

Today, we're launching a new platform in collaboration with the K-12 AI Infrastructure Program. The mission is simple: build AI that actually serves students and educators.
The platform is designed to support that mission in three key ways:
- Gather and distribute core AI infrastructure comprising datasets and models.
- Ground AI advances in learning science and student outcomes through curated benchmarks.
- Build a collaborative community through challenges and community discussion forums.
To understand the platform's purpose, it's helpful to define what we mean by AI Infrastructure. The term may bring to mind datacenters, server racks, GPUs, or the massive underwater cables that form the backbone of the internet. It may bring to mind human capital, technical capacity, or governance, regulation, and privacy. Those are all important infrastructure components for AI, but they are not the layers we are focusing on to build AI that works for education.
This platform focuses on the necessary ingredients for AI model development: open datasets, models, and benchmarks. These are the digital public goods that facilitate the development and deployment of AI models. The current generation of LLMs is undeniably shaped by the data, tasks, and open-source releases that have gained the attention of AI researchers over the last 25 years. We want our AI models to be shaped by learning science, student outcomes, and the needs of classroom teachers and administrators. To make this happen, we need to build an AI development community around the datasets, models, and benchmarks that reflect these principles.
Come join us on the platform or read on to learn more about what we have built and where we are going.
Open Education Datasets for AI Development¶
AI models are only as good as the data they are trained on. To that end, we are gathering and distributing data that is AI-ready, openly available, and relevant to K-12 education. We're launching with nine open datasets you can explore on the platform, but that is just the beginning.
- Bridge: Online math tutoring conversations annotated for the type of mistake and the strategy for correction.
- DrawEduMath: Hand-drawn responses to math problems annotated with QA pairs about the students' work.
- EssayJudge: Short argumentative essays describing math or science charts annotated for lexical quality.
- FairytaleQA: Fairytale excerpts with QA pairs categorized into one of seven narrative elements.
- Grade School Math (GSM8k): 8.5k multi-step, grade-school math word problems with solutions.
- MRBench: Math tutoring dialogues with LLM responses annotated across eight pedagogical dimensions.
- SciQ: 13.7k multiple-choice science questions with supporting text, response choices, and correct answer.
- SemEval: Short-answer science questions with graded responses.
- TalkMoves: Classroom transcripts labeled for discursive teacher moves.
Beyond these, we expect to add many more datasets, both funded by our program and developed by other institutions. We are prioritizing open data, but will also have options for datasets that require gating access at different levels: datasets that require an account to access, datasets that require agreeing to specific terms, and datasets that require requesting access and explicit approval.
If you've got a dataset you think belongs on the platform, don't hesitate to reach out at k12-ai-infra@drivendata.org.
Education AI Benchmarks That Measure What Matters¶
When new models are released, frontier labs often tout progress on specific benchmarks, predefined tasks that measure model capabilities. Labs report benchmarks against measures of economically valuable work or software engineering. Despite the attention paid to how AI will change education, model performance on education-specific tasks is rarely discussed, beyond how models perform on standardized tests, which is not a measure of how effective they are as tools for students or teachers.
Today, we're launching with a benchmark called "SAGE: Science Answer Grading & Evaluation". The task is to compare student answers against a reference answer and decide if the student answer is correct, partially correct, or contradictory. The SAGE benchmark is built on the SemEval - Joint Student Response Analysis dataset.
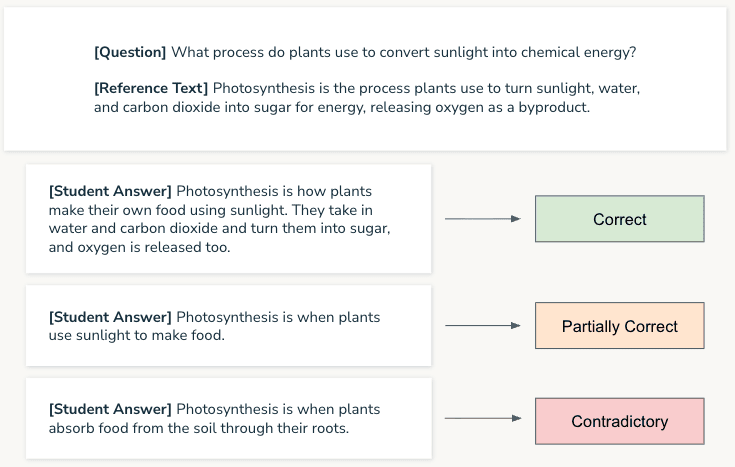
You may think that current state-of-the-art models could do this task with ease, but this is another demonstration of the jagged frontier. The latest models get just over half of the classifications correct (comparable to how custom-trained models performed on this task in 2013).
Benchmarks are the metrics that help us define the tasks we want models to be good at, and they shape the direction of research and development efforts. We've got lots of plans for additional benchmarks, different evaluation structures (llm-as-judge, verified evaluators, and ELO-style human judgment), and new ways of interacting with benchmarks. For example, on this benchmark, users will soon be able to submit their own approach, whether that is a fine-tuned model, a new prompt, or an agent harness, and see how it stacks up against the frontier labs.
Community for Education Experts and AI Developers¶
Most importantly, we can't make progress without a community that cares. We want to create a convergence point for two communities: on the one hand, engage the K-12 education community in AI development, and on the other, interest the AI development community in K-12 education. One way we will do that is through challenges incentivized with monetary prize pools. In addition to the platform itself, we're launching our first prize challenge today as well.

In the challenge, called Trace the Ace, participants are asked to build AI models that parse and understand tutoring transcripts, then use that knowledge to predict whether a student will get the next quiz question correct. The transcripts come from our challenge partner, the National Tutoring Observatory, and are real human tutor transcripts. A successful model will be able to trace student knowledge and, in the end, help us learn more about what works in tutoring and why.
There are $50,000 in prizes available, and winners will be evaluated not only quantitatively, who makes the most accurate predictions, but also on the quality of their insights into the task. Solution write-ups are required to win a prize, and additional prizes are awarded to the teams that bring their write-ups through to publication.
If you are looking for ways to engage beyond the challenge, all public goods have their own category in the platform discussion forum. You can come there to talk about what you find in a dataset, ask questions about methods for a benchmark, or share tips on how to move up the leaderboard in a competition. Or, if you are moved to, start a discussion on another K-12 AI Infrastructure topic!
Join us¶
Come and explore the resources. Use the datasets and share your results. Participate in the benchmarks and challenges. Ask the hard questions in the discussion forum. We can't wait to see what you build. We're just getting started and are looking forward to shaping this platform together.
—---
Thank you to Digital Promise, alongside core partners in the K-12 AI Infrastructure Program, Learning Data Insights, DrivenData, Massive Data Institute at Georgetown University, and Catalyst @ Penn GSE.
Thank you to the National Tutoring Observatory for their partnership in launching our first challenge on this new platform. And finally, thank you to all the researchers and organizations that have published open datasets that serve as the foundation of this work.


















