


Meet April¶
On April 1st, DrivenData released a splashily-titled new competition: "Preview: The Future of DrivenData Competitions". The competition announced the debut of DrivenData's own chatbot, April, who was developed to take over evaluation of all competitions.
If you tried submitting prediction to April, you likely found that she was very hard to impress. Some skillful chatbot conversationalists may have successfully coaxed April to reveal some personal information, like the fact that her favorite holiday is April Fools' Day. Wait a minute...
Happy April Fools' Day!
Under the hood¶
April is not actually a live AI model hosted by DrivenData. As has been demonstrated with ChatGPT in recent months, letting people interact with live AI chatbots can be pretty fraught with uncomfortable situations!
Our team had some fun using ChatGPT to generate automatic responses to user predictions in a variety of different "personas" which were embedded as static response banks. For each persona, we presented ChatGPT with a prompt like "Please generate 20 uncertain or negative responses for a magic 8 ball in the style of technical jargon". Our favorite responses were the ones in the style of TV show character Ted Lasso and Great British Bake Off judge Paul Hollywood. You can use the "I don't like the feedback I'm getting" button to switch April to another persona.
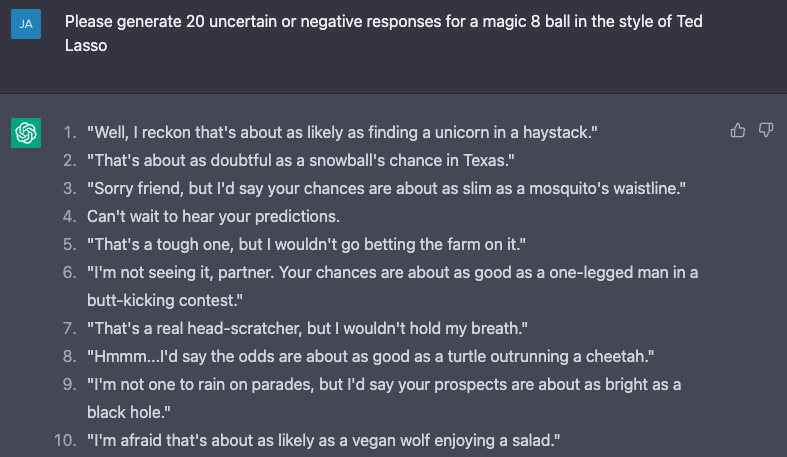
Other messages from April, such as the greeting, the initial message in the feedback chat box, and the apology when switching personas were also generated by ChatGPT. These were done with prompts like "Write 20 variations of 'Hello. I'm looking forward to working with you.'"
April's demo is entirely implemented with client-side Javascript. For most of April's dialogue, the response banks were randomly shuffled on page load, and then the demo would simply iterate through them. For the prediction feedback, a simple hash was calculated from the input text so that the same input would deterministically produce the same feedback. To see the source code for April's demo, you can inspect the HTML source of the demo's web page. We've also open-sourced a standalone copy of the demo on GitHub, which may be more convenient way to read the code. Here's a direct link to the static responses that April could make.
Let's get serious for a moment¶
We live in an exciting time where the capabilities of AI technologies are changing rapidly. There is a lot of energy around how chatbots like OpenAI's ChatGPT and Google's Bard might be used in imaginative new ways. Regardless of how much one buys the hype, it is clearly remarkable how well the newest generation of large language models mimic human writing and often respond with real, useful knowledge. Let's also not forget the groundbreaking improvements last year in image generation from models like DALL-E, MidJourney, and Stable Diffusion.
However, any technology also has the potential to be misused and cause harm, whether intentional or unintentional. Deploying models ethically and responsibly involves hard conversations both upfront and after deployment. DrivenData has created a data science ethics checklist tool named Deon, which is more relevant than ever for people considering the use of modern AI models. Deon is a framework for incorporating ethical checks into the development process of data science applications. It includes a default checklist that is broadly applicable to most data science projects.
Ethics is nuanced, and there is rarely one right answer. The goal of Deon is not to tell you what to do, but rather to provide a starting point for thoughtful discussions about the relative trade-offs and risks involved in a project. Sections D and E on "Modeling" and "Deployment" from Deon's default checklist are especially relevant when using a model provided by a large AI lab, such as ChatGPT from OpenAI. Below are some selected items from the checklist.
- D.5 Communicate bias: Have we communicated the shortcomings, limitations, and biases of the model to relevant stakeholders in ways that can be generally understood?
One of the challenges with AIs like ChatGPT is that the limitations and shortcomings are often not readily obvious. For example, they are known to "hallucinate", where they provide information with the appearance of objective knowledge even if it is entirely fabricated. This phenomenon has already led to recent real-world problems: misuse of AI chatbots has led to misunderstandings about a business' services, disruptive confusion about laws, and wrong medical information.
- D.4 Explainability: Can we explain in understandable terms a decision the model made in cases where a justification is needed?
Having as clear of an understanding as possible about how these models work is important to identifying the risks and failure modes. Well-known researchers have dubbed large language models to be "stochastic parrots", which can be a useful framing for setting expectations about these models' capabilities. Ultimately, there is a lot that cognitive science still doesn't know about human cognition, and so there is debate among AI researchers whether large language models could have emergent cognitive capabilities beyond parotting, or not. How to even evaluate these models' capabilities in a reliable, scientific way is not straightforward or settled.
- D.2 Fairness across groups: Have we tested model results for fairness with respect to different affected groups (e.g., tested for disparate error rates)?
Models like ChatGPT are typically trained on large datasets of internet content and can reflect the biases present in that data. The previously mentioned "stochastic parrots" paper has extensive discussion about the risks and limitations of internet content datasets. This is a hard problem, and one that even OpenAI readily recognizes as still an important shortcoming of ChatGPT.
Finally, the work doesn't end when the model is deployed. Even after precautions to mitigate harms upfront, monitoring and plans are needed to address problems that still can arise. We expect the below questions to be especially relevant for teams thinking about deployments:
- E.1 Monitoring and evaluation: How are we planning to monitor the model and its impacts after it is deployed (e.g., performance monitoring, regular audit of sample predictions, human review of high-stakes decisions, reviewing downstream impacts of errors or low-confidence decisions, testing for concept drift)?
- E.2 Redress: Have we discussed with our organization a plan for response if users are harmed by the results (e.g., how does the data science team evaluate these cases and update analysis and models to prevent future harm)?
- E.4 Unintended use: Have we taken steps to identify and prevent unintended uses and abuse of the model and do we have a plan to monitor these once the model is deployed?
Thoughtful governance, intentional processes, and human-centric design are critical to using this new technology in a safe and responsible way. Our hope is that Deon can be a useful tool to prompt the important discussions needed.
Though April won't really be helping us with DrivenData competitions, who knows what the future might hold as AI continues to progress! Thank you for celebrating April Fools' Day with us.



















