
The Challenge¶
Motivation¶
Coordinating our nation's airways is the role of the National Airspace System (NAS). The NAS is arguably the most complex transportation system in the world. Operational changes can save or cost airlines, taxpayers, consumers, and the economy at large thousands to millions of dollars on a regular basis. The NAS is investing in new ways to bring vast amounts of data together with state-of-the-art machine learning to improve air travel for everyone.
In order to optimize commercial aircraft flights, air traffic management systems need to be able to predict as many details about a flight as possible. One significant source of uncertainty comes right at the beginning of a flight: the pushback time, that is, the time that a flight leaves the departure gate. A more accurate pushback time can lead to better predictability of take off time from the runway.
In this post, we'll share the results of Phase 1 of this challenge, in which participants were given access to two years of data from 10 U.S. airports and asked to build the best models to predict pushback. This post shares the successes of the participants who crafted the best models for predicting pushback.

Phase 1 Results¶
This was a university challenge! The challenge started off in the Open Arena, where hundreds of participants signed up and tested over 270 submissions. U.S. university-affiliated participants were eligible to enter the Prescreened Arena, in which participants could refine their model on the entire training set and package their model code for evaluation on an out-of-sample dataset.
At the start of the competition, DrivenData developed a benchmark that predicts pushback as 15 minutes before the most recent Fuser estimated time of departure (ETD). Fuser is a data processing platform designed by NASA as part of the ATD-2 project that processes the FAA's raw data stream and distributes cleaned, real-time data on the status of individual flights nationwide. While the Fuser ETD estimate is tuned to predict departure time and not pushback time per se, the correlation between pushback and departure time should make it a strong baseline.
Even so, all of the finalists' models manage to outperform the baseline, nearly halving the average error in terms of minutes between predicted and actual pushback:
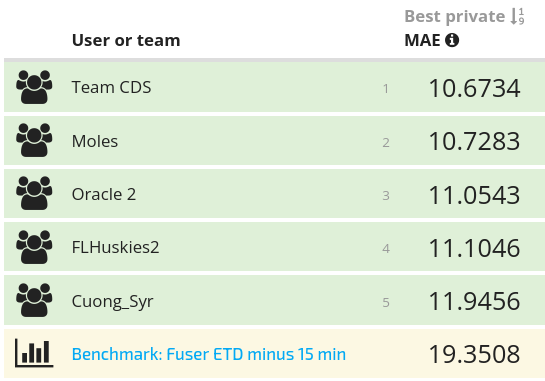
Now, let's get to know our winners and how they created such successful airport pushback models!
Meet the winners¶
Priya Dhond & Alejandro Sáez¶


|
Place: 1st Place
Prize: $15,000
University: New York University
Hometowns: Jersey City, NJ & Barcelona, Spain
Usernames: priya.dhond & alsaco (Team CDS)
Background:
Priya Dhond: Data Scientist specialized in the streaming services industry. Currently pursuing graduate studies at NYU's center for data science.
Alejandro Sáez: Data Scientist with consulting experience in the banking and energy industries currently pursuing graduate studies at NYU's center for data science.
What motivated you to compete in this challenge?
What motivated us to compete in this challenge was the possibility to interact with real-world data from NASA, improve our modelling skills, and be able to contribute to a pressing problem with significant potential impact for the well-functioning of the US aerial transportation network.
Summary of approach:
We approached the problem following the canonical data science workflow, that is: (1) Cleansed and documented the raw data sources, (2) Extracted 298 explanatory features from past periods that are potentially predictive of pushback time, (3) Built 4 families of gradient boosting models leveraging the Catboost implementation, (4) Fine-tuned the parameters, (5) Evaluated the goodness-of-fit of our methods individually and as an ensemble, and (6) Built the necessary functionalities to serve live predictions in the NASA runtime environment.
What are some other things you tried that didn't necessarily make it into the final workflow?
Several additional approaches were attempted but deprioritized or entirely eliminated from the final workflow due to lack of positive impact on the validation MAE. Among them range the following:
- TBFM/TFM features: These did not improve the performance of the models
- Time based cross validation: Averaging across folds based on time splits did not improve the performance of the models either
Brian Hu & Nika Chuzhoy¶


|
Place: 2nd Place
Prize: $12,000
University: Caltech
Hometowns: Moraga, CA & Glenview, IL
Usernames: kinghorton42 & nchuzhoy (Moles)
Background
Brian Hu is a first-year undergraduate student at Caltech majoring in Computation and Neural Systems. Currently, he works with Professor Thanos Siapas to develop machine-learning techniques for animal tracking and behavior quantification in live experimental settings. He is interested in researching human cognition and computational methods for modeling the brain.
Nika Chuzhoy is a first-year undergraduate student at Caltech majoring in Computer Science. Her primary interests lie in theoretical machine learning. She currently does research involving interpretability methods for biological deep learning models.
What motivated you to compete in this challenge?
We chose to compete in this challenge primarily to gain experience in the implementation of machine learning algorithms for data science. The Pushback to the Future Challenge provided us with the opportunity to do so while also working on a problem with real-world data and applications.
Summary of approach:
Our approach was divided into three main stages:
- Benchmark: We trained basic interpretable models such as linear regression and random forest regression to analyze feature importances and determine cross-dependencies.
- Analysis of the data: We identified potentially impactful features that could be extracted from the data, such as aircraft type, number of recent departures, and runways in use.
- Feature extraction: We extracted and encoded features which had been identified as important and filtered the data in order to prevent leakage.
- Modeling: We trained one CatBoost regressor for each of the ten airports provided and optimized hyperparameters.
We iterated upon these stages multiple times as new insights were gained from the process.
What are some other things you tried that didn't necessarily make it into the final workflow?
- A feature representing the length of the queue ahead of each flight, i.e. the number of flights scheduled to depart before a given airplane.
- Features incorporating the rates of arrivals/departures prior to a given flight.
- Partial globalization of the model, such as incorporating delays at airports other than the airport a flight is departing from.
Suraj Rajendran, Matthew Love & Prathic Sundararajan¶



|
Place: 3rd Place
Prize: $8,000
University: Weill Cornell Medicine
Hometowns: Cumming, GA, Houston, TX & Irvine, CA
Usernames: surajraj99, 20matthewl & prathic (Oracle 2)
Background:
Suraj Rajendran is a dedicated PhD student at Weill Cornell, specializing in computational biology. He has a keen interest in the application of artificial intelligence in various fields of healthcare, including genomics and trial emulation. As an aspiring researcher, Suraj is committed to exploring the potential of AI-driven solutions to revolutionize the healthcare industry.
Matthew Love is an experienced software engineer at Qualcomm, where he focuses on embedded systems. His professional interests lie in edge deployment, and he is always looking to apply his expertise in developing cutting-edge technologies to optimize system performance. Matthew's background in software engineering, combined with his passion for innovation, makes him a valuable contributor to the team.
Prathic Sundararajan is a proficient software engineer at Becton Dickinson, with a broad range of interests and experience working at the intersection of technology and various other domains, such as space, defense, and healthcare. His unique perspective and interdisciplinary knowledge enable him to effectively address complex challenges and design innovative solutions to real-world problems.
What motivated you to compete in this challenge?
Our motivation to compete in this challenge stems from a deep-rooted interest in aviation, ATC communications, and related technologies. The opportunity to work with real aviation data and apply our analytical skills to address complex air traffic management issues has been a driving force for our participation. Moreover, we recognize the potential impact of accurately predicting pushback times on overall air traffic efficiency and resource allocation, further fueling our enthusiasm for the challenge.
Additionally, the prospect of collaborating with brilliant minds at NASA during Phase II of the competition is incredibly exciting. We believe that working alongside experts in the field will not only be enjoyable but also provide valuable insights and a chance to learn from their experience. This unique opportunity to contribute to a project of such magnitude and relevance, combined with our personal interests in aviation and passion for problem-solving, motivated us to participate in this challenge.
Summary of approach:
Our approach to predicting pushback times was primarily driven by the choice of tree-based models, as research indicates their efficacy in handling tabular data. To begin with, we examined important features across all datasets and assessed their contribution to trained models. Ultimately, the most significant features were derived from the estimated time of departure (most recent timepoint, average across the last 30 hours, and standard deviation across the last 30 hours), airline code, prediction time, and taxi time. We calculated taxi time using standtimes and arrivals, but this feature did not yield the expected improvements in our model.
To accommodate the unique characteristics of each airport, we trained separate XGBoost models for every airport. These models were trained on data points that were not considered outliers. To identify outliers, we employed an internal XGBRegressor to predict minutes until pushback on a subset of data and calculated the error for each sample within the remaining data. We considered samples with a 'large error' (absolute error greater than 20 or 30, depending on the airport) as outliers. Non-outlier samples were used to train another XGBRegressor, which we refer to as the 'main model.'
During the evaluation, we noticed that our model tended to overestimate or underestimate certain samples significantly. To address this issue, we trained an XGB classifier, the 'estimation classifier,' to predict whether a sample's prediction would be overestimated or underestimated. This model had a modest performance, with an AUC of 0.64.
Our complete pipeline for new samples consists of the following steps: extract necessary features for the sample, input it into the 'main model' corresponding to the originating airport, and predict whether the minutes_until_pushback is overestimated or underestimated using our 'estimation classifier.' Based on the classification, we either subtract or add the median of all over/underestimated values, which were determined and saved during the training of the 'estimation classifier.' This approach aims to refine our predictions and minimize the impact of over- or underestimation on the model's overall performance.
What are some other things you tried that didn't necessarily make it into the final workflow?
Throughout the development process, we explored several approaches that did not make it into the final workflow due to various reasons. Here is a quick overview of these experiments:
-
Additional features: We computed several features based on the literature, such as traffic (based on arrivals and departures at airports), weather conditions, and plane initialization. However, these features did not lead to a significant improvement in the model's performance and were subsequently excluded from the final feature set.
-
Recurrent Neural Network (RNN) with LSTM layers: We experimented with an RNN incorporating LSTM layers to leverage the temporal aspects of the data. While this model showed promising results in the open arena, its performance did not carry over to the pre-screened submission, indicating potential generalization issues.
-
Convolutional Neural Network with LSTM (CNN-LSTM): Another approach we tested was a hybrid model combining CNN and LSTM layers. Despite its potential to capture both spatial and temporal patterns, the CNN-LSTM model proved to be computationally expensive and did not provide significant performance improvements compared to other models.
These experiments, although not included in the final workflow, contributed to our understanding of the problem and allowed us to refine our approach by identifying the most effective techniques and features for predicting pushback times.
Daniil Filienko, Yudong Lin, Trevor Tomlin, Kyler Robison, Sikha Pentyala, Prof. Anderson Nascimento & Prof. Martine De Cock¶

|
Place: 4th Place
Prize: $7,500
University: University of Washington Tacoma
Hometowns: Federal Way, Renton, Lacey, Spanaway, Seattle, University Place, Bellevue, WA
Usernames: daniilf, ydlin, ttomlin, Kylerrobison, sp22, andclay & mdecock (FLHuskies2)
Background:
We are a team of computer science faculty and students at the School of Engineering and Technology, University of Washington Tacoma.
Dr. Martine De Cock is a Professor with expertise in machine learning. Dr. Anderson Nascimento is an Associate Professor with extensive background in information theory and cryptography. Together they lead a research group in privacy-preserving machine learning (PPML). Their group has a proven track record in privacy-preserving machine learning with 1st place positions in the iDASH2019 and 2021 competitions on secure genome analysis, being one of the winners of the 2023 U.S.-U.K. PETs Prize Challenge, a U.S. patent on cryptographically-secure machine learning, and publications in NeurIPS, ICML, PoPETS, IEEE Transactions on Dependable and Secure Computing, and IEEE Transactions on Information Forensics and Security, among others.
Sikha Pentyala is a 3rd year PhD student in the PPML group. She has published her work on the use of secure multiparty computation, differential Privacy, and federated learning for trustworthy machine learning in ICML, ECIR, and workshops at NeurIPS and AAAI. She acted as the student lead in the PPML group's winning participation in the iDASH2021 and 2023 U.S.-U.K. PETs Prize challenges.
Kyler Robison, Daniil Filienko, Yudong Lin, and Trevor Tomlin are senior undergraduate students in computer science. As a team, they have been awarded the 2023 Outstanding Undergraduate Research Award by the School of Engineering and Technology, UW Tacoma.
What motivated you to compete in this challenge?
The federated learning aspect. While there are many data science competitions, only very few are about privacy-preserving machine learning.
Summary of approach:
Our solution for Phase 1 is a gradient boosted decision tree approach with a lot of feature engineering. We trained one LightGBM model per airport. We started with the suggested minutes until ETD (expected time of departure) feature and gradually built out our feature set, spending much of our effort on writing scripts to extract feature values from the train and test data in a reasonable amount of time. We used the LightGBM library for boosted decision trees because it has absolute error as a built-in objective function and it is much faster for model training than similar tree ensemble based algorithms. We experimented with training one global model across all airports, as well as with training one local model per airport, and found that the latter resulted in lower MAE, so we adopted that as our final solution for Phase 1.
To process the large data files and train our models, we used Azure Virtual Machines with a substantial amount of memory provided through the UW Azure Cloud Computing Credits for Research program.
What are some other things you tried that didn't necessarily make it into the final workflow?
- Making a global model, trained on all airports, instead of locally trained models.
- We had tried to utilize xgboost, but it does not perform as well as lightgbm.
- Utilizing weather predictions for the next n hours instead of including exclusively current weather from LAMP.
- Using ETD to predict the number of flights departing within the next n hours.
James Stephen Kotary, Cuong Tran, Anh Nguyen & Giang Tran¶



|
Place: 5th Place
Prize: $7,500
University: Syracuse University, New York, USA
Usernames: jkotary, cuongk14, qahn & tdgiang
Background:
We are a group of two Ph.D. students at Syracuse University and two machine learning engineers working in Ho Chi Minh, Vietnam.
What motivated you to compete in this challenge?
We are interested in the privacy aspect of the challenge and would like to implement a federated learning framework on real world data. The federated learning framework allows different organizations to train a shared global model without the need to share their own local data.
Summary of approach:
In a nutshell, we perform different feature engineering to extract time-series signals from different tables. For example, we extract the day in the week (e.g., Sunday) , block time of the day (e.g., morning), number of departure/arrival flights just before the time of making predictions. After that we train an XGBoost regressor model to predict the minutes until pushback time.
What are some other things you tried that didn't necessarily make it into the final workflow?
We tried other features but it turned out they can not improve the performance (based on the prescreened area ranking). For example, based on TFM table, we computed some statistics on the arrival_runway_estimated_time column, like the difference between the latest subtracted the earliest arrival_runway_estimated_time. These features help to reduce the MAE on Open Area but not on Prescreened Area.
Phase 2 Update¶
But that's not the whole story! At the end of Phase 1, we invited the top five finalists to participate in Phase 2 of the challenge in which they worked with NASA scientists to explore the potential for federated learning in the NAS.
Federated learning is a technique for collaboratively training a shared machine learning model across data from multiple parties while preserving each party's data privacy. There are many public and private organizations that collect flight and airspace related data, but privacy and intellectual property concerns prevent much of this data from being aggregated, and thus hamper the ability to make the best predictions and decisions. The future of machine learning in the NAS will seek to find ways to learn from this data without revealing it, and federated learning is likely to be a key technology.
In Phase 2, the finalists above translated their winning Phase 1 model into a model that can be trained in a federated manner. Teams explored a wide range of approaches from training federated neural network models, to engaging with emerging techniques for training tree-based models, to ensembling public and private models. Their results helped demonstrate how we might make the most of all of the private data streams to keep flights on track. You can check out their code and read their Phase 2 reports in the competition repo.
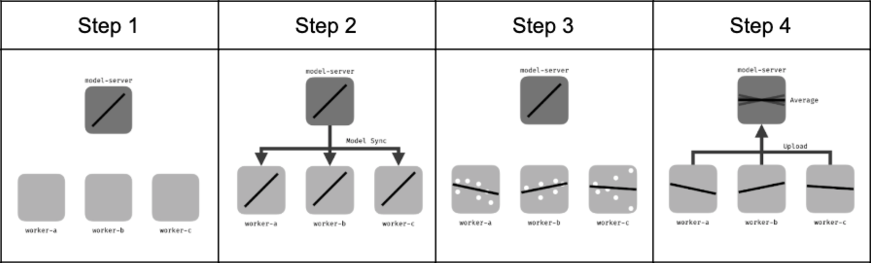
Learn more about the winners' Phase 1 and 2 results by checking out their code and reports in the competition repo!
Tile Image: "Boston Logan Airport, Gate 30 (Jet Blue flight 287)" by Glenn Beltz is licensed under CC BY 2.0.




















{kind=link}