


The Challenge¶
Current automated speech recognition (ASR) models transcribe adult speech well but struggle with children's speech. Kids have distinct vocal characteristics, different speech patterns, and make frequent speech shortcuts and pronunciation errors, all of which make understanding them difficult. As demonstrated below, child speech error rates of leading ASR models are in the 40% - 80% range (compared to <10% error rate for state of the art adult speech ASR).
Automatically transcribing children's speech is particularly difficult in critical application contexts including noisy classrooms, students who speak non-"Standard" American English, have speech pathologies, or are early speakers in pre-school, pre-K, or early elementary grades. Given the current state of ASR and these critical gaps, educators lack reliable speech recognition tools and ASR-enabled tools precisely where they could make the biggest impact.
The On Top of Pasketti: Children's Speech Recognition Challenge aimed to advance accurate, open ASR for children's voices tailored to the highest-impact use cases in early education. The challenge is the second phase of a three-phase project. In the first phase, work focused on benchmarking, competition design, data landscaping, and data sourcing and annotation, all informed by expert guidance. 560k child utterances representing 515+ hours of read, prompted, and spontaneous speech were assembled for the competition from multiple contributing data partners and manually annotated with word and phonetic transcripts.
In the final phase, prize-winning solutions will be retrained on broader data, including sensitive data representing realistic education populations, and released as rigorously evaluated open-weight models in Fall 2026. Evaluation of the final models will include error analyses and out-of-sample tests. Error rates reported below reflect interim performance results based on the competition test set and as-is competition winning models.
Join the competition mailing list here to stay informed about project. We'll share updates when competition annotations are published and when final models are openly released.
The Results¶
The On Top of Pasketti Challenge established a new frontier in children's speech recognition. Over 828 participants generated 1,542 Word Track submissions and 648 Phonetic Track submissions.
In the Word Track, solvers developed models to transcribe the words a child intends to say, ignoring errors and disfluencies (e.g., uh... eye doh-noh would be transcribed as "I don't know"), evaluated with Word Error Rate (WER). Winners improved more than 50% over both Whisper and KidWhisper, strong public models, the latter trained specifically on children's speech.
In the Phonetic Track, solvers developed models that transcribe the actual sounds a child produces using the International Phonetic Alphabet (IPA; e.g., uh... eye doh-noh as "ʔəː ʔɑi doʊ noʊ"), evaluated with IPA Character Error Rate (CER). Winners improved 49% over Parakeet as implemented in the phonetic ASR reference solution. This is the first widely available model of its kind specifically for kids, and we hope it will be a baseline tool for assessments and pathology diagnoses.
Word Track
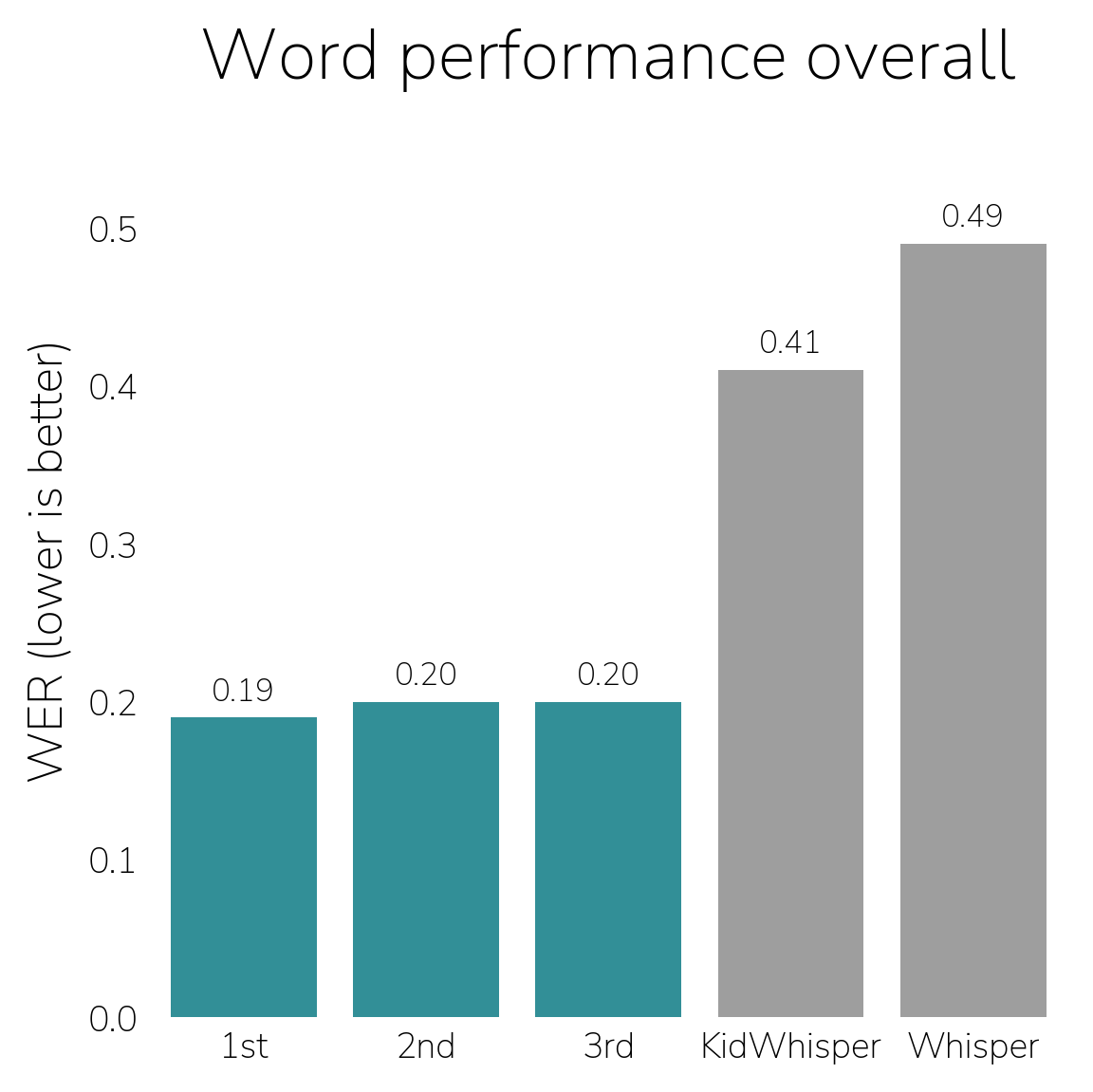
Phonetic Track
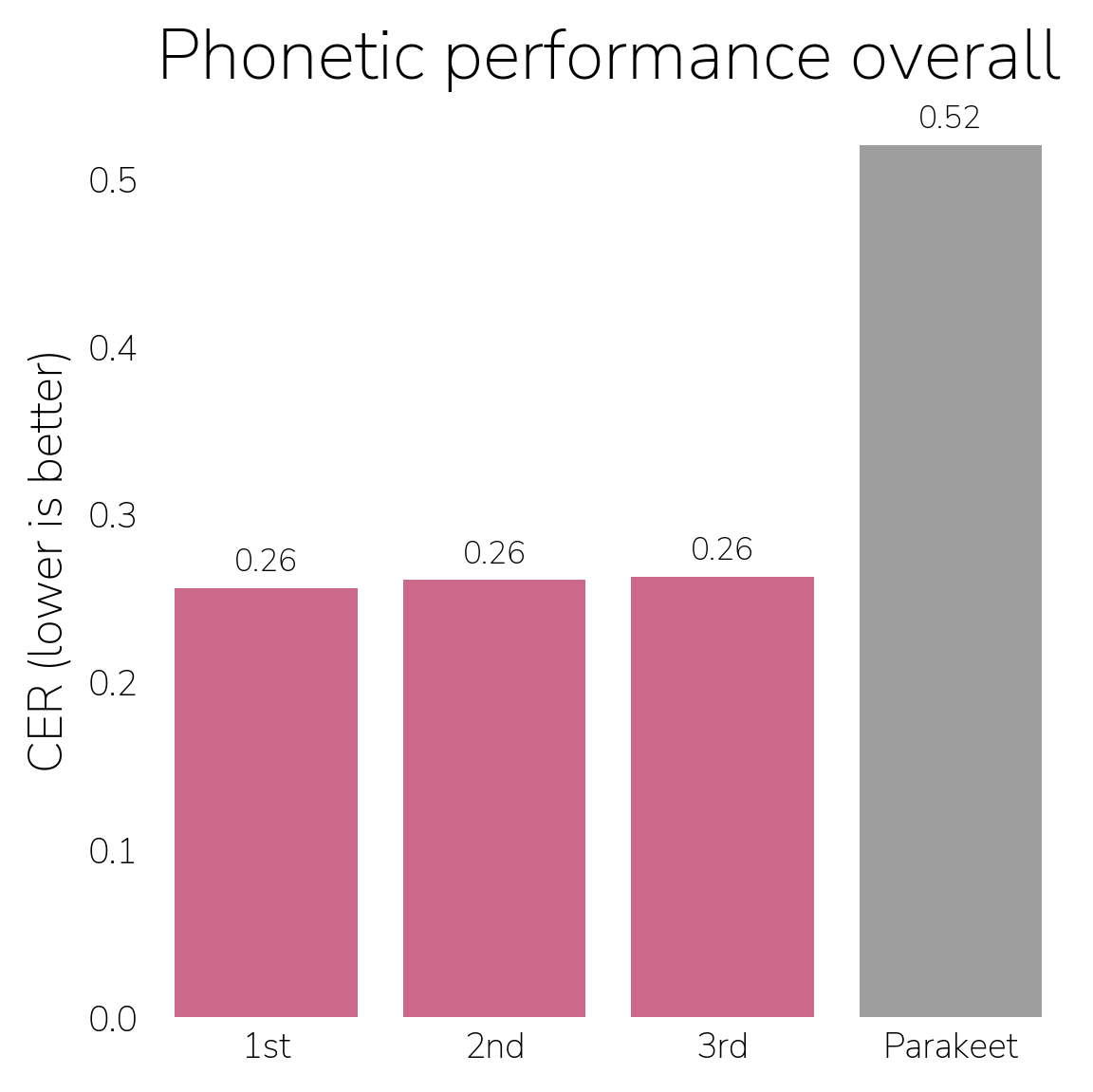
To give a sense of what this looks like in practice, here are examples at the extremes of the competition test set.
Word Track
Phonetic Track
Examples from the competition test set.
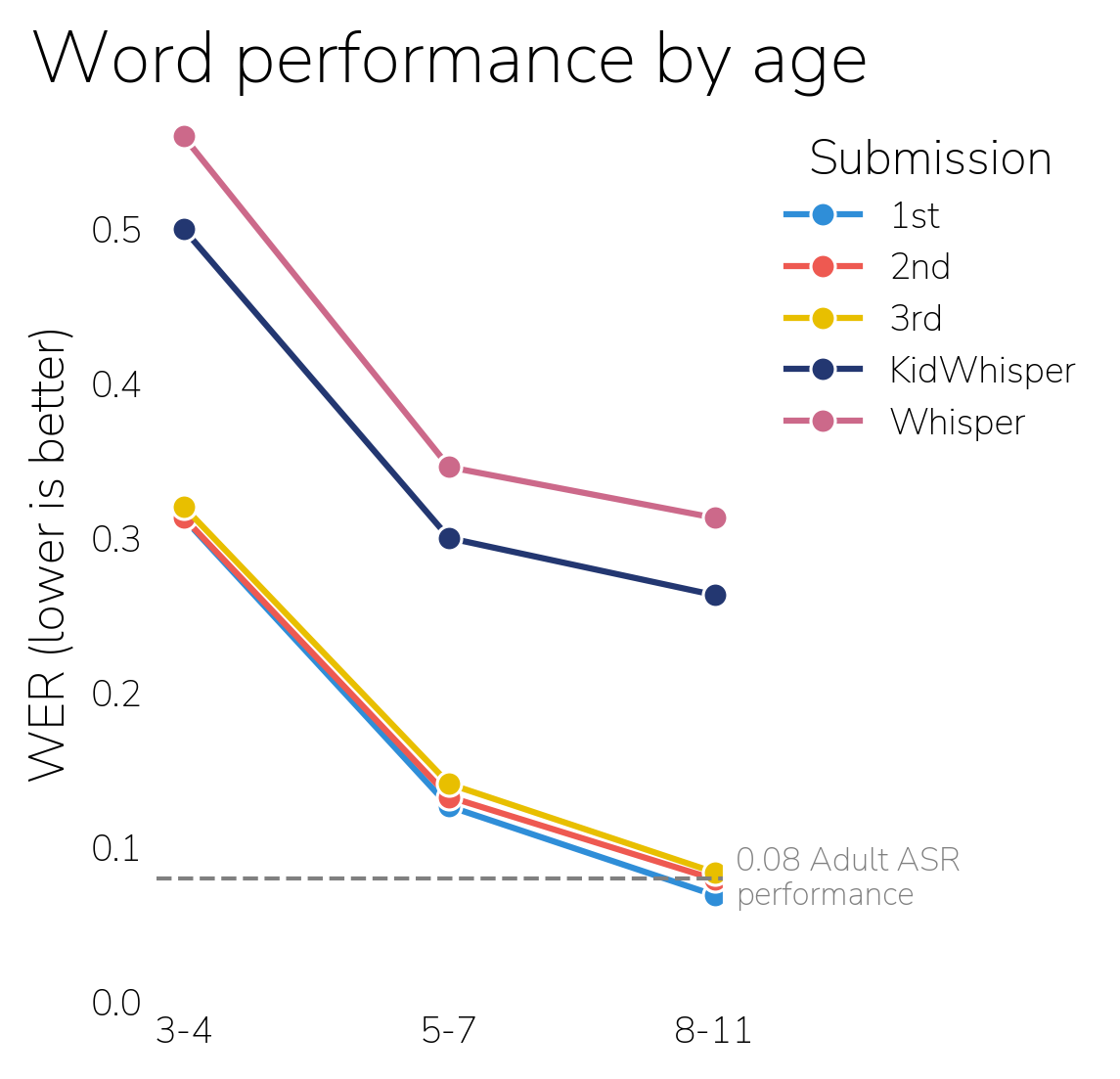
In both tracks, significant performance improvements were made across all populations and settings, demonstrating the importance of diverse training data. The models reached adult ASR performance (0.08 WER) in older learners, but still struggle with many speaker populations that unlock high-impact educational applications of ASR, like with 3-4 year old learners. In classroom settings, which are especially difficult for models (and humans) because of background talk and noise, the noisy bonus winner achieved a 44% improvement over KidWhisper.
Word Track
Noisy Bonus
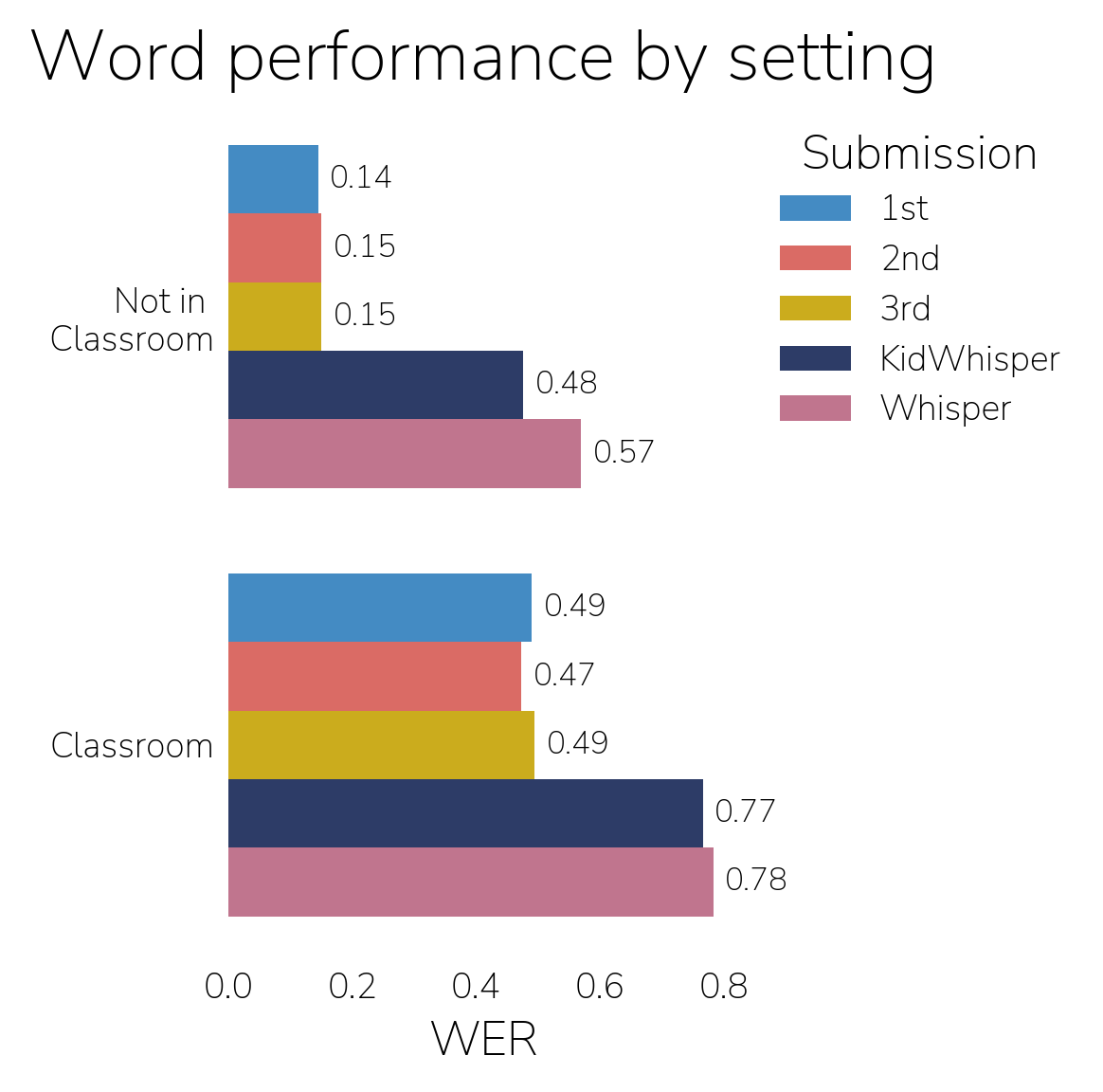
Despite persistent performance challenges, and error rates >10%, these models can be useful, even transformative, in educational settings. The kinds of errors these models make may not matter in many application contexts, or may not be critical for the downstream use (e.g., the phonetic model may be great at detecting the specific developmentally atypical mispronunciations that a screening tool would focus on). Further, even a 20% or 30% error rate in a transcript may be worth producing and using as an improvement over no transcript at all, or as a way to speed up manual transcription. A parallel scenario for adult ASR is an imperfect meeting transcript - an independent benchmark of commercial ASR products found WER ranging from 11% to over 60% on challenging conversational audio, with several major providers above 30%.
As is, these models are usable, but should be tested and evaluated in the specific context and population they would be used in, given that performance will vary by age, dialect, setting, and task. Models will be especially useful in context like literacy assessments, where a known target transcript is available to compare against and the task is fairly constrained. They can also serve as strong starting points for fine-tuning to specific tasks, grade levels, or student populations.
Key takeaways from winning approaches¶
Competitions reveal not just what performance is achievable, but which approaches get you there. Here are insights from the winning architectures and solution write-ups.
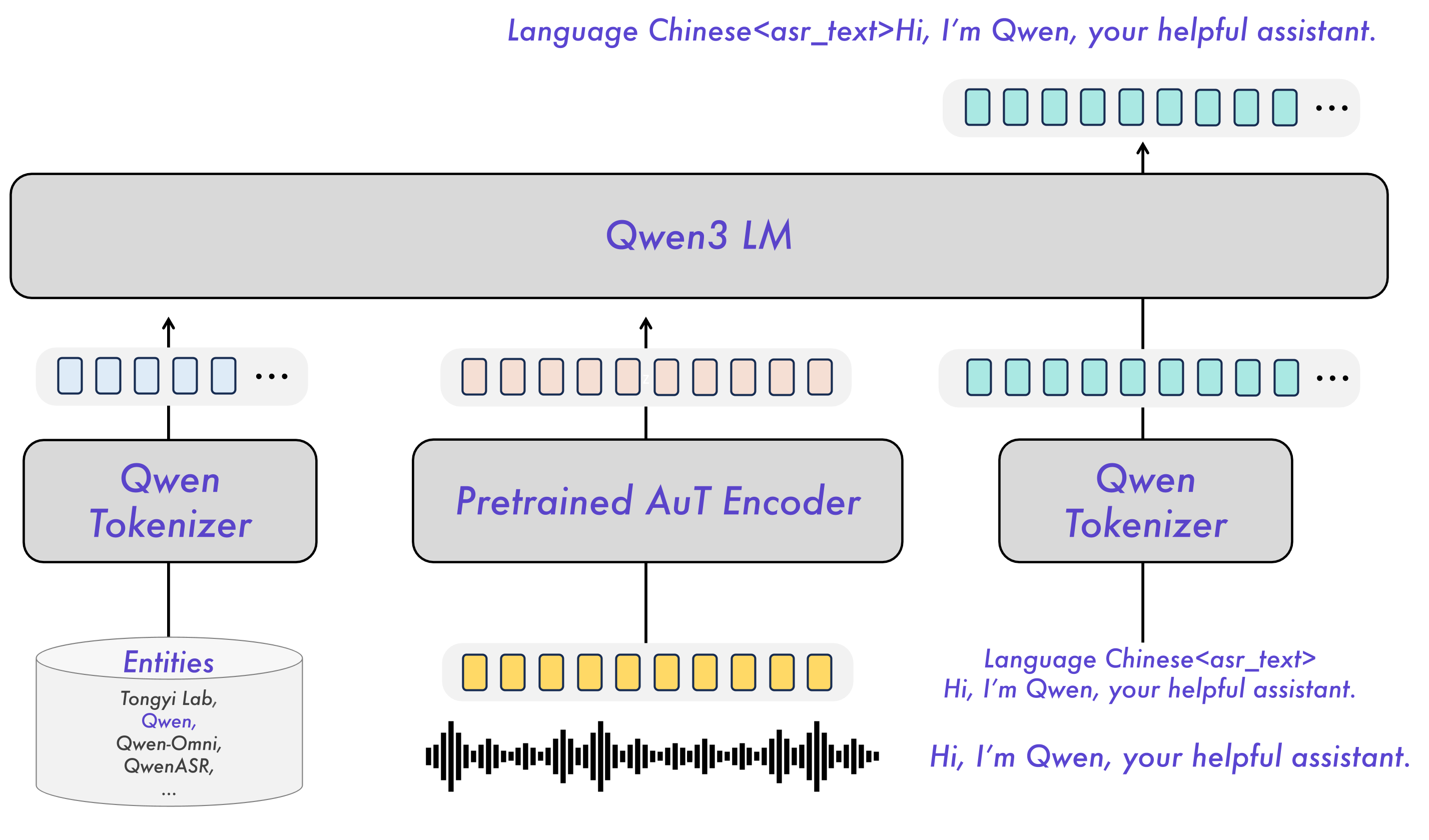 Qwen3-ASR (Word Track winners)
Qwen3-ASR (Word Track winners)
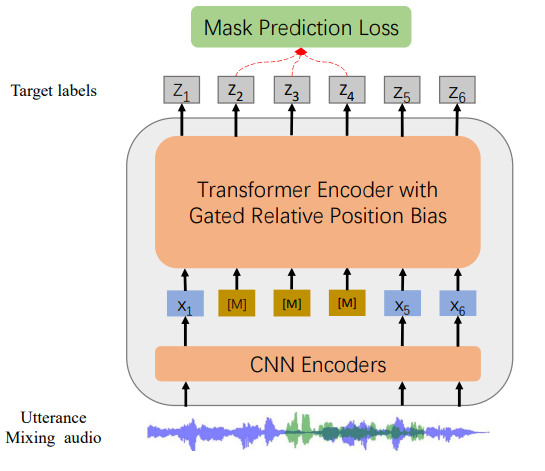 WavLM (Phonetic Track winners)
WavLM (Phonetic Track winners)
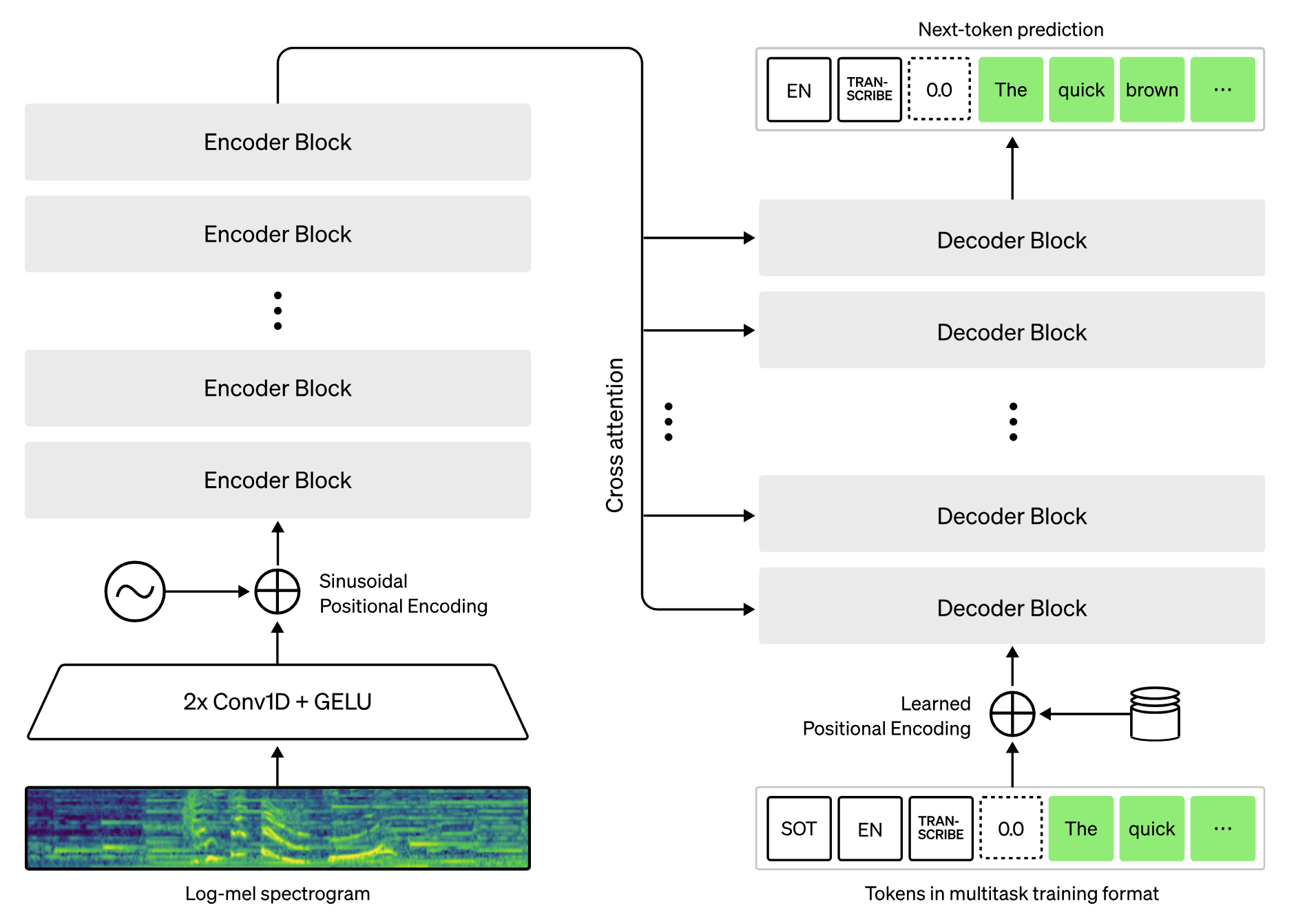 Whisper (Phonetic Track ensemble)
Whisper (Phonetic Track ensemble)
- Word track: All winners finetuned Qwen3-ASR-1.7B, which pairs an audio encoder with an LLM decoder. For word-level transcription, language context appears to matter as much as acoustic recognition.
- Phonetic track: Winners used ensembles built around Microsoft’s WavLM, a transformer trained on noisy audio with strong sound embeddings. They combined WavLM in different configurations with HuBERT, W2v-BERT, Parakeet, and Whisper. LLM-based models offered no clear advantage here; capturing how sounds are produced mattered more than language context.
- Training costs were modest. The best solutions trained for 1–2 days on 1–4 GPUs at an estimated $50–$250 in cloud compute, using full fine-tuning or LoRA.
- Data augmentation drove the final edge, including pitch shifting, white noise injection, and time stretching. Winners on the noisy bonus prize randomly injected the provided synthetic classroom background noise during training.
- More child speech data would likely improve performance, but it's hard to come by. The competition dataset (~515 hours) is large by child-speech standards but small by modern machine learning standards. Solvers were permitted to train on external data, but winners relied almost entirely on competition-provided recordings and annotations, reflecting a lack of available, high-quality labeled child speech. Data collection or annotation of existing data focused where models most struggle (younger children, certain dialects, noisy settings) is likely the most direct path to further improvement.
Winning Solutions Code and Reports¶
All winning solution code and reports can be found in our winners repository on GitHub. All solutions are licensed under open-source licenses.
Winner Overview¶
Word Track winners¶
| Place | Winner | Prize | WER |
|---|---|---|---|
| 1st Place | Kotaro Watanabe | $25,000 | 0.193693 |
| 2nd Place | Sunday | $15,000 | 0.195281 |
| 3rd Place | Tang Yongqwei | $10,000 | 0.198434 |
Noisy Classroom Bonus winners: Kotaro Watanabe, Sunday, Shiqi Li, Mitchell DeHaven
Phonetic Track winners¶
| Place | Winner | Prize | CER |
|---|---|---|---|
| 1st Place | Cheng Huige | $25,000 | 0.2559 |
| 2nd Place | Rein Viegers, Maxim Cardenas Cruz, and Willem Dieleman | $15,000 | 0.260728 |
| 3rd Place | Tuan Dung Le | $10,000 | 0.2629 |
Meet the winners of the Word Track¶
Kotaro Watanabe¶

Username: ktrw
Hometown: Tokyo, Japan
Place: 1st place Word Track + Noisy Bonus Prize
Prize: $25,000 + $5,000
Background: Kotaro is an application engineer at a meeting transcription SaaS company. He became interested in this challenge as an opportunity for skill development.
Summary of approach: The data consisted of two components — noise and useful signal — but it was difficult to draw a clear boundary between them. I prepared multiple datasets by varying the data filtering threshold, using WER from a fine-tuned Parakeet model as the filtering criterion. I then performed checkpoint ensembling of Qwen-3-ASR-1.7b fine-tuned with LoRA on each of those datasets.
| Experiment | Model | Method | Smoke WER | Public WER | Noisy WER |
|---|---|---|---|---|---|
| no finetuning | parakeet-tdt-0.6b-v3 | - | - | 0.3202 | 0.5680 |
| parakeet_exp007 | parakeet-tdt-0.6b-v2 | full finetuning (epoch1) | 0.2175 | 0.2404 | 0.5956 |
| parakeet_exp008 | parakeet-tdt-0.6b-v2 | adapter (epoch1) | 0.2013 | 0.2350 | 0.6122 |
| parakeet_exp012 | parakeet-tdt-0.6b-v3 | adapter (epoch3) | 0.1955 | 0.2347 | 0.5609 |
| parakeet_exp013 | parakeet-tdt-0.6b-v2 | adapter (epoch3) | 0.1900 | NA | NA |
| qwen_exp022 | Qwen3-ASR-1.7B | LoRA (epoch3) | 0.1632 | 0.1977 | 0.4973 |
| qwen_exp023 (checkpoint avg) | Qwen3-ASR-1.7B | LoRA (epoch3) | 0.1631 | NA | NA |
| model_avg (022+023) | - | - | 0.1593 | 0.1914 | 0.4879 |
| qwen_exp025 (checkpoint avg) | Qwen3-ASR-1.7B | LoRA (epoch3) | 0.1618 | NA | NA |
| qwen_exp026 (checkpoint avg) | Qwen3-ASR-1.7B | LoRA (epoch3) | 0.1578 | NA | NA |
| model_avg (022+023+025+026) | - | - | NA | 0.1885 | 0.4842 |
WER results across successive ASR training and ensemble experiments from Kotaro's winning competition submission.
Check out Kotaro's full write-up and solution in the challenge winners' repository.
Sunday¶

Username: legend
Hometown: China
Place: 2nd place Word Track + Noisy Bonus Prize
Prize: $15,000 + $5,000
Background: legend is a freelancer with a strong interest in AI. Their desire to see AI help humanity motivated them to participate in this challenge.
Summary of approach: Fine-tuning Qwen3-ASR-1.7B and ensembling models using weight averaging (“model soup”).
Check out Sunday's full write-up and solution in the challenge winners' repository.
Tang Yongqwei¶

Username: chuxiliyixiaosa
Hometown: Zhejiang, China
Place: 3rd place Word Track
Prize: $10,000
Social media: 初淅沥以萧飒
Background: My profession is algorithm engineering, and I have won multiple championships and runner-up prizes in competitions involving machine learning, deep learning, and large models. I was interested in this competition due to the generous prize money and the matching ASR problem.
Summary of approach: I found that the leaderboard score and local validation score differed significantly, so my main approach was experience-driven. I chose Qwen3-ASR-1.7B as the base model and implemented inference acceleration techniques.
Check out Tang's full write-up and solution in the challenge winners' repository.
Meet the winners of the Phonetic Track¶
Cheng Huige¶

Username: gezi
Hometown: Beijing, China
Place: 1st place Phonetic Track
Prize: $25,000
Social media: Cheng Huige
Background: I am ChengHuige, a software engineer based in Beijing, China.
I have participated in many Kaggle competitions and am a Kaggle Grandmaster, with a peak ranking of #7 worldwide. I have also competed in and won numerous domestic competitions in China, including first place in the Tencent WBDC 2021 (WeChat Big Data Challenge).
For this challenge, all source code was developed with the assistance of GPT-4 and Claude coding agents, while I focused on experiment design, strategy, ablation analysis, and iteration direction.
I was drawn to the unique combination of ASR, phonetics, and low-resource child speech.Children's ASR is a challenging and impactful problem because child speech is highly variable across age, pronunciation development, and first-language transfer. The phonetic track (IPA transcription) adds another layer of difficulty, requiring models to generate fine-grained phonetic sequences rather than standard word outputs.
Summary of approach: My final solution used an 11-model ensemble combining NeMo Parakeet-TDT-0.6B and WavLM-Large models, along with a CatBoost LambdaRank reranker. The two model families complemented each other well: WavLM performed better on shorter audio and external data, while NeMo TDT excelled on longer audio and competition-domain data.
I also used dual-head training to jointly learn IPA and word-level outputs, helping leverage larger word-track datasets. One of the most effective techniques was Concat Mix augmentation, which concatenated multiple audio clips and labels together during training. The final predictions were selected using a CatBoost reranker trained on ensemble N-best outputs.
Single model CV (fold 0, IPA CER ↓):
| Model | Overall | DD | EXT |
|---|---|---|---|
| v17.wavlm-large.ep3.5 | 0.2900 | 0.3445 | 0.2355 |
| v16.wavlm-large.dual_bpe.mix4 | 0.2923 | 0.3477 | 0.2368 |
| v16.dual_bpe.mix2.mix_csss.tdt_only | 0.2913 | 0.3416 | 0.2410 |
| v16.dual_bpe.tdt_only | 0.2931 | 0.3447 | 0.2415 |
| v16.dual_bpe.mix4 | 0.2928 | 0.3393 | 0.2464 |
| v16.aux_loss.dual_bpe | 0.2952 | 0.3418 | 0.2486 |
Cross-validation CER results for individual ASR models on fold 0, comparing performance across in-domain (DD) and external (EXT) datasets.
Ensemble CV (fold 0):
| Method | CER |
|---|---|
| Best single model | 0.2900 |
| Baseline (best-of-models per utt) | 0.2724 |
| Full-avg MBR | 0.2672 |
| CatBoost Reranker (final) | 0.2628 |
| Oracle (upper bound) | 0.1685 |
Fold 0 ensemble evaluation results showing incremental CER improvements from model averaging and CatBoost reranking.
Check out Cheng's full write-up and solution in the challenge winners' repository.
Rein Viegers, Maxim Cardenas Cruz, and Willem Dieleman¶



Team: Epoch VI
Usernames: reinmv, Max28, WillemDieleman
Hometown: Delft, Netherlands
Place: 2nd place Phonetic Track
Prize: $15,000
Social media: Rein Viegers, Maxim Cardenas Cruz, Willem Dieleman
Background: We are team Epoch VI, the AI dream team at TU Delft. We are a team of students that set aside an entire year during our studies to work on AI/ML competitions and projects. This includes doing these ML competitions, and we have already won some competitions in the past, like the segmenting kelp forest competition. Three engineers worked on the phonetic track in this competition, while four others worked on the word track. Our team changes every year, and we are the sixth generation of Epoch VI. Our backgrounds are in Aerospace Engineering and Computer Science. When selecting competitions, we consider factors such as societal impact, timeframe, and personal interest. This challenge fit perfectly into our schedule and presented a completely new problem for all of us.
Summary of approach: Our pipeline consisted of training multiple CTC-based speech recognition models, decoding logits using Minimum Bayes Risk beam search (beam width 50), and ensembling predictions using ROVER. The final ensemble included 13 models: 6 WavLM-Large, 2 HuBERT-Large, 3 Whisper-Large-v3, and 2 Whisper-Medium models. All models were trained with EMA, waveform augmentations (time stretch, pitch shift, and band-stop filtering), and a fixed 30-second batch size. Preprocessing consisted of converting all audio to 16kHz mono.
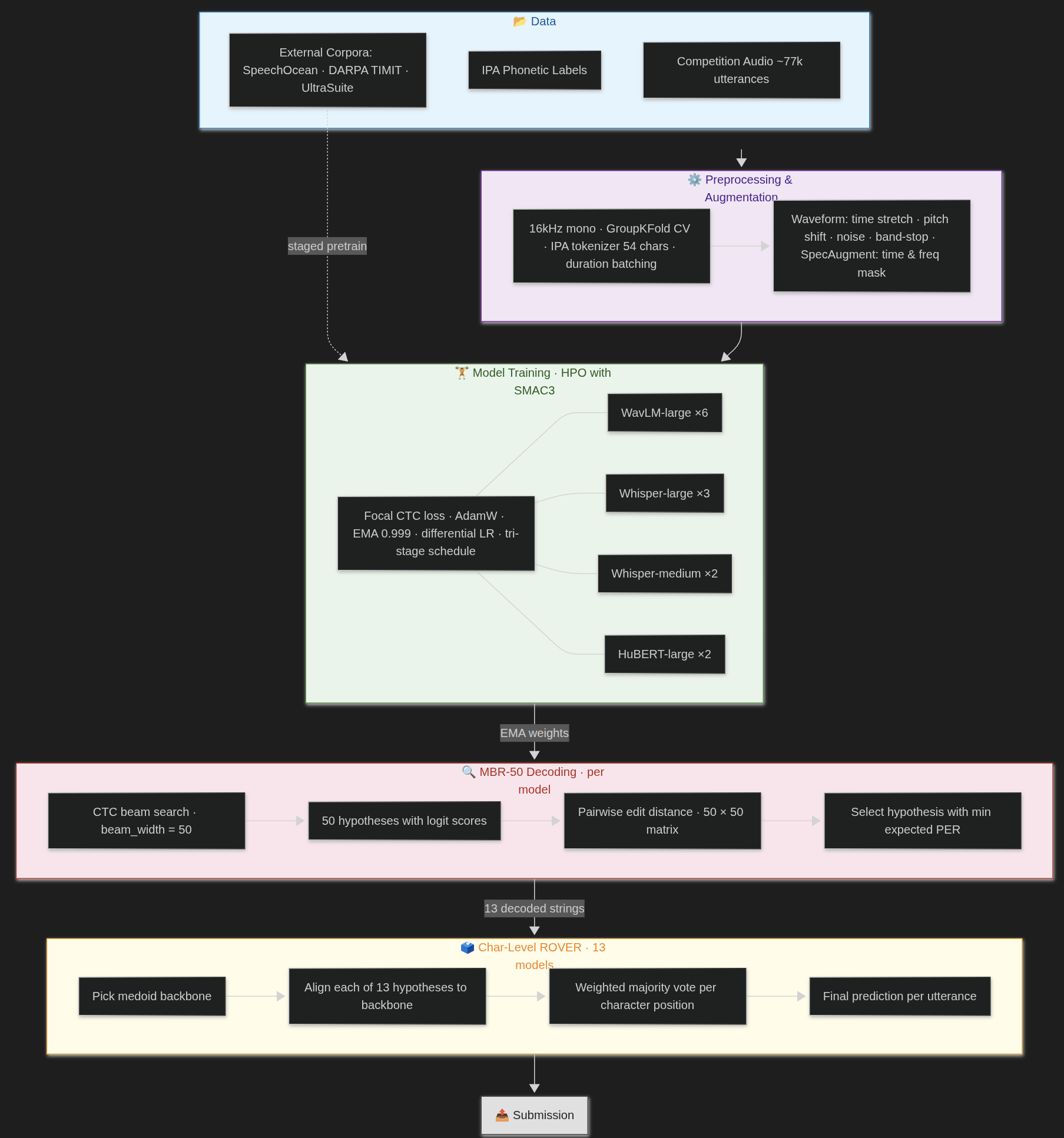
Epoch VI’s visualization of their winning submission pipeline for the On Top of Pasketti competition.
Check out Epoch VI's full write-up and solution in the challenge winners' repository.
Tuan Dung Le¶

Username: dzunglt24
Hometown: Vietnam
Place: 3rd place Phonetic Track
Prize: $10,000
Social media: Tuan Dung Le
Background: I’m currently a PhD student in Computer Science at University of South Florida. My research focuses on applying natural language processing techniques to extract information from unstructured clinical and medical texts, especially in low-resource settings. I also enjoy participating in AI competitions, where I can apply my skills to solve real-world problems.
I have experience with image and text data, but I have not worked with audio data before. I saw this challenge as a valuable opportunity to expand my skill set and learn how to train and evaluate ASR models.
Summary of approach: My solution used a multi-task hybrid CTC-based ASR model that jointly optimized standard CTC loss with a four-way consistency objective. I found that combining W2v-BERT 2.0 and WavLM-Large as a hybrid backbone performed better than using a single W2v-BERT model, although convergence was challenging. To stabilize training, I applied stochastic backbone dropout.
Inspired by the CR-CTC paper, I introduced a four-way consistency loss across different augmentations, internal model dropout states, and noise levels to improve robustness. I also implemented multi-task learning with two CTC heads using additional labels from the Word track, allowing the model to jointly learn word-level and IPA representations.
Finally, I leveraged unlabeled data from the Word track by generating high-confidence pseudo-labels for retraining. The final submission ensembled predictions from four models, providing an additional boost in overall accuracy.
| Strategy | Approx. CER Reduction |
|---|---|
| Add 4-way consistency loss | ~0.015 |
| Hybrid W2v-BERT + WavLM backbone | ~0.002 |
| Multi-task training | ~0.0002 |
| Pseudo-labeling | ~0.002 |
| Final ensemble (3–4 models) | ~0.003–0.004 |
Approximate impact of each modeling strategy on public leaderboard CER, improving the score from 0.2846 to 0.2618.
Check out Tuan Dung's full write-up and solution in the challenge winners' repository.
Meet the winners of the Noisy Bonus Prize¶
Shiqi Li¶

Username: shiqi_47
Hometown: Hangzhou, Zhejiang, China
Place: Noisy Bonus Prize winner
Prize: $5,000
Background: Multimedia algorithm engineer with experience in video enhancement, algorithm engineering, and large language model / multimodal technologies. Children's speech differs greatly from adult speech, with more variable pronunciation, frequent disfluencies, and inconsistent vocabulary. This competition was a good opportunity to explore adapting modern speech foundation models to this domain.
Summary of approach: The solution used full-parameter fine-tuning of Qwen3-ASR-1.7B on children’s speech data, resulting in roughly 329k total training samples. The data was shuffled and split into train and evaluation sets.
Rather than using LoRA or adapter tuning, I chose full-parameter fine-tuning because the 1.7B model could fit on a single 24GB GPU with gradient checkpointing, and full fine-tuning generally provides stronger performance when compute allows. The model was trained for two epochs using bf16 precision and FlashAttention 2, reaching the best checkpoint around step 16,000.
For inference, I used a vLLM backend with greedy decoding and batched prediction sorted by audio duration for efficiency. No data augmentation was used, as the base model already demonstrated strong robustness from pre-training.
Evaluation loss progression during training:
| Step | Epoch | Eval Loss |
|---|---|---|
| 2,000 | 0.22 | 0.2257 |
| 4,000 | 0.44 | 0.2077 |
| 6,000 | 0.66 | 0.2015 |
| 8,000 | 0.88 | 0.1982 |
| 10,000 | 1.09 | 0.1961 |
| 12,000 | 1.31 | 0.1953 |
| 14,000 | 1.53 | 0.1941 |
| 16,000 | 1.75 | 0.1936 |
Progression of evaluation loss over training steps, showing gradual convergence during fine-tuning.
Check out Shiqi's full write-up and solution in the challenge winners' repository.
Mitchell DeHaven¶

Username: mitchelld12345
Hometown: Brighton, CO
Place: Noisy Bonus Prize winner
Prize: $5,000
Background: I work as a Machine Learning Engineer at a health startup, where I primarily focus on speech and NLP topics. This challenge stood out because it involved a particularly difficult speech domain: low-resource, out-of-domain, and potentially atypical speech.
Summary of approach: My winning solution was fairly simple: a single Qwen3-ASR model combined with additional synthetic training data generated using Qwen3-TTS. The additional audio was generated from single-word transcripts created with Claude, specifically designed to produce an exhaustive list of diagnostic terms commonly used by speech-language pathologists.
Check out Mitchell's full write-up and solution in the challenge winners' repository.
Thanks to all the challenge participants and to our winners! We are grateful to the Gates Foundation, whose support made this project possible, as well as additional funding support from Valhalla Foundation and Center for Educational Data Science and Innovation at the University of Maryland.
Image Credit: Image generated using Nano Banana; source images include an image by CDC on Unsplash and an image by tolmacho from Pixabay



















