

Processing mental health narratives with open-source LLMs¶
Welcome to the benchmark notebook for the Automated Abstraction track of Youth Mental Health Narratives challenge. For access to the data used in this benchmark notebook, sign up for the competition here.
Background¶
The National Violent Death Reporting System (NVDRS) is a dataset maintained by the Center for Disease Control's Center for Injury Prevention and Control that contains narratives from law enforcement, coroner/medical examiners, and others on suicides and violent deaths in the United States. In this challenge, participants are asked to work with a de-identified sample from the NVDRS that contains narratives of youth suicides.
The objective of the Automated Abstraction track of the Youth Mental Health Narratives challenge is to apply machine learning to automate the population of standard variables from these narratives in the NVDRS. Abstraction is currently done manually and is a time-consuming and labor-intensive process, so the outcomes of this challenge have potential to greatly improve the quality and timeliness of the data and effectiveness of the research that uses it.
In this notebook, we will demonstrate how to use an open-source Large Language Model (LLM) to perform abstraction and package the model weights and code for submission.
The approach we use here is intended to be very simple and quick to run—there are many ways to achieve better results, and we encourage you to explore and share them in the forum!
In this post, we'll cover:¶
Let's begin!
import json
from pathlib import Path
import pandas as pd
import numpy as np
from loguru import logger
import accelerate
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
import bitsandbytes as bnb
import torch
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {DEVICE}")
Explore the data¶
Let's start by retrieving and exploring the data. To get the data, first register for the Automated Abstraction track of this challenge and head on over to the data download page. We will be using a few files for this notebook:
train_features.csv: This file contains the full set of narratives that are the training set features for this competition.train_labels.csv: These are the labels for the training set.submission_format.csv: Our code must output a file that matches this format exactly in order to be scored.
For this notebook, we have downloaded competition data files to a folder called competition_data. To run the notebook, replace that path below with the path to your downloaded data.
DATA_DIR = Path("competition_data") # replace with path to your data
features = pd.read_csv(DATA_DIR / "train_features.csv", index_col="uid")
labels = pd.read_csv(DATA_DIR / "train_labels.csv", index_col="uid")
submission_format = pd.read_csv(DATA_DIR / "submission_format.csv", index_col="uid")
In this notebook, we won't be printing out any of the feature narratives. While they are deidentified, these narratives are still sensitive.
Participants in this competition are NOT allowed to share the competition data in any way, including by submitting it to an API. For example, participants cannot submit data to ChatGPT or Gemini.
The training features dataset has three columns:
uid: Unique identifier for a single caseNarrativeLE: A summary of the information in the law enforcement (LE) reportNarrativeCME: A summary of the information in the coroner/medical examiner (CME) report
In this notebook, we'll ignore NarrativeCME and use only NarrativeLE for simplicity. You may want to explore how better to consolidate information across these fields.
# explore feature data
features.shape
features.NarrativeCME.str.len().describe()
features.NarrativeLE.str.len().describe()
It looks like our narratives are about 700-800 characters long on average, but that they can go up to about 7.5k. This is good to keep in mind since longer narratives will take longer to process.
# explore labels
labels.describe().T[["mean", "50%", "min", "max"]]
It looks like all of the binary variables have some incidences of 1s and 0s, and that some of these have highly imbalanced classes. Let's get to working with the data!
Build a model pipeline¶
Prerequisites for code execution¶
This is a code execution competition, which means that you'll submit your trained model and inference code rather than predictions themselves. DrivenData will then compute predictions in the cloud in our code execution environment.
All of our code must be able to run successfully in the code execution runtime, which is subject to several constraints:
- Our submission must run using python 3.10 and the packages in the runtime repository
- It cannot take longer than 8 hours using a single NVIDIA T4 GPU with 16 GB VRAM
- Our solution cannot require network access, so we have to make sure to include all code and assets in the
submission.zipfile that we submit for scoring
The runtime repository has key resources to help you navigate code execution, including examples, the list of packages you'll be able to access in the runtime, and instructions for adding new packages to the runtime.
Selecting and loading a model¶
Participants in this competition are NOT allowed to share the competition data in any way, including by submitting it to an API. For example, participants cannot submit data to ChatGPT or Gemini. Per the external data policy, we'll download and use open-source LLM model weights in our pipeline.
We will use the relatively lightweight Mistral-7B-Instruct-v0.2 model LLM for our solution. In order to run the code in this notebook, it is best if you have a machine with a GPU (of any kind) and at least 8GB of VRAM.
Since we cannot make network calls to make predictions in our actual submission, we will need to submit all the code and model weights we need to make predictions. We're going to download the model weights and tokenizer from Mistral IA's huggingface page and save locally. Before downloading the Mistral model, you may need to:
- Set up an account on huggingface and generate a token—make sure to save this token!
- Request access to the Mistral 7B Instruct v0.2 model
- Run
huggingface_hub.login(token="<your-token>")
We will also be using a quantized version of our model, which means that instead of using a high-precision data type like 32-bit floating-point numbers in our model weights, we're opting to use 4-bit integers, a lower-precision data type. This helps reduce memory usage and can speed up model execution while slightly reducing accuracy.
BitsAndBytesConfig is a commonly used tool for quantizing models to 8- and 4-bit. Below, we're downloading our model from huggingface and specifying that we want to use 4-bit quantization. We're downloading to a folder called "assets".
MODEL_DIR = Path("assets")
MODEL_DIR.mkdir(exist_ok=True, parents=True)
def save_model(device, model_name="mistralai/Mistral-7B-Instruct-v0.2"):
logger.info(f"Using device {device} to save model to {MODEL_DIR}")
# use 4-bit quantization
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
)
logger.info("Downloading model")
model = AutoModelForCausalLM.from_pretrained(
model_name, quantization_config=quantization_config, device_map=device
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
logger.info(f"Saving model to {MODEL_DIR}")
model.save_pretrained(MODEL_DIR)
tokenizer.save_pretrained(MODEL_DIR)
logger.success("Model and tokenizer saved")
if not (MODEL_DIR / "config.json").exists():
logger.info("Downloading model")
save_model(DEVICE)
else:
logger.info("Using existing local model")
You can specify many additional parameters in from_pretrained here in addition to quantization_config—feel free to explore the other options here that might help optimize your model.
Now that we've downloaded our model, we'll load it using the saved weights. If your submission uses pre-trained model weights, this is what it should do in the code execution runtime.
logger.info(f"Loading model from {MODEL_DIR}, {MODEL_DIR.exists()}")
model = AutoModelForCausalLM.from_pretrained(
MODEL_DIR, device_map=DEVICE, local_files_only=True
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR)
Building a prompt and data processing functions¶
Now that we've downloaded our model weights, and loaded the model, we'll want to define a prompt that parses the law enforcement narrative and returns values for the standard variables. We've provided a basic prompt here that defines:
- A role - an abstractor that takes narratives and returns values for the binary and categorical variables
- Lists of the variables we expect output for
- Options for the variable values
- Expected output format
- Example input and output
There are a lot of resources out there on building prompts—we encourage you to tinker! This page from huggingface is a good starting resource.
PROMPT_TEMPLATE = """You are an expert abstractor who reads law enforcement narratives about youth suicide and extracts variables that represent common patterns. The variables you are extracting are either binary (0 or 1) or categorical. Use the example input and output for the list of all variables to return.
There are two categorical variables, specified below. For categorical variables, return ONE of the possible values specified in the semicolon-separated list.
VARIABLE: InjuryLocationType
- POSSIBLE VALUES: House, apartment; Motor vehicle (excluding school bus and public transportation); Natural area (e.g., field, river, beaches, woods); Street/road, sidewalk, alley; Park, playground, public use area; Other
VARIABLE: WeaponType1
- POSSIBLE VALUES: Firearm; Hanging, strangulation, suffocation; Poisoning; Fall; Other transport vehicle, eg, trains, planes, boats; Motor vehicle including buses, motorcycles; Drowning; Sharp instrument; Fire or burns; Blunt instrument; Unknown; Other (e.g. taser, electrocution, nail gun)
All other variables are binary. For binary variables, Return a 0 if the item represented by the variable is absent and 1 if the item represented by the variable is present. The binary variables are:
- DepressedMood
- MentalIllnessTreatmentCurrnt
- HistoryMentalIllnessTreatmnt
- SuicideAttemptHistory
- SuicideThoughtHistory
- SubstanceAbuseProblem
- MentalHealthProblem
- DiagnosisAnxiety
- DiagnosisDepressionDysthymia
- DiagnosisBipolar
- DiagnosisAdhd
- IntimatePartnerProblem
- FamilyRelationship
- Argument
- SchoolProblem
- RecentCriminalLegalProblem
- SuicideNote
- SuicideIntentDisclosed
- DisclosedToIntimatePartner
- DisclosedToOtherFamilyMember
- DisclosedToFriend
You should output properly formatted json object where the keys are variable names and the values are predicted values for the given narrative. Do NOT output anything other than the JSON object. Do not include any explanation or summaries. Do not include any keys in this json object that aren't specified in the list.
-------------
EXAMPLE INPUT:
XX XX V found deceased at home by his grandparents, hanging from a basketball hoop in his basement family room. According to LE, a check of V's cell phone revealed that V had made suicidal statements by phone earlier. In the text message V sent to his girlfriend, he had stated that he was going to hang himself.
EXAMPLE OUTPUT:
{{"DepressedMood": 0,
"MentalIllnessTreatmentCurrnt": 0,
"HistoryMentalIllnessTreatmnt": 0,
"SuicideAttemptHistory": 0,
"SuicideThoughtHistory": 0,
"SubstanceAbuseProblem": 0,
"MentalHealthProblem": 0,
"DiagnosisAnxiety": 0,
"DiagnosisDepressionDysthymia": 0,
"DiagnosisBipolar": 0,
"DiagnosisAdhd": 0,
"IntimatePartnerProblem": 0,
"FamilyRelationship": 0,
"Argument": 0,
"SchoolProblem": 0,
"RecentCriminalLegalProblem": 0,
"SuicideNote": 0,
"SuicideIntentDisclosed": 1,
"DisclosedToIntimatePartner": 1,
"DisclosedToOtherFamilyMember": 0,
"DisclosedToFriend": 0,
"InjuryLocationType": "House, apartment",
"WeaponType1": "Hanging, strangulation, suffocation"
}}
-------------
INPUT:
{}
OUTPUT:
"""
In this approach, we'll be batching our inputs in order to speed up prediction time (not all LLM pipelines will use batching). We're going to order the batches by increasing narrative length—within a batch, all the prompts must the same length, so grouping those that are similar in length minimizes the amount of padding needed to achieve equal length.
def process_features(features):
"""
Order features by ascending string length
"""
features["str_len"] = features.NarrativeLE.str.len()
features = features.sort_values(by="str_len")
return features.drop(columns=["str_len"])
def batch_features(features, batch_size: int):
"""
Batch features together
"""
if len(features) > batch_size:
return np.array_split(features, int(len(features) / batch_size))
return [features]
A padding token is used to fill shorter inputs in a batch to match the longest input's size, which ensures consistency in input size. Here, we're just using the end-of-sequence token as the padding token.
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
Generating model output¶
Now that we've defined a batching method and a padding method, let's go ahead and batch our narratives and pass them into the model to see what the output looks like!
BATCH_SIZE = 10
MAX_NEW_TOKENS = 300
def predict_on_batch(feature_batch, model, tokenizer):
"""
Tokenize input batches, generate and decode outputs
"""
# Tokenize input narratives (NarrativeLE) in batch
prompts = [PROMPT_TEMPLATE.format(nar) for nar in feature_batch.NarrativeLE]
inputs = tokenizer(prompts, return_tensors="pt", padding=True)
inputs.to("cuda")
# Generate outputs for variables
outputs = model.generate(
inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=MAX_NEW_TOKENS,
)
decoded = tokenizer.batch_decode(outputs, skip_special_tokens=True)
# Remove prompt from output
decoded = [resp[len(prompt) :] for resp, prompt in zip(decoded, prompts)]
return decoded
# Batch inputs - note - we're running an example of 5 in this notebook
df = process_features(features.iloc[:5])
data_batches = batch_features(df, BATCH_SIZE)
responses = []
idxs = []
logger.info(f"Iterating over {len(data_batches)} batches")
for ix, data_batch in enumerate(data_batches):
logger.info(f"Generating predictions on batch {ix}, with {len(data_batch)} samples")
responses += predict_on_batch(data_batch, model, tokenizer)
idxs += list(data_batch.index)
logger.info(f"Finished inference")
interim_preds = pd.DataFrame({"string_output": responses}, index=df.index)
print(responses[0])
Parse model outputs into submission-ready format¶
We need to adjust our output to adhere to the submission format, which requires that we output a file called submission_format.csv with 24 columns in the order and data types specified. In order to produce a clean CSV from our output JSON, we need to make sure that we don't have any characters like line breaks or extra brackets. This was sufficient cleaning for the purposes of this notebook, but you may need to find or develop a different approach for your submission.
def parse_response(output):
"""
Transform response into a json object using minimal cleaning
"""
try:
# Try loading the raw string into
resp = json.loads(output)
return resp
except json.JSONDecodeError:
pass
try:
# Get rid of extra trailing sections that follow "--"
split_output = output.split("--")[0]
resp = json.loads(split_output)
return resp
except json.JSONDecodeError:
pass
try:
# Get rid of sections that follow the a closing bracket "}"
split_output = output.split("}")[0] + "}"
resp = json.loads(split_output)
return resp
except json.JSONDecodeError:
logger.warning(f"Failed to parse {output} into valid json")
return None
The submission format also specifies that outputs for the categorical variables InjuryLocationType and WeaponType1 should be coded as integers. We'll transform the output from the prompt to their corresponding integers and fill in "Other" as a default response if the model generated an invalid response.
def process_injury_location(data: pd.Series):
"""
Transform InjuryLocationType model output to integers,
fill in default for invalid outputs
"""
ilt = data.map(
{
"House, apartment": 1,
"Motor vehicle (excluding school bus and public transportation)": 2,
"Natural area (e.g., field, river, beaches, woods)": 3,
"Park, playground, public use area": 4,
"Street/road, sidewalk, alley": 5,
"Other": 6,
"Residence": 1,
"Apartment": 1,
}
)
if ilt.isna().any():
logger.warning(
f"There are unexpected values in injury location: {data[ilt.isna()].unique()} "
)
ilt = ilt.fillna(6) # Fill with other
return ilt.astype(int)
def process_weapon_type(data: pd.Series):
"""
Transform WeaponType1 model output to integers,
fill in default for invalid outputs
"""
wt = data.map(
{
"Blunt instrument": 1,
"Drowning": 2,
"Fall": 3,
"Fire or burns": 4,
"Firearm": 5,
"Hanging, strangulation, suffocation": 6,
"Motor vehicle including buses, motorcycles": 7,
"Other transport vehicle, eg, trains, planes, boats": 8,
"Poisoning": 9,
"Sharp instrument": 10,
"Other (e.g. taser, electrocution, nail gun)": 11,
"Unknown": 12,
}
)
if wt.isna().any():
logger.warning(
f"There are unexpected values in weapon type: {data[wt.isna()].unique()} "
)
wt = wt.fillna(11) # Fill with other
return wt.astype(int)
Let's parse our output and see our submission-ready solution! Note that here we are filling in simple placeholder values for any response we can't parse for expediency, but that a high-performing solution would probably handle these responses with a more informed approach.
idxs = []
parsed_resps = []
could_not_parse = []
for row in interim_preds.itertuples():
parsed = parse_response(row.string_output)
if type(parsed) == dict:
idxs.append(row.Index)
parsed_resps.append(parsed)
else:
idxs.append(row.Index)
could_not_parse.append(row.Index)
# Fill any we couldn't parse with placeholder values for now
parsed_resps.append(
{
"DepressedMood": 0,
"IntimatePartnerProblem": 0,
"FamilyRelationship": 0,
"Argument": 0,
"MentalIllnessTreatmentCurrnt": 0,
"HistoryMentalIllnessTreatmnt": 0,
"SuicideAttemptHistory": 0,
"SuicideThoughtHistory": 0,
"SuicideNote": 0,
"SubstanceAbuseProblem": 0,
"SchoolProblem": 0,
"RecentCriminalLegalProblem": 0,
"SuicideIntentDisclosed": 0,
"DisclosedToIntimatePartner": 0,
"DisclosedToOtherFamilyMember": 0,
"DisclosedToFriend": 0,
"MentalHealthProblem": 0,
"DiagnosisAnxiety": 0,
"DiagnosisDepressionDysthymia": 0,
"DiagnosisBipolar": 0,
"DiagnosisAdhd": 0,
"WeaponType1": "Unknown",
"InjuryLocationType": "Other",
}
)
if len(could_not_parse) > 0:
logger.warning(
f"Could not parse {len(could_not_parse)} rows. Indices: {could_not_parse}"
)
parsed_preds = pd.DataFrame(parsed_resps, index=pd.Index(idxs, name="uid")).fillna(0)
parsed_preds["InjuryLocationType"] = process_injury_location(
parsed_preds.InjuryLocationType
)
parsed_preds["WeaponType1"] = process_weapon_type(parsed_preds.WeaponType1)
# Make sure the column order is the same as in the submission format
parsed_preds = parsed_preds[submission_format.columns]
# Make sure the row order is the same as in the submission format
parsed_preds = parsed_preds.loc[features[:5].index]
# Make sure all values are int
parsed_preds = parsed_preds.round().astype(int)
parsed_preds.head()
Let's do a few checks to make sure that our submission is valid.
# Columns are in the correct order
assert (submission_format.columns == parsed_preds.columns).all().all()
# All columns are of type int
assert (parsed_preds.dtypes == int).all()
# Variables have values within the expected range
assert parsed_preds.iloc[:, 0:-2].isin([0, 1]).all().all()
assert (parsed_preds["InjuryLocationType"].isin(range(1, 7))).all()
assert (parsed_preds["WeaponType1"].isin(range(1, 13))).all()
Code execution submission¶
Now that we're confident that our code produces a valid submission, let's package it together with our model weights into a file called submission.zip. The general steps to follow for submitting are:
- Create a properly formatted
submission.zip - Test your submission locally in Docker
- Make a smoke test submission
- Once you have succesfully debugged your submission with steps 2 and 3, submit for scoring on the full test set!
The runtime repository has a section on testing submissions that we're following here.
First, let's make sure we have all the prerequisites to test our submission locally on our machine:
- A clone of this repository
- Docker
- At least 5 GB of free space for the CPU version of the Docker image or at least 15 GB of free space for the GPU version
- GNU make (optional, but useful for running the commands in the Makefile)
Additional requirements to run with GPU:
- NVIDIA drivers with CUDA 11
- NVIDIA container toolkit
Check! Now, let's navigate to the runtime repository and run make pull at the root of the repo to pull down the official Docker image (this contains the exact environment that our submission runs in when we submit it to the platform). This might take some time.
>> make pull
docker pull cdcnarratives.azurecr.io/cdc-narratives-competition:gpu-latest
gpu-latest: Pulling from cdc-narratives-competition
43f89b94cd7d: Pulling fs layer
...
...
...Once this is done, let's put our code and model assets in submission_src/, set up in the same way as example_submission/:
submission_src
├── assets
| ├── assets/model.safetensors
| ├── assets/generation_config.json
| ├── assets/tokenizer.json
| └── ... # other downloadeded model files
└── main.pyOur submission must include a main.py file at the root level of submission.zip that reads in the test features and generates predictions. You are welcome to include multiple python scripts and import functions into main.py. For simplicity, we have put all of our required code into the main.py script.
The script belows shows a properly formatted main.py file that runs our model pipeline:
# Valid main.py file
import json
from pathlib import Path
import pandas as pd
import numpy as np
from loguru import logger
import accelerate
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
import bitsandbytes as bnb
import torch
SUBMISSION_PATH = Path("submission.csv")
FEATURES_PATH = Path("data/test_features.csv")
SUBMISSION_FORMAT_PATH = Path("data/submission_format.csv")
MODEL_DIR = Path("assets")
MAX_NEW_TOKENS = 350
PROMPT_TEMPLATE = """You are an expert abstractor who reads law enforcement narratives about youth suicide and extracts variables that represent common patterns. The variables you are extracting are either binary (0 or 1) or categorical. Use the example input and output for the list of all variables to return.
There are two categorical variables, specified below. For categorical variables, return ONE of the possible values specified in the semicolon-separated list.
VARIABLE: InjuryLocationType
- POSSIBLE VALUES: House, apartment; Motor vehicle (excluding school bus and public transportation); Natural area (e.g., field, river, beaches, woods); Street/road, sidewalk, alley; Park, playground, public use area; Other
VARIABLE: WeaponType1
- POSSIBLE VALUES: Firearm; Hanging, strangulation, suffocation; Poisoning; Fall; Other transport vehicle, eg, trains, planes, boats; Motor vehicle including buses, motorcycles; Drowning; Sharp instrument; Fire or burns; Blunt instrument; Unknown; Other (e.g. taser, electrocution, nail gun)
All other variables are binary. For binary variables, Return a 0 if the item represented by the variable is absent and 1 if the item represented by the variable is present. The binary variables are:
- DepressedMood
- MentalIllnessTreatmentCurrnt
- HistoryMentalIllnessTreatmnt
- SuicideAttemptHistory
- SuicideThoughtHistory
- SubstanceAbuseProblem
- MentalHealthProblem
- DiagnosisAnxiety
- DiagnosisDepressionDysthymia
- DiagnosisBipolar
- DiagnosisAdhd
- IntimatePartnerProblem
- FamilyRelationship
- Argument
- SchoolProblem
- RecentCriminalLegalProblem
- SuicideNote
- SuicideIntentDisclosed
- DisclosedToIntimatePartner
- DisclosedToOtherFamilyMember
- DisclosedToFriend
You should output properly formatted json object where the keys are variable names and the values are predicted values for the given narrative. Do NOT output anything other than the JSON object. Do not include any explanation or summaries. Do not include any keys in this json object that aren't specified in the list.
-------------
EXAMPLE INPUT:
XX XX V found deceased at home by his grandparents, hanging from a basketball hoop in his basement family room. According to LE, a check of V's cell phone revealed that V had made suicidal statements by phone earlier. In the text message V sent to his girlfriend, he had stated that he was going to hang himself.
EXAMPLE OUTPUT:
{{"DepressedMood": 0,
"MentalIllnessTreatmentCurrnt": 0,
"HistoryMentalIllnessTreatmnt": 0,
"SuicideAttemptHistory": 0,
"SuicideThoughtHistory": 0,
"SubstanceAbuseProblem": 0,
"MentalHealthProblem": 0,
"DiagnosisAnxiety": 0,
"DiagnosisDepressionDysthymia": 0,
"DiagnosisBipolar": 0,
"DiagnosisAdhd": 0,
"IntimatePartnerProblem": 0,
"FamilyRelationship": 0,
"Argument": 0,
"SchoolProblem": 0,
"RecentCriminalLegalProblem": 0,
"SuicideNote": 0,
"SuicideIntentDisclosed": 1,
"DisclosedToIntimatePartner": 1,
"DisclosedToOtherFamilyMember": 0,
"DisclosedToFriend": 0,
"InjuryLocationType": "House, apartment",
"WeaponType1": "Hanging, strangulation, suffocation"
}}
-------------
INPUT:
{}
OUTPUT:
"""
def load_model():
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
logger.info(f"Loading model from {MODEL_DIR}, {MODEL_DIR.exists()}")
model = AutoModelForCausalLM.from_pretrained(
MODEL_DIR, device_map=DEVICE, local_files_only=True
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR)
return model, tokenizer
def process_features(features):
"""
Order features by ascending string length
"""
features["str_len"] = features.NarrativeLE.str.len()
features = features.sort_values(by="str_len")
return features.drop(columns=["str_len"])
def batch_features(features, batch_size: int):
"""
Batch features together
"""
if len(features) > batch_size:
return np.array_split(features, int(len(features) / batch_size))
return [features]
def predict_on_batch(feature_batch, model, tokenizer):
"""
Tokenize input batches, generate and decode outputs
"""
# Tokenize input narratives (NarrativeLE) in batch
prompts = [PROMPT_TEMPLATE.format(nar) for nar in feature_batch.NarrativeLE]
inputs = tokenizer(prompts, return_tensors="pt", padding=True)
inputs.to("cuda")
# Generate outputs for variables
outputs = model.generate(
inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=MAX_NEW_TOKENS,
)
decoded = tokenizer.batch_decode(outputs, skip_special_tokens=True)
# Remove prompt from output
decoded = [resp[len(prompt) :] for resp, prompt in zip(decoded, prompts)]
return decoded
def parse_response(output):
"""
Transform response into a json object using minimal cleaning
"""
try:
# Try loading the raw string into
resp = json.loads(output)
return resp
except json.JSONDecodeError:
pass
try:
# Get rid of extra trailing sections that follow "--"
split_output = output.split("--")[0]
resp = json.loads(split_output)
return resp
except json.JSONDecodeError:
pass
try:
# Get rid of sections that follow the a closing bracket "}"
split_output = output.split("}")[0] + "}"
resp = json.loads(split_output)
return resp
except json.JSONDecodeError:
logger.warning(f"Failed to parse {output} into valid json")
return None
def process_injury_location(data: pd.Series):
"""
Transform InjuryLocationType model output to integers, fill in default for invalid outputs
"""
ilt = data.map(
{
"House, apartment": 1,
"Motor vehicle (excluding school bus and public transportation)": 2,
"Natural area (e.g., field, river, beaches, woods)": 3,
"Park, playground, public use area": 4,
"Street/road, sidewalk, alley": 5,
"Other": 6,
"Residence": 1,
"Apartment": 1,
}
)
if ilt.isna().any():
logger.warning(
f"There are unexpected values in injury location: {data[ilt.isna()].unique()} "
)
ilt = ilt.fillna(6) # Fill with other
return ilt.astype(int)
def process_weapon_type(data: pd.Series):
"""
Transform WeaponType1 model output to integers, fill in default for invalid outputs
"""
wt = data.map(
{
"Blunt instrument": 1,
"Drowning": 2,
"Fall": 3,
"Fire or burns": 4,
"Firearm": 5,
"Hanging, strangulation, suffocation": 6,
"Motor vehicle including buses, motorcycles": 7,
"Other transport vehicle, eg, trains, planes, boats": 8,
"Poisoning": 9,
"Sharp instrument": 10,
"Other (e.g. taser, electrocution, nail gun)": 11,
"Unknown": 12,
}
)
if wt.isna().any():
logger.warning(
f"There are unexpected values in weapon type: {data[wt.isna()].unique()} "
)
wt = wt.fillna(11) # Fill with other
return wt.astype(int)
def generate_predictions(features: pd.DataFrame, submission_format: pd.DataFrame) -> pd.DataFrame:
# Load model
model, tokenizer = load_model()
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
# Batch inputs
BATCH_SIZE = 10
df = process_features(features)
data_batches = batch_features(df, BATCH_SIZE)
responses = []
idxs = []
logger.info(f"Iterating over {len(data_batches)} batches")
for ix, data_batch in enumerate(data_batches):
logger.info(f"Generating predictions on batch {ix}, with {len(data_batch)} samples")
responses += predict_on_batch(data_batch, model, tokenizer)
idxs += list(data_batch.index)
logger.info(f"Finished inference")
interim_preds = pd.DataFrame({"string_output": responses}, index=df.index)
# Get submission-ready solution
idxs = []
parsed_resps = []
could_not_parse = []
for row in interim_preds.itertuples():
parsed = parse_response(row.string_output)
if type(parsed) == dict:
idxs.append(row.Index)
parsed_resps.append(parsed)
else:
idxs.append(row.Index)
could_not_parse.append(row.Index)
# Fill any we couldn't parse with placeholder values for now
parsed_resps.append(
{
"DepressedMood": 0,
"IntimatePartnerProblem": 0,
"FamilyRelationship": 0,
"Argument": 0,
"MentalIllnessTreatmentCurrnt": 0,
"HistoryMentalIllnessTreatmnt": 0,
"SuicideAttemptHistory": 0,
"SuicideThoughtHistory": 0,
"SuicideNote": 0,
"SubstanceAbuseProblem": 0,
"SchoolProblem": 0,
"RecentCriminalLegalProblem": 0,
"SuicideIntentDisclosed": 0,
"DisclosedToIntimatePartner": 0,
"DisclosedToOtherFamilyMember": 0,
"DisclosedToFriend": 0,
"MentalHealthProblem": 0,
"DiagnosisAnxiety": 0,
"DiagnosisDepressionDysthymia": 0,
"DiagnosisBipolar": 0,
"DiagnosisAdhd": 0,
"WeaponType1": "Firearm",
"InjuryLocationType": "House, apartment",
}
)
if len(could_not_parse) > 0:
logger.warning(
f"Could not parse {len(could_not_parse)} rows. Indices: {could_not_parse}"
)
parsed_preds = pd.DataFrame(parsed_resps, index=pd.Index(idxs, name="uid")).fillna(0)
parsed_preds["InjuryLocationType"] = process_injury_location(
parsed_preds.InjuryLocationType
)
parsed_preds["WeaponType1"] = process_weapon_type(parsed_preds.WeaponType1)
# Make sure column order is the same as in the submission format
parsed_preds = parsed_preds[submission_format.columns]
# Make sure the row order is the same as in the submission format
parsed_preds = parsed_preds.loc[features.index]
# Make sure all values are int and not NaN
parsed_preds = parsed_preds.round().astype(int)
return parsed_preds
def main():
features = pd.read_csv(FEATURES_PATH, index_col=0)
print(f"Loaded test features of shape {features.shape}")
submission_format = pd.read_csv(SUBMISSION_FORMAT_PATH, index_col=0)
print(f"Loaded submission format of shape: {submission_format.shape}")
# Generate predictions
predictions = generate_predictions(features, submission_format)
print(f"Saving predictions of shape {predictions.shape} to {SUBMISSION_PATH}")
predictions.to_csv(SUBMISSION_PATH, index=True)
if __name__ == "__main__":
main()
Then, we'll run make pack-submission to zip everything into a submission.zip file that we can submit.
>> make pack-submission
>> mkdir -p submission/
>> cd submission_src; zip -r ../submission/submission.zip ./*
adding: assets/ (stored 0%)
adding: assets/model.safetensors (deflated 14%)
adding: assets/generation_config.json (deflated 21%)
adding: assets/tokenizer.json (deflated 74%)
adding: assets/tokenizer_config.json (deflated 67%)
adding: assets/tokenizer.model (deflated 55%)
adding: assets/special_tokens_map.json (deflated 74%)
adding: assets/config.json (deflated 54%)
adding: main.py (deflated 68%)Testing a submission locally¶
Once we have a submission.zip file that conforms to the requirements, we can run make test-submission to spin up a docker container that uses the same image as the competition runtime, ingests our submission.zip, and runs our submitted code using our assets against the test features. Note that in order for this command to work locally, the data/ folder should have both features and labels. Let's follow the instructions in the runtime repository:
- Let's download
smoke_test_features.csvtodata/test_features.csvandsmoke_test_labels.csvtodata/smoke_test_labels.csv. Let's also copy the labels todata/submission_format.csv. - Then, let's run
make test-submissionas before. (This will replace thesubmission/submission.csvfrom previous tests). - Finally, let's run
python src/scoring.py submission/submission.csv data/smoke_test_labels.csvto generate our F1-score.
>> make test-submission
Using image: cdcnarratives.azurecr.io/cdc-narratives-competition
...
...
...
Exporting submission.csv result...
+ '[' -f submission.csv ']'
+ echo 'Script completed its run.'
Script completed its run.
+ cp submission.csv ./submission/submission.csv
+ exit_code=0
+ cp /code_execution/submission/log.txt /tmp/log
+ exit 0>> python src/scoring.py submission/submission.csv data/smoke_test_labels.csv
Variable-averaged F1 score: 0.5850We have a score of 0.5850!
Make a smoke test submission¶
Success! Let's submit our submission.zip to a smoke test on the platform to make sure that we get the same score.
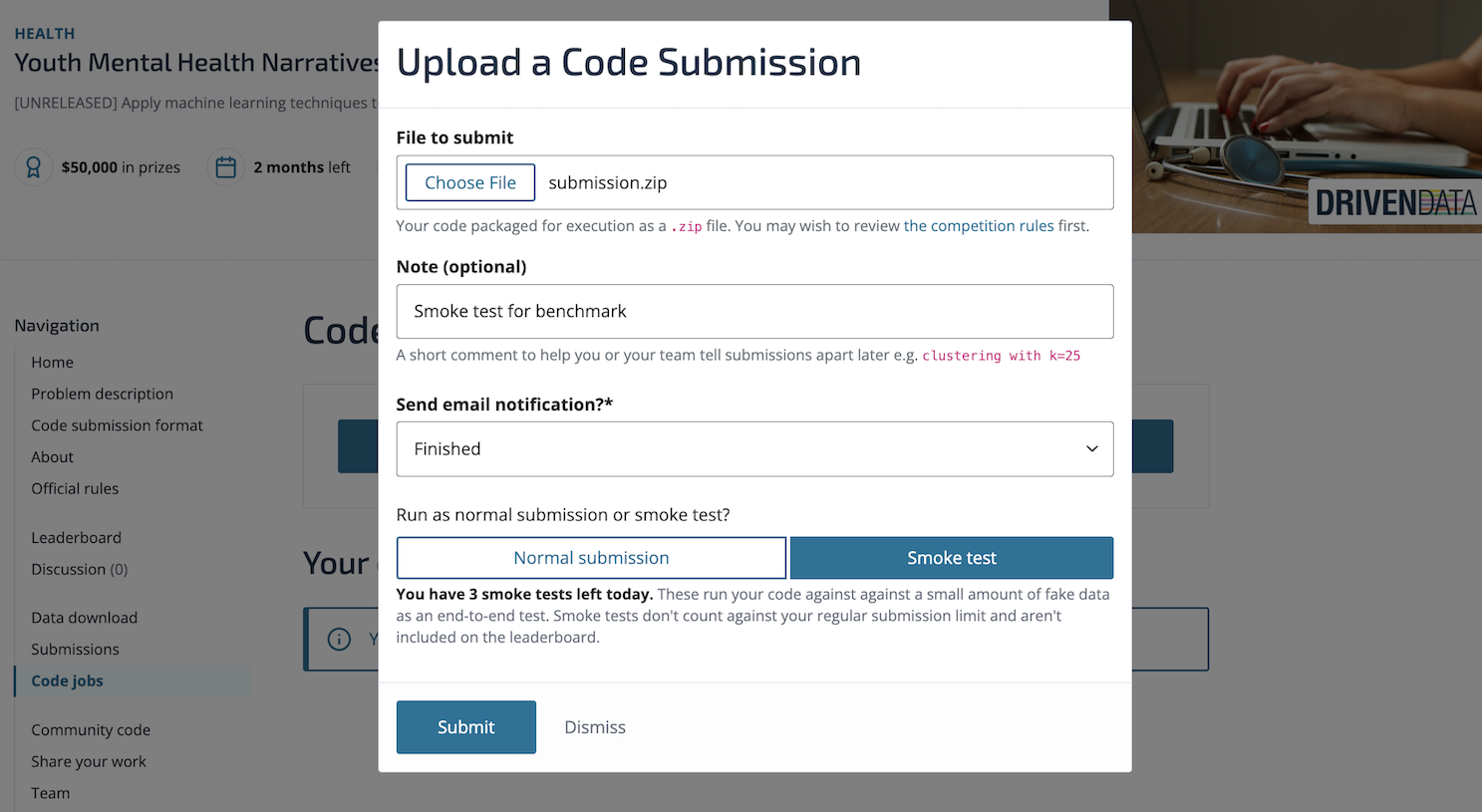
After hitting "Submit" you can see the job in the queue—it will progress from "Pending" to "Starting" to "Running":
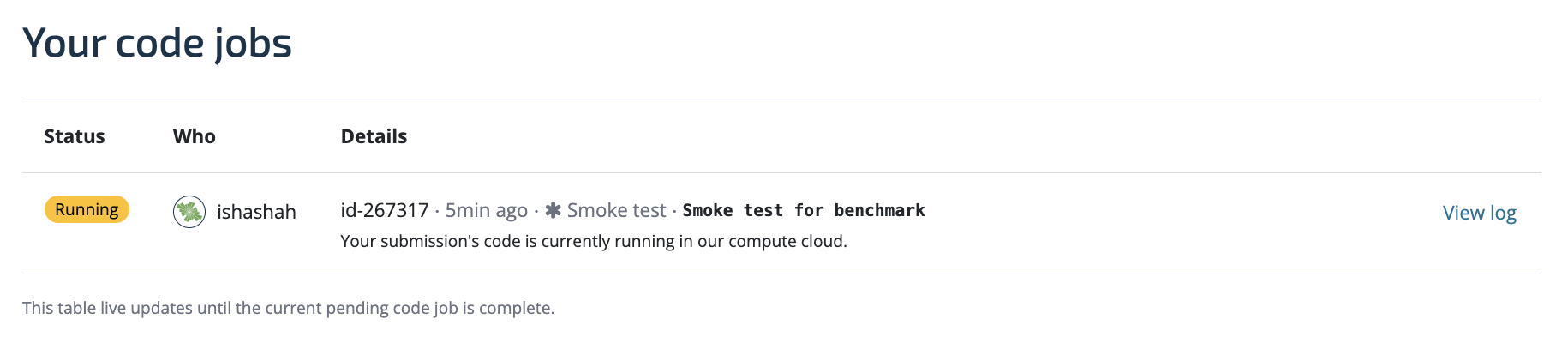
The "code jobs" page is also you can see logs from your smoke test and debug anything that went wrong. Logs will be available for smoke tests, but not for full submissions.
Once your submission reaches "Completed", head on over to the "Submissions" tab—you should be able to see the same score as the one you saw when you tested locally!

You'll notice that the code job IDs in these two screenshots here are different—that's because we realized the first was going to fail because of a code error and canceled it! We encourage you to also be mindful of the submission limit (3 per day at most) and others' code jobs. Canceled jobs do not count against the submission limit, and the more conscientious everyone is about canceling jobs they know will exceed the time limit (8 hours) or fail, the faster everyone's submissions will run. Logging is enabled when submitting smoke tests to help you debug, but will be turned off for full-length submissions.
Smoke tests can help you debug errors and check that your full-length submission will complete within the 8-hour time limit. Smoke tests use data from 25 training samples, while the full submission will predict on the test set of 1,000 samples. The maximum time allowed for a smoke test submission is 10 minutes; this mirrors the amount of time given per sample on the full test set.
Further exploration¶
This is just one of nearly infinite approaches you could take for this challenge! Other approaches might include:
- Using other open-source models and processing methods (including improvements on the batching method we used above and hyperparameter tuning)
- Improving the prompt
- Using the NVDRS coding manual for Retrieval Augmented Generation (RAG), or incorporating any other data sources that are freely and publicly accessible.
- Fine-tuning a model
- Combining a variety of approaches, including some that don't include LLMs, in order to make best use of the limited submission time
If you want to share any of your findings or have questions, feel free to post on the community forum.
Good luck!



















