do, and there will be a lot more to learn. We’re excited to take on these challenges and see what the next ten years have in store.
Thanks to all the work and reflections that led to this post from the entire DrivenData team. Happy 10 years!
Special thanks to all our partners whose examples are represented above: NASA, Bureau of Reclamation, The Nature Conservancy, The World Bank, Radiant Earth Foundation, Max Planck Institute for Environmental Anthropology, Wild Chimpanzee Foundation, WILDLABS, Patrick J. McGovern Foundation, Meta AI, Bureau of Ocean Energy Management, NOAA Fisheries, WildMe, the Global Facility for Disaster Reduction and Recovery, Microsoft, Cloud to Street, IDEO.org, MIT, VisioMel, SNOMED International, MathWorks, KU Leuven, Woods Hole Oceanographic Institution, French Society of Pathology, CABI, Candid, Fair Trade USA, GO2 for Lung Cancer, and Wellcome Trust.
DrivenData is a social enterprise that brings the power of data science and AI to organizations tackling the world’s biggest challenges. If you have a problem to solve or thoughts on this post, we’d love to hear them - drop us a line here.



















