

Background¶
Inspector spacecraft, like NASA's Seeker, are designed to conduct low-cost in-space inspections of other spacecraft. They typically have limited computing resources, but complex computing demands. Minimally, the inspector spacecraft (also called a "chaser") must locate a target spacecraft and maneuver around it while maintaining an understanding of its spatial pose. Seeker was a successful proof of concept for a low-cost inspector spacecraft that used an algorithm trained on just one type of spacecraft.
In the Pose Bowl Challenge, solvers helped advance this line of work by competing to develop solutions for in-space inspection. The data for this challenge were simulated images of spacecraft taken from a nearby location in space, as if from the perspective of a chaser spacecraft. Images were created using the open-source 3D software Blender using models of representative target host spacecraft against simulated backgrounds.
In the Object Detection track, solvers developed solutions to detect generic target spacecraft (instead of just one type) from images of them in taken space. Challenge labels were the bounding box coordinates for the spacecraft in an image.

In the Pose Estimation track, solvers worked to determine the relative pose of the inspector spacecraft camera across a sequence of images of generic target spacecraft. Challenge labels were the transformation vector (x, y, z, qw, qx, qy, qz) required to return the chaser spacecraft to its initial position in the chain.
In addition, the top three solutions from both tracks were tested on the actual hardware used on chasers (UP-CHT01-A20-0464-A11). Real Hardware Speed Bonus prizes were given to the prize-winning solutions from each track that made the fastest inferences on a representative test.
Solution constraints¶
To match the inherent constraints of in-space inspection, solvers in both challenge tracks were required to develop models that would be performant enough under real conditions on a highly constrained compute hardware.
Solvers' solutions could not use GPUs and were limited to using just 3 cores and 4 GB of RAM. They could not process images in parallel, as to match the conditions of receiving imagery from a real camera. On top of these constraints, models had to be fast enough for real guidance, navigation, and control needs—about 1 second per image in the Detection track and 5 seconds per image in the Pose Estimation track.
Results¶
This challenge drew 836 participants from 87 countries. Collectively, participants submitted 1,625 solutions. All submitted solutions were automatically evaluated in two private test sets. One test set was used to calculate a public leaderboard score that participants saw during the challenge. The other test set was used to calculate a private leaderboard score that was revealed at the end of the challenge and determined final prize rankings.
In the Object Detection track, nearly 100 solutions outperformed the benchmark model. The top scoring model achieved a Jaccard index of 0.93; the predicted bounding boxes produced by the winning model had a 93% overlap with the actual bounding boxes. The top object detection solutions converged on YOLOv8 as the best approach for low-resource object detection. Two of the three winning teams generated new synthetic images for training, which improved final models.
The Pose Estimation track turned out to be incredibly difficult, severely challenging solvers in building accurate models. Ultimately, solvers were only able to make limited progress during the competition. Only 8 teams were able to beat the benchmark error score of 2.0 for predicting a stationary spacecraft, with the top solution managing to score 1.90. Top solutions explored some interesting directions. The first- and third-place solutions leveraged classical computer vision feature matching techniques as part of their models, while the second-place solution developed a Siamese network model with a metric learning approach.
The winners' full submissions are available in an open-source Github repository for anyone to learn from.
Meet the winners - Object Detection¶
Some responses have been edited for conciseness. Each team's full, unedited writeup is linked below.
Ammar Ali, Jaafar Mahmoud, and Alexander Chigorin¶



Place: 1st
Prize: $5,000
Team name: Polynome Team
Usernames: Ammarali32, Jaafar, aachigorin
Background:
Ammar Ali: I am currently pursuing my PhD degree in Applied Computer Science at ITMO University, and I am in my third year of the program. In addition to my academic pursuits, I hold a senior researcher position at Polynome , where I focus on the development of multilingual large language models for rare languages, including Arabic. My expertise encompasses both computer vision and natural language processing.
Jaafar Mahmoud: I am a researcher and developer specializing in robotic vision. I hold an MSc in Intellectual Robotics and am expected to defend my PhD this year, focusing on robust localization. With around 5 years of professional experience, my expertise lies primarily in 3D perception, localization and mapping for robots.
Alexander Chigorin: As the Research Director at VisionLabs UAE, I am responsible for overseeing multiple research initiatives. My primary focus is on advancing the core metrics of our projects, consistently achieving results that are on par with or surpass the current state-of-the-art (SOTA). I actively work towards integrating these improvements into our products. My primary areas of research include object detection and human pose estimation.
Summary of approach:
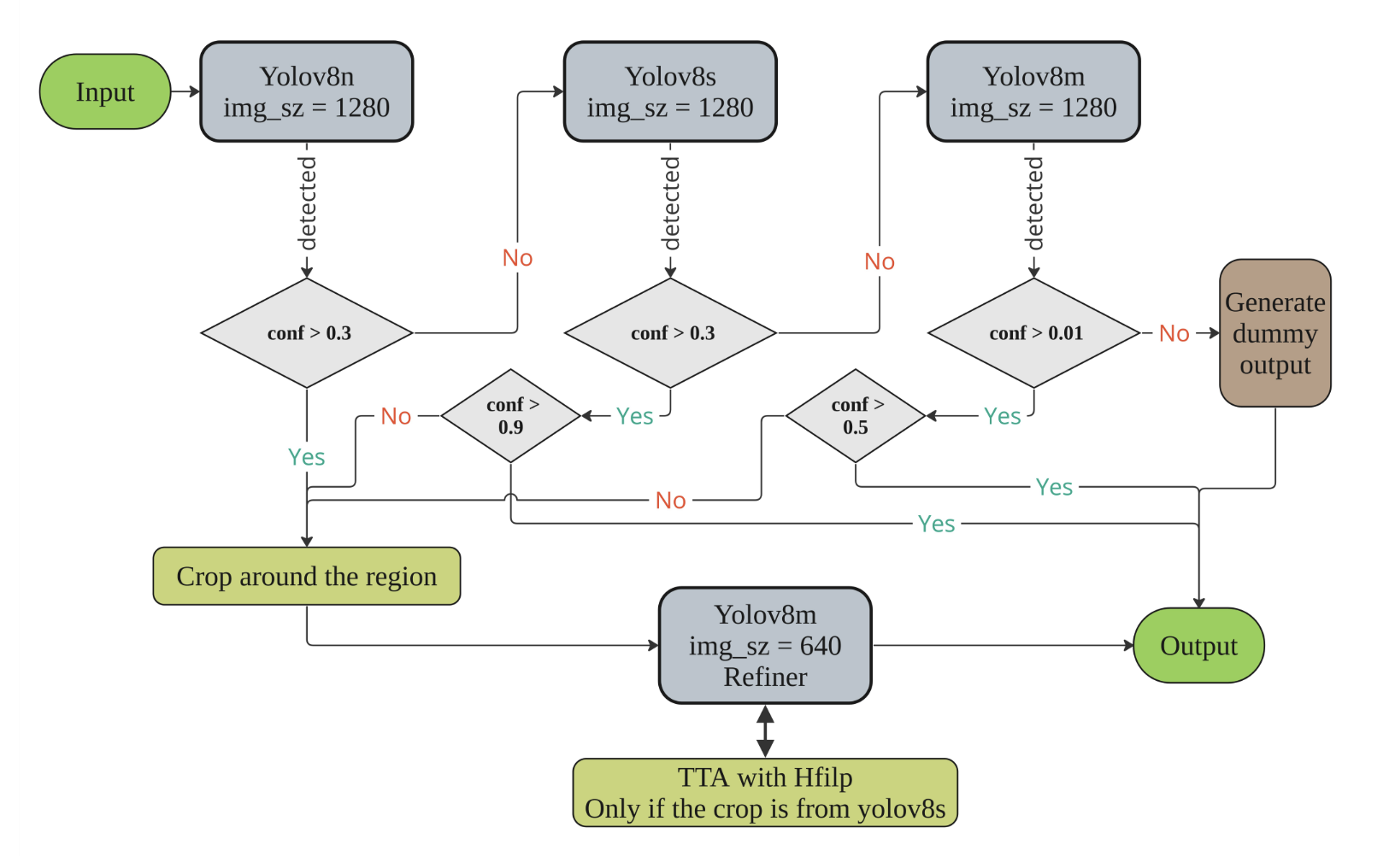
Our proposed solution primarily uses Yolov8, with three distinct iterations (nano, small, and medium) that have been meticulously trained. We used a sequential ensemble strategy, taking into account two crucial factors:
- The confidence threshold associated with the identified spaceship.
- The unique condition of the competition data, which ensures that each image contains precisely one spaceship, neither more nor less.
The model first identifies the region of the object, even if the mAP is low. Once the region is detected and cropped, we employ a refiner model (Yolov8m) that meticulously refines the detected object. This refiner has undergone rigorous training in two stages:
- The initial stage involved training on approximately 300,000 synthetic images. The background for these images was generated using a diffusion model, while the spacecraft models were sourced from the provided no-background images.
- The second stage involved fine-tuning the refiner on the competition data with slightly less intense augmentations. This process ensured that the refiner model was optimized for the specific conditions of the competition.
Check out Polynome team's full write-up and solution in the challenge winners repository.
Dung Nguyen Ba¶

Place: 2nd
Bonus prize: Real hardware speed bonus
Prize total: $5,000
Username: dungnb
Social media: /in/dungnb1333/
Background:
I am a Principal AI Engineer/Tech Lead at FPT Smart Cloud, Vietnam. I have 8 years of experience in deep learning and computer vision, 1 year of experience in embedded software development and 5 years of experience in android application development. I am also a Kaggle grandmaster (6 gold medals, 4 wins).
Summary of approach:
I chose YOLOv8s 1280 for its balance of runtime constraints and high accuracy. The key of my solution were synthetic data generation, external data, and post-processing.
Synthetic Data Generation: I created 93,778 synthetic images by overlaying the no-background spacecraft images on various backgrounds with transformations. Five types of synthetic data were generated, varying spacecraft size and positioning, and adding fake antennas.
External Data: To enhance model generality, I incorporated 3,100 satellite images with masks from a CVPR paper.
Augmentation Techniques: Augmentation techniques included random and median blurs, CLAHE, grayscale, flips, brightness/contrast adjustments, and mosaic.
Post-processing: Post-processing involved selecting the highest confidence bounding boxes and padding input images if max(box_width/image_width, box_height/image_height) > 0.7 my solution would pad the input image 150px. From my experience in previous object detection competitions, YOLO is very bad with large objects.
Check out Dung Nguyen Ba's full write-up and solution in the challenge winners repository.
Ashish Kumar¶

Place: 3rd
Prize: $2,000
Username: agastya
Background:
I am a data science enthusiast and deep learning practitioner who primarily competes in data science competitions.
Summary of approach:
My solution is a single YOLOv8s model trained on an image size of 1280 for 30 epochs. YOLOv8s provides the best tradeoff between leaderboard score and inference time. I initially started the competition with YOLOv8n and an image size of 640, but the performance was very poor and the inference time was around 105 minutes. While reading the YOLOv8 documentation, I came across the OpenVINO section where the author claims a 3x increase in inference speed. I submitted the YOLOv8n model and it finished in just 30 minutes. Then, I tried YOLOv8s with an image size of 1280 and performed some manual hyperparameter tuning, which improved performance. Finally, I trained the model on the full dataset which further increased the score.
Check out Ashish Kumar's full write-up and solution in the challenge winners repository.
Meet the winners - Pose Estimation Track¶
Some responses have been edited for conciseness. Each team's full, unedited writeup is linked below.
Xindi Liu¶

Place: 1st
Prize: $10,000
Username: dylanliu
Background:
My real name is 刘欣迪 (Xindi Liu), but I usually use my online English name Dylan Liu. I’m a freelance programmer (AI related) with 6 years of experience. One of my main incomes now is prizes from data science competition platforms.
Summary of approach:
I first used opencv to extract rotation angles between images, that is, convert the image sequences into rotation sequences. The rotation sequences are then used as the feature input of the decoder part of a T5 model to train the T5 decoder with a custom loss that is the same as the official performance metric. During the training process I used a data augmentation method that disrupts the input sequences.
Extracting image features directly through deep learning will lead to serious over-fitting (because there are very few types of spacecraft), and the requirements for equipment are very high, so I converted the image sequence into the rotation sequences. The T5 model’s decoder part in the generation mode only takes one piece of feature input at a time, and the model will not use subsequent data, which perfectly met the requirements of this competition. Since the movement trajectory of the camera is relatively random, I shuffled the sequence order as a method of data augmentation.
Check out Xindi Liu's full write-up and solution in the challenge winners repository.
Ioannis Nasios¶

Place: 2nd
Prize: $8,000
Username: ouranos
Social media: /in/ioannis-nasios-58b543b0/
Background:
I am a senior data scientist at Nodalpoint Systems in Athens, Greece. I am a geologist and an oceanographer by education turned to data science through online courses and by taking part in numerous machine learning competitions.
Summary of approach:
My solution uses a small object detection model (yolo8n) trained on the Detection track dataset and then a Siamese model with EfficientNetB0 backbone.
Check out Ioannis Nasios's full write-up and solution in the challenge winners repository
Stepan Konev and Yuriy Biktairov¶


Place: 3rd
Bonus prize: Real hardware speed bonus
Prize total: $10,000
Team name: OrbitSpinnersChallengeWinners
Usernames: sdrnr, ybiktairov
Background:
Stepan Konev: I work as a Machine Learning Engineer developing recommender systems at scale. I used to work as a researcher-developer developing motion prediction module for self-driving cars and delivery robots.
Yuriy Biktairov: I am a computer science PhD student at the University of Southern California. My research primarily focuses on neural network verification techniques and motion prediction for autonomy.
Summary of approach:
Our solution is based on classic computer vision techniques and includes 3 major steps. First, we match visual features between a given target image and the base image (the first one). Given a set of matches, we recover the relative pose using a variation of the RANSAC algorithm. Finally, we validate the resulting pose and fallback to a heuristic prediction in case the reconstructed result is deemed unrealistic.
Thanks to all the challenge participants and to our winners! And thank you to NASA for sponsoring this challenge!
Thumbnail and banner image is an example image used in the Pose Estimation track. Image courtesy of NASA.



















