

Welcome to the reference implementation tutorial notebook for the On Top of Pasketti: Children’s Speech Recognition Challenge - Word Track! If you are just getting started, we recommend reading the competition webpage first.
The goal of this tutorial is to:
- Demonstrate how to load and explore the data.
- Provide a basic framework for building a model.
- Demonstrate how to package your work correctly for submission.
In this tutorial, we will adapt NVIDIA's Parakeet model, a pretrained ASR model, using NeMo. You can either expand on and improve the method in this notebook, or start with something completely different! Let's get started.
Background¶
Spoken language is a natural way for kids to learn, explore, and show what they know, yet today's Automatic Speech Recognition (ASR) technology hardly understands them. Most ASR systems are built on adult speech, and struggle with the pitch, rhythm, and evolving articulation of young learners.
The On Top of Pasketti: Children’s Speech Recognition Challenge assembles pre-existing and newly labeled datasets to advance speech models that truly work for children. Your goal in the Word Track is to develop models that accurately predict the words spoken by children in short audio clips.
This is a code execution challenge! Rather than submitting your predicted labels, you will package your trained model and the prediction code and submit that for containerized execution. See the code submission format webpage and the runtime repository for more information.
If you'd like to rerun this notebook, the notebook file can be downloaded from the reference implementation repository. That repository also includes all code imported into the notebook.
Step 0: Import packages¶
First, create your environment. We use uv as the package manager in this benchmark repository. To run this notebook, you must be on a Linux machine with GPU access.
- Create an environment:
just create-environment - Activate the environment:
source ./.venv/bin/activate - Install the requirements found in the TOML file into the environment:
just requirements
Remember, the runtime repository's TOML file lists the packages that will be available for running inference using model submissions.
We'll be using NVIDIA's NeMo framework to build our model along with standard data science Python libraries to explore and prepare the data. Because this is a code execution challenge, we'll also be testing our solutions locally before packaging our model and inference code for submission. To help us with scoring, we've imported some utility functions from the competition's runtime repository.
# Standard library
import json
import os
from pathlib import Path
# Visualization
import matplotlib.pyplot as plt
from matplotlib import ticker
# Core ML & audio stack
import librosa
import lightning.pytorch as pl
import numpy as np
import pandas as pd
import torch
# ASR models & normalization
from nemo.collections.asr.models import ASRModel
from transformers.models.whisper.english_normalizer import EnglishTextNormalizer
# Training & experiment utilities
from loguru import logger
from nemo.utils import logging
from nemo.utils.exp_manager import exp_manager
from nemo.utils.trainer_utils import resolve_trainer_cfg
from omegaconf import OmegaConf, open_dict
from sklearn.model_selection import train_test_split
# Project utilities
from asr_benchmark.config import DATA_ROOT, PROJECT_ROOT
from asr_benchmark.nemo_adapter import (
add_global_adapter_cfg,
patch_transcribe_lhotse,
update_model_cfg,
update_model_config_to_support_adapter,
)
from asr_benchmark.score import english_spelling_normalizer, score_wer
torch.set_float32_matmul_precision("high")
# Set SAMPLE to use a smaller subset of the data for faster iteration during development. Set it to None to use the full dataset.
SAMPLE = None
Step 1: Load and explore the data¶
First, you'll likely want to set up your own repository for developing a solution. We recommend using Cookiecutter Data Science, which ensures an easy-to-navigate project structure.
We'll download all of the competition data to our "raw" folder. There are two distinct training corpora that share the same structure but contain different data, and are hosted in separate locations for participant access. One corpus is hosted on the DrivenData platform, while a second corpus, which follows the same schema but contains different data, is provided by TalkBank. See the Data Download page for access instructions.
Our local data structure after downloading all files to a raw data folder is:
childrens-speech-recognition-benchmark-pub/data/raw
├── drivendata
│ ├── audio_part_0.zip
│ ├── audio_part_1.zip
│ ├── audio_part_2.zip
│ └── train_word_transcripts.jsonl
└── talkbank
├── audio.zip
└── train_word_transcripts.jsonl
After unzipping the files, you may want to consolidate the audio files into a single "audio" folder within the drivendata directory, where audio are split into multiple zip files.
rsync -a ./data/raw/drivendata/"audio 3"/ ./data/raw/drivendata/audio/
childrens-speech-recognition-benchmark-pub/data/raw
├── drivendata
│ ├── audio/
│ ├── audio_part_0.zip
│ ├── audio_part_1.zip
│ ├── audio_part_2.zip
│ └── train_word_transcripts.jsonl
└── talkbank
├── audio/
├── audio.zip
└── train_word_transcripts.jsonl
For each of the two corpora, the file train_word_transcripts.jsonl contains the following fields:
utterance_id(str) - unique identifier for each utterancechild_id(str) - unique, anonymized identifier for the speakersession_id(str) - unique identifier for the recording session; a single child_id may be associated with multiple session_idsaudio_path(str) - path to the corresponding .flac audio file relative to the /audio directory, following the pattern audio/{utterance_id}.flacaudio_duration_sec(float) - duration of the audio clip in secondsage_bucket(str) - age range of the child at the time of recording ("3-4", "5-7", "8-11", "12+", or "unknown")md5_hash(str) - MD5 checksum of the audio file, used for integrity verificationfilesize_bytes(int) - size of the audio file in bytesorthographic_text(str) - normalized orthographic transcription of the utterance
Each line in the JSONL manifest corresponds to a single utterance and references exactly one associated audio file. The orthographic_text field contains a manually created, minimally normalized orthographic transcription that serves as the training label.
Let's explore the metadata!¶
We will load the JSONL transcripts and explore some of the metadata. As a starting point, it is helpful to know how many utterances we have, how many unique children are present, the total audio time, the distribution of audio clip durations, and the distribution of child ages.
def read_transcripts(data_dir: Path) -> pd.DataFrame:
"""Read JSONL transcript file into a DataFrame and convert audio paths to absolute paths."""
transcript_path = data_dir / "train_word_transcripts.jsonl"
df = pd.read_json(transcript_path, lines=True)
logger.info(f"Loaded {len(df)} utterance transcripts")
df["audio_relpath"] = df["audio_path"]
df["audio_path"] = df["audio_relpath"].map(lambda p: str(data_dir / p))
return df
df_dd = read_transcripts(DATA_ROOT / "raw" / "drivendata")
df_tb = read_transcripts(DATA_ROOT / "raw" / "talkbank")
df = pd.concat([df_dd, df_tb], ignore_index=True)
df.drop(columns=["audio_path"]).head()
df.utterance_id.nunique()
df.child_id.nunique()
round(df.audio_duration_sec.sum() / (60**2))
There are over 350,000 utterances in the training dataset, across 3,344 children, totaling 344 hours of audio data. Next, let's take a look at the distribution of audio clip durations.
bins = list(range(0, 21)) + [np.inf]
labels = [str(i) for i in range(0, 20)] + ["20+"]
binned = pd.cut(df.audio_duration_sec, bins=bins, labels=labels, right=False)
counts = binned.value_counts().sort_index()
counts.plot(kind="bar")
plt.xlabel("Audio Duration (sec)")
plt.ylabel("Number of Audio Clips")
plt.title("Distribution of Audio Durations")
plt.xticks(rotation=90)
plt.show()

Even though the audio has been clipped to the utterance level, we have some outliers over 20 seconds.
# What is the longest clip (in minutes)?
round(df.audio_duration_sec.max() / 60)
Most audio clips are very short (1-3 seconds). There is a tail of longer clips, up to an outlier 22 minute clip. Next, let's look at the distribution of utterances by child age.
df["age_bucket"] = pd.Categorical(
df["age_bucket"], categories=["unknown", "3-4", "5-7", "8-11", "12+"], ordered=True
)
fig, ax = plt.subplots()
df["age_bucket"].value_counts(normalize=True, sort=False).plot.barh(ax=ax)
ax.set_title("Utterances by Age Group")
ax.set_xlabel("Percent of Utterances")
ax.set_ylabel("Age Group")
ax.xaxis.set_major_formatter(ticker.PercentFormatter(1.0))
ax.bar_label(ax.containers[0], fmt=lambda x: f"{x * 100:.0f}%")
plt.show()

About half of the utterances come from 8 to 11 year olds, with 13% coming from 3 to 4 year olds and 28% coming from 5 to 7 year olds.
Let’s explore the utterances!¶
We will listen to an example utterance and visualize the features.
def plot_waveform(audio_data: np.ndarray, sr: int) -> None:
"""Plot the waveform of an audio signal"""
plt.figure(figsize=(10, 4))
librosa.display.waveshow(audio_data, sr=sr)
plt.title("Waveform")
plt.xlabel("Time (s)")
plt.ylabel("Amplitude")
plt.show()
def plot_melspectrogram(audio_data: np.ndarray, sr: int) -> None:
"""Generate and plot the mel spectrogram of an audio signal"""
S = librosa.feature.melspectrogram(y=audio_data, sr=sr)
S_db = librosa.power_to_db(S, ref=np.max)
plt.figure(figsize=(10, 4))
librosa.display.specshow(S_db, sr=sr, x_axis="time", y_axis="mel")
plt.colorbar(format="%+2.0f dB")
plt.title("Mel Spectrogram")
plt.xlabel("Time (s)")
plt.ylabel("Mel Frequency")
plt.show()
example_utt = "U_1c8757065e355c35"
df[df.utterance_id == example_utt][
["utterance_id", "audio_duration_sec", "orthographic_text"]
]
This clip may sound understandable to us, but children’s speech often includes subtle pronunciation differences. For example, models must learn to handle syllable deletions (“elephant” → “efant”), consonant nasalization (“mom” → “bob”), and common speech sound disorders like tetism.
Now that we've heard the utterance, let's look at it from the model's perspective. We'll plot the raw waveform - the audio signal represented as amplitude over time:
audio_data, sr = librosa.load(df[df.utterance_id == example_utt]["audio_path"].values[0])
plot_waveform(audio_data, sr)

Before training a machine learning model, the raw audio array with sampled amplitudes must be transformed. Transforming this raw signal into mel spectrograms enables the machine learning model to learn speech-relevant acoustic patterns more efficiently. The transformation reorganizes the signal into a structured time-by-frequency map that highlights speech patterns like vowels and consonants.
plot_melspectrogram(audio_data, sr)

When training machine learning models, this transformation is often handled under-the-hood by processors or feature extractors. For example, in our benchmark model implementation, we will fine tune NVIDIA’s pretrained parakeet-tdt-0.6b-v2 model using NeMo. NeMo's architecture includes a built-in preprocessing pipeline that converts raw audio waveforms into mel-spectrogram features, eliminating the need for manual feature extraction.
For more tips on generating predictive features from audio data, check out DrivenData's overview of open-source packages for using speech data in ML. That blog post also includes some helpful intro to working with audio data.
Step 2: Build the model¶
A straightforward modeling option is to start from a strong pretrained ASR model (trained mostly on adult speech), then fine-tune on our labeled child-speech training set. Fine-tuning the ASR model will help it understand the unique acoustic and linguistic patterns of children. Before choosing a pre-trained model, make sure it adheres to the competition rules.
In this tutorial, we adapt NVIDIA’s pretrained Parakeet TDT parakeet-tdt-0.6b-v2 model using NeMo. We chose this model because it is open source, ranks highly on the Hugging Face Open ASR leaderboard (at time of writing), and strikes a good balance between performance and model size. Rather than fine-tuning all parameters, we will freeze the base model and train only lightweight adapter weights. Adapters are small, trainable modules inserted into the frozen model’s layers that allow it to adapt to new data without modifying the original pretrained weights. Freezing the base model makes the fine-tuning process more efficient and helps avoid overfitting. NeMo makes this process easier by providing native adapter support, handling data pipelines (manifests, batching, feature extraction), and integrating experiment management (checkpointing, logging).
Key packages include:
nemo_toolkitfor ASR model + data processinglightning.pytorchfor the training backendomegaconffor config file management
1. Prepare Dataset & Create Splits¶
We need to provide NeMo with a "manifest" JSONL file that lists all of our samples and sample information. NeMo requires this manifest to be in a particular format, with specific column names and definitions. Each manifest line must be a JSON object with audio_filepath (path to audio file), duration (audio duration in seconds), and text (transcription text).
Below we will transform the competition data to NeMo's required manifest format.
We'll also filter out clips longer than 25 seconds, which strain computer memory. Competitors may want to further split these clips to avoid losing training data. Then we'll split the data 80/20 into train/validation.
MANIFEST_DIR = DATA_ROOT / "processed" / "ortho_dataset"
train_manifest_path = MANIFEST_DIR / "train_manifest.jsonl"
val_manifest_path = MANIFEST_DIR / "val_manifest.jsonl"
clip_max_duration_sec = 25.0
MANIFEST_DIR.mkdir(parents=True, exist_ok=True)
Remember, df has one row per utterance, and includes data hosted on both TalkBank and DrivenData.
df = df[["audio_path", "audio_duration_sec", "orthographic_text"]].rename(
columns={
"audio_path": "audio_filepath",
"audio_duration_sec": "duration",
"orthographic_text": "text",
}
)
# Removing long clips to improve memory efficiency during training
over_max_duration_mask = df["duration"] > clip_max_duration_sec
logger.info(
f"Removing {over_max_duration_mask.sum()} samples with audio duration "
f"> {clip_max_duration_sec} seconds"
)
df = df[~over_max_duration_mask]
if SAMPLE:
logger.info(f"Sampling {SAMPLE} utterances")
df = df.sample(SAMPLE, random_state=10)
train_df, val_df = train_test_split(df, test_size=0.2, random_state=10)
train_df.to_json(train_manifest_path, orient="records", lines=True)
val_df.to_json(val_manifest_path, orient="records", lines=True)
2. Configuration¶
Let's define parameters for the adaptation.
- To start, we copied an example .yaml file for ASR adaptation using NeMo from the NeMo repository to
asr_benchmark/assets/asr_adaptation.yaml. This file gives us a reasonable default starting-point configuration. - We want to overtly set some parameters, like:
pretrained_model(to specifyparakeet-tdt-0.6b-v2)manifest_filepath(to point to our manifest locations)channel_selector(to ensure audio is converted to the expected mono format if it is stereo in raw form)max_steps(to control how many training steps we complete before we stop training)
- For these parameters, we override the default settings in the .yaml using
OmegaConf.merge. - While we do not implement hyperparameter tuning here, it is recommended for competitors.
# ── Hardware-dependent settings ──────────────────────────────────────────────
# Adjust these to match your GPU memory and CPU cores.
DEVICES = 1
PRECISION = "bf16-mixed"
BATCH_SIZE = 32
NUM_WORKERS = 8
# ── Load NeMo adapter defaults ───────────────────────────────────────────────
yaml_path = PROJECT_ROOT / "asr_benchmark" / "assets" / "asr_adaptation.yaml"
cfg = OmegaConf.load(yaml_path)
# ── Training overrides ───────────────────────────────────────────────────────
overrides = OmegaConf.create(
{
"model": {
"pretrained_model": "nvidia/parakeet-tdt-0.6b-v2",
"adapter": {
"adapter_name": "asr_children_orthographic",
"adapter_module_name": "encoder",
"linear": {"in_features": 1024},
},
"train_ds": {
"manifest_filepath": str(train_manifest_path),
"batch_size": BATCH_SIZE,
"num_workers": NUM_WORKERS,
"use_lhotse": False,
"channel_selector": "average",
},
"validation_ds": {
"manifest_filepath": str(val_manifest_path),
"batch_size": BATCH_SIZE,
"num_workers": NUM_WORKERS,
"use_lhotse": False,
"channel_selector": "average",
},
"optim": {
"lr": 0.001,
"weight_decay": 0.0,
},
},
"trainer": {
"devices": DEVICES,
"precision": PRECISION,
"strategy": "auto",
"max_epochs": 1 if SAMPLE else None,
"max_steps": -1 if SAMPLE else 5000,
"val_check_interval": 1.0 if SAMPLE else 500,
"enable_progress_bar": False,
},
"exp_manager": {
"exp_dir": str(PROJECT_ROOT / "models" / "orthographic_benchmark_nemo"),
},
}
)
cfg = OmegaConf.merge(cfg, overrides)
3. Define Trainer¶
The Trainer orchestrates the training loop across devices, delegating tensor operations to PyTorch's backend. We initiate the trainer with the OmegaConf config object we made above, and then set up an experiment manager to handle logging, checkpoint saving, and saving artifacts to disk.
Note we use the cell magic %%capture below to hide long cell outputs for readability.
%%capture
trainer = pl.Trainer(**resolve_trainer_cfg(cfg.trainer))
exp_log_dir = exp_manager(trainer, cfg.get("exp_manager", None))
4. Data and Model Setup¶
We load the pretrained model by fetching the model from our config first and then patching it for adapter support. Then, we load the model weights.
%%capture
model_cfg = ASRModel.from_pretrained(cfg.model.pretrained_model, return_config=True)
update_model_config_to_support_adapter(model_cfg, cfg)
model = ASRModel.from_pretrained(
cfg.model.pretrained_model,
override_config_path=model_cfg,
trainer=trainer,
)
We disable the CUDA graph decoder because it is incompatible with current PyTorch (2.10).
%%capture
with open_dict(model.cfg):
model.cfg.decoding.greedy.use_cuda_graph_decoder = False
model.change_decoding_strategy(model.cfg.decoding)
Next, we prepare our data by merging our parameter overrides (batch size, num workers, etc.) into the model's built-in data config. Note that while keys not present in the original config are dropped, whitelisted keys are always injected.
cfg.model.train_ds = update_model_cfg(model.cfg.train_ds, cfg.model.train_ds)
model.setup_training_data(cfg.model.train_ds)
cfg.model.validation_ds = update_model_cfg(
model.cfg.validation_ds, cfg.model.validation_ds
)
model.setup_multiple_validation_data(cfg.model.validation_ds)
We also need to set the optimization function, which controls how the model’s weights are updated using gradients to minimize the loss and improve performance during training. We use AdamW with cosine annealing schedule and 10% warmup ratio as a starting point.
%%capture
model.setup_optimization(cfg.model.optim)
# Configure spec augmentation from config if available, otherwise disable it.
if "spec_augment" in cfg.model:
model.spec_augmentation = model.from_config_dict(cfg.model.spec_augment)
else:
model.spec_augmentation = None
del model.cfg.spec_augment
5. Set up Adapter¶
An adapter is a small neural network module that learns to transform the pretrained model's internal representations specifically for child speech. Rather than retraining the entire model, we insert lightweight adapters into each layer of the encoder, the part of the model that processes audio features.
We add a linear adapter to every encoder layer, then freeze the base model and unfreeze only the adapter weights. This keeps training efficient—only ~0.1% of parameters are trainable, while (hopefully) allowing the adapter to learn the acoustic and linguistic patterns unique to children's voices.
%%capture
with open_dict(cfg.model.adapter):
adapter_name = cfg.model.adapter.pop("adapter_name")
adapter_type = cfg.model.adapter.pop("adapter_type")
adapter_module_name = cfg.model.adapter.pop("adapter_module_name", None)
adapter_state_dict_name = cfg.model.adapter.pop("adapter_state_dict_name", None)
adapter_type_cfg = cfg.model.adapter[adapter_type]
if adapter_module_name is not None and ":" not in adapter_name:
adapter_name = f"{adapter_module_name}:{adapter_name}"
adapter_global_cfg = cfg.model.adapter.pop(model.adapter_global_cfg_key, None)
if adapter_global_cfg is not None:
add_global_adapter_cfg(model, adapter_global_cfg)
model.add_adapter(adapter_name, cfg=adapter_type_cfg)
assert model.is_adapter_available()
model.set_enabled_adapters(enabled=False)
model.set_enabled_adapters(adapter_name, enabled=True)
model.freeze()
model = model.train()
model.unfreeze_enabled_adapters()
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total parameters: {total_params:,}")
print(
f"Trainable parameters: {trainable_params:,} ({100 * trainable_params / total_params:.2f}%)"
)
6. Train¶
Let's adapt the pretrained model to children's voices!
%%capture
trainer.fit(model)
We've hidden the training cell outputs to avoid printing many lines of logs. Below are a few key snippets of the log output that we saw when training:
| Name | Type | Params | Mode
--------------------------------------------------------------------------------
0 | preprocessor | AudioToMelSpectrogramPreprocessor | 0 | train
1 | encoder | ConformerEncoderAdapter | 610 M | train
2 | decoder | RNNTDecoder | 7.2 M | train
3 | joint | RNNTJoint | 1.7 M | train
4 | loss | RNNTLoss | 0 | train
5 | spec_augmentation | SpectrogramAugmentation | 0 | train
6 | wer | WER | 0 | train
--------------------------------------------------------------------------------
1.6 M Trainable params
617 M Non-trainable params
619 M Total params
2,477.792 Total estimated model params size (MB)
Epoch 0, global step 500: 'val_wer' reached 0.20008 (best 0.20008), saving model to '/models/orthographic_benchmark_nemo/ASR-Adapter/2026-02-26_04-58-33/checkpoints/ASR-Adapter--val_wer=0.2001-epoch=0.ckpt' as top 5
...
Epoch 0, global step 5000: 'val_wer' reached 0.16359 (best 0.16359), saving model to '/models/orthographic_benchmark_nemo/ASR-Adapter/2026-02-26_04-58-33/checkpoints/ASR-Adapter--val_wer=0.1636-epoch=0.ckpt' as top 5
`Trainer.fit` stopped: `max_steps=5000` reached.
Because we configured max_steps to be 5,000, we stopped training before we completed the first epoch.
We need to save the final results. We save the adapter weights to a standalone file alongside the NeMo checkpoints.
if adapter_state_dict_name is not None:
state_path = exp_log_dir if exp_log_dir is not None else os.getcwd()
ckpt_path = os.path.join(state_path, "checkpoints")
if os.path.exists(ckpt_path):
state_path = ckpt_path
state_path = os.path.join(state_path, adapter_state_dict_name)
model.save_adapters(str(state_path))
7. Evaluation¶
Now it's time to assess how well our adapted model performs. We load the best trained checkpoint from disk and run inference across the entire validation set. The model transcribes each audio clip, and we compare these predictions against the reference transcriptions using Word Error Rate (WER). The WER calculation is copied exactly from the runtime repository.
%%capture
# Load our model checkpoint
nemo_ckpts = sorted((exp_log_dir / "checkpoints").glob("*.nemo"))
if not nemo_ckpts:
raise FileNotFoundError(f"No .nemo checkpoints found in {exp_log_dir}/checkpoints/")
best_ckpt = nemo_ckpts[-1]
print(f"Loading checkpoint: {best_ckpt}")
eval_model = ASRModel.restore_from(best_ckpt, map_location="cuda")
with open_dict(eval_model.cfg):
eval_model.cfg.decoding.greedy.use_cuda_graph_decoder = False
eval_model.change_decoding_strategy(eval_model.cfg.decoding)
patch_transcribe_lhotse(eval_model)
# Run inference
val_manifest_path = cfg.model.validation_ds.manifest_filepath
with open(val_manifest_path) as f:
val_entries = [json.loads(line) for line in f]
audio_files = [e["audio_filepath"] for e in val_entries]
references = [e["text"] for e in val_entries]
print(f"Running inference on {len(audio_files)} validation utterances...")
raw = eval_model.transcribe(
audio_files, batch_size=BATCH_SIZE, channel_selector="average", verbose=False
)
if isinstance(raw, tuple):
raw = raw[0]
predictions = [h.text if hasattr(h, "text") else h for h in raw]
Before scoring, let's remove any example where the normalized label is an empty string.
normalizer = EnglishTextNormalizer(english_spelling_normalizer)
filtered = [(r, p) for r, p in zip(references, predictions) if normalizer(r) != ""]
references, predictions = zip(*filtered)
wer = score_wer(references, predictions)
print(f"Validation WER: {wer:.4f}")
print("\nSample predictions:")
for ref, pred in zip(references[:5], predictions[:5]):
print(f" REF: {ref}")
print(f" PRED: {pred}")
print()
Our Validation WER after adapting the model is 0.15!
Step 3: Make your submission¶
Since this is a code execution competition, we will submit our model weights and code rather than predictions. See the code submission format webpage for more information.
The general steps to follow:
- Develop inference code
- Test your submission locally
- Package submission
- Make a smoke test submission
- Once you have successfully debugged your submission, submit it for scoring on the full test set!
Develop Inference Code¶
We need to set up a repository with a main.py Python script which performs inference in the competition execution environment and writes our predictions to the required output file. During code execution, our submission will be unzipped and run in the cloud compute cluster. The container will run your main.py script.
Our code must write a JSON Lines (JSONL) file containing one prediction per utterance.
Each line must include:
utterance_idorthographic_text: UTF-8, standard English transcription of the utterance The submission should be written to ./submission/submission.jsonl relative to the working directory.
See more details in the code submission format webpage and in the example submission.
In our main.py, we load the trained adapter checkpoint from disk, restore the NeMo model, and run inference on all test utterances in batches. The script reads audio file paths from the test manifest, transcribes them using the adapted model, and writes the predicted transcriptions to the submission file in the required format. We sort utterances by duration before inference (longest first) to improve GPU memory efficiency during batching.
See orthographic_submission/main.py in the benchmark repository for the details.
Test Submission Locally¶
You should first and foremost test your submission locally. This is a great way to work out any bugs and ensure that your model performs inference successfully. See the runtime repository's README for further instructions.
The benchmark repository provides a useful justfile command to run the trained model on a few sample files.
# Run inference using data-demo/word/ to test orthographic submission
test-orthographic:
uv run orthographic_submission/main.py models/orthographic_benchmark_nemo/ASR-Adapter-best.nemo data-demo/word/utterance_metadata.jsonl
Package Submission¶
Now we will package up our model and inference code into a zip file for predicting on the test set in the runtime container. The benchmark repository provides a justfile command to do this. The justfile finds the latest models weights, and then creates a zipfile combining those model weights with /orthographic_submissions/main.py.
pack-orthographic:
#!/usr/bin/env bash
set -euo pipefail
latest=$(ls -td models/orthographic_benchmark_nemo/ASR-Adapter/*/checkpoints/ASR-Adapter.nemo | head -1)
ln -sf "${latest#models/orthographic_benchmark_nemo/}" models/orthographic_benchmark_nemo/ASR-Adapter-best.nemo
echo "Updated ASR-Adapter-best.nemo -> $latest"
rm -f orthographic_submission.zip
(cd orthographic_submission && zip -r ../orthographic_submission.zip main.py)
(cd models/orthographic_benchmark_nemo && zip -r ../../orthographic_submission.zip ASR-Adapter-best.nemo)
Another packing command is available on the runtime repo's orthographic example.
Make a Smoke Test Submission¶
We provide a "smoke test" environment that replicates the test inference runtime but runs only on a small set of audio files. In the smoke test runtime, data/ contains 9,000 audio files from the training set.
Let's submit our submission.zip to a smoke test on the platform.
After hitting "Submit" you can see the job in the queue—it will progress from "Uploading" to "Pending" to "Starting" to "Running":
Once your submission reaches "Completed", head on over to the "Submissions" tab to see your smoke test score.
Submit!¶
After you've made sure a smoke test submission runs without error, you're ready to submit the real deal! This adaptation of parakeet-tdt-0.6b-v2 results in a .2370 WER on the full test set.
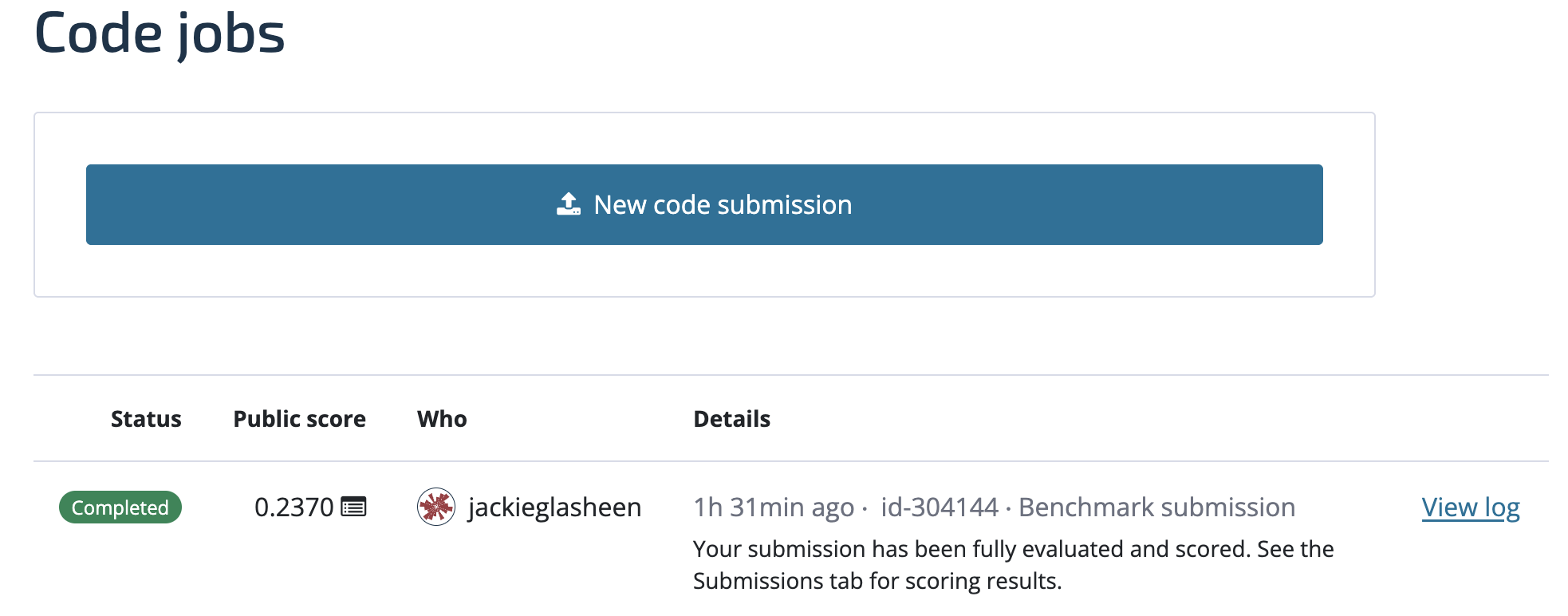
We encourage you to also be mindful of the submission limit (3 per 7 days at most) and others' code jobs. Canceled jobs do not count against the submission limit.
This is of course just one of the approaches you could take for this challenge. Some resources that may be helpful in getting started are:
- The Hugging Face Automatic Speech Recognition unit of their Audio Course.
- The Hugging Face Open ASR Leaderboard.
- A Parakeet fine-tuning implementation from Deep-unlearning.
- NeMo example ASR adaptation (which has a similar implementation as this blog post).
If you want to share any of your findings or have questions, feel free to post on the community forum.
Good luck!



















