
Differential Privacy Temporal Map Challenge¶
Large data sets containing personally identifiable information (PII) are exceptionally valuable resources for research and policy analysis in a host of fields supporting America's First Responders such as emergency planning and epidemiology.
Temporal map data is of particular interest to the public safety community in applications such as optimizing response time and personnel placement, natural disaster response, epidemic tracking, demographic data and civic planning. Yet, the ability to track information related to a person's location over a period of time presents particularly serious privacy concerns.
The goal of the Differential Privacy Temporal Map Challenge (DeID2) is to develop algorithms that preserve data utility as much as possible while guaranteeing individual privacy is protected. The challenge features a series of coding sprints to apply differential privacy methods to temporal map data, where one individual in the data may contribute to a sequence of events.
Sprint 1: 911 Calls in Baltimore¶
Sprint 1 was open to submissions from October 1st to November 15th 2020. This sprint featured data on 911 calls in Baltimore made over the course of a year. Participants needed to build de-identification algorithms for generating privatized datasets that reported monthly incident counts for each type of incident by neighborhood.
The temporal sequence aspect of the problem is especially challenging because it allows one individual to contribute to many events (up to 20). This increases the sensitivity of the problem and the amount of added noise needed.
Many techniques from DP literature are not designed to handle high sensitivity. To overcome this, winning competitors tried different creative approaches:
- Subsampling: Only use a maximum of k records from each person, to reduce sensitivity to k.
- Preprocessing: Subsampling (only use a maximum of k records from each person, to reduce sensitivity to k), and reducing the data space by eliminating infrequent codes.
- Post-processing: Clean up the noisy data by applying various optimizing, smoothing and denoising strategies (several clever approaches were used, check out the solution descriptions below).
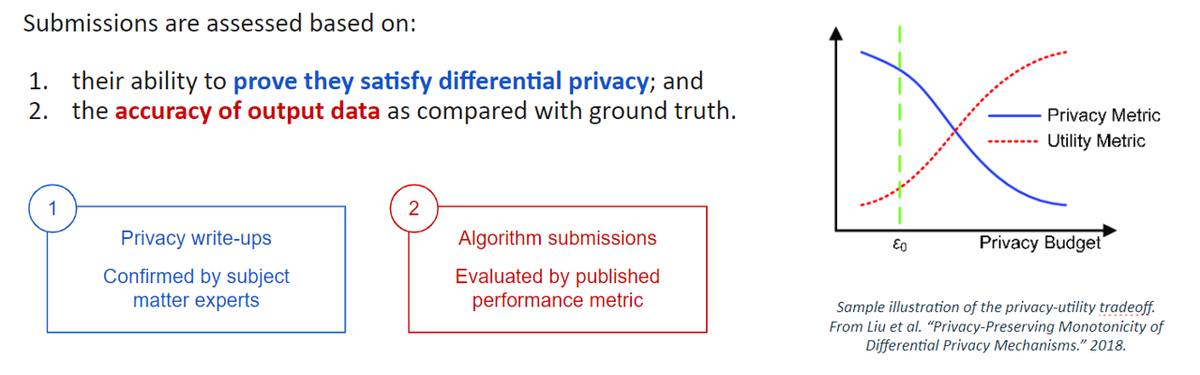
These solutions were evaluated based on scores of data utility at different levels of guaranteed privacy (indicated by epsilon). In this sprint, solutions were evaluated using a "Pie Chart Evaluation Metric", designed to measure how faithfully each privatization algorithm preserves the most significant patterns in the data within each map/time segment.
Note: Measuring utility of privatized data is still an area of active development. In fact, this is the motivation behind the Better Meter Stick for Differential Privacy contest of DeID2, where public voting on submitted ideas starts this week!
|
|
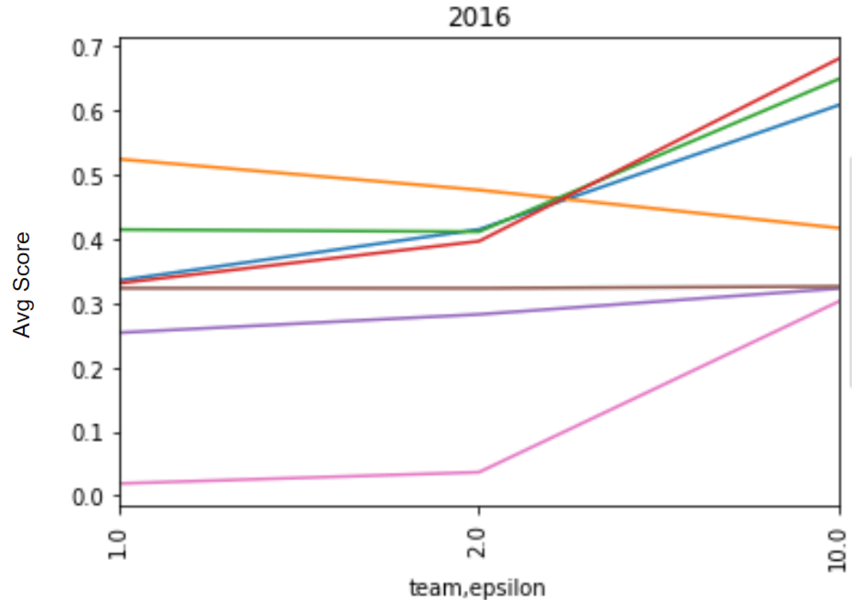
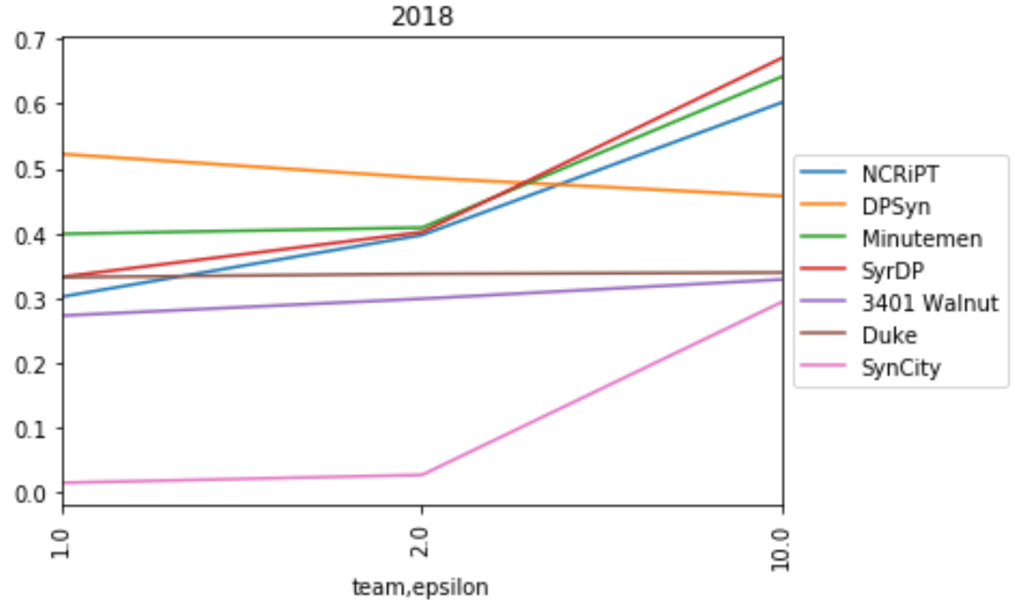
Average scores by epsilon for 2016 and 2018 Baltimore 911 call data, displayed for teams whose final scoring solutions were validated as differentially private.
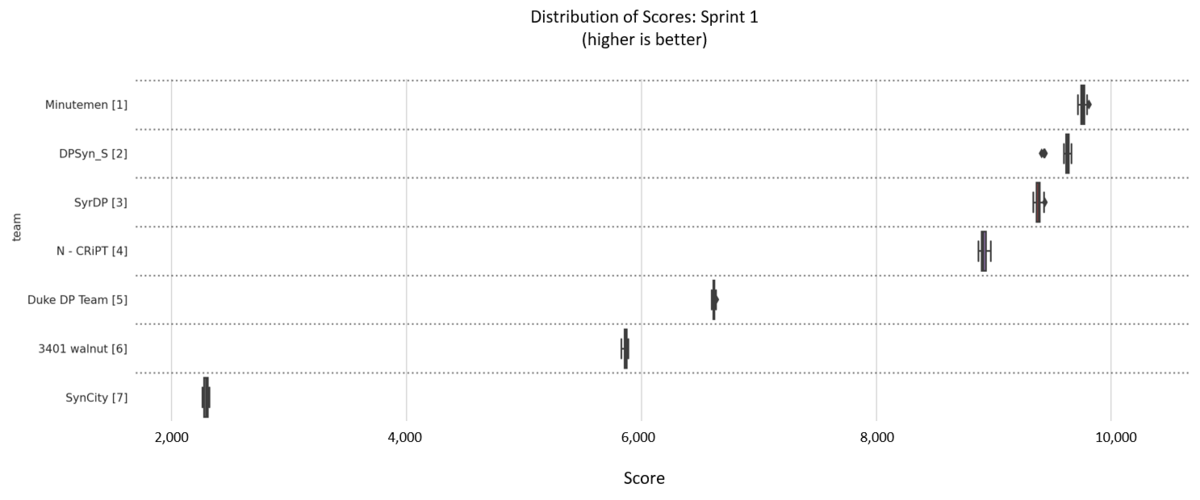
Visualization of boxplots showing the distribution of scores produced by each solution when run for multiple iterations. The box represents the 25th, 50th (median), and 75th percentiles, while the whiskers represent 1.5 times the interquartile range and dots represent outliers. In general the distributions cluster tightly around their most probable values with little variation.
In the end, 7 teams achieved final scoring submissions that were validated as differentially private. To handle the high sensitivity and large noise at smaller epsilon values, many teams used techniques to reduce the sensitivity (subsampling, reweighting). These strategies can be very helpful for lower values of epsilon; but from the evaluation scores, we see that they can also sometimes prevent algorithms from taking full advantage of lower noise values at higher values of epsilon, resulting in a somewhat flat privacy/utility trade-off. The same processing that increases noise resistance can also reduce the quality of the data you're working with, by discarding or dampening some signals in the data.
To handle some of these challenges, the first place winner combined several techniques and tailored their algorithm to the value of epsilon being used. In general, for all competitors as we move on to the next sprint, it's a good idea to examine and really understand the behavior of your pre-processing and post-processing algorithms. The competitor pack visualizer can be a great tool for understanding where your algorithm performs its best, and in what conditions it may need further tweaking.
Congratulations to all the participants in this sprint! Meet the winners below and check out their approaches to help public safety agencies share data while protecting privacy!
Participate in Sprint 2¶
Looking to get in on the action? Submissions for Sprint 2 are now open, with a new $39,000 prize purse! Keep in mind, you are welcome to join in Sprint 2 regardless of whether you participated in the previous sprint.
This sprint includes data from the American Community Survey (ACS), along with simulated individuals, time segments (years), and map segments (PUMA). Because there are more features, you will also find a different output format and scoring approach in this sprint. Rather than submit total counts of record types, participants will submit a list of records within each time/map segment (i.e. synthetic data).
If you haven’t worked with synthetic data before, you might like to look through some of the solutions for the NIST 2018 Differential Privacy Synthetic Data Challenge (DeID1), which you can find here (scroll down to the Challenge section). We're excited to see what you come up with!
Meet the winners: Sprint 1¶
Minutemen¶

|

|

|

|

|

|
Place: 1st
Prize: $10,000
Team members: Ryan McKenna, Joie Wu, Arisa Tajima, Brett Mullins, Siddhant Pradhan, Cecilia Ferrando
Hometown: Cumberland, ME; Norristown, PA; Tokyo, Japan; Gainesville, GA; Mumbai, India; Torino, Italy
Affiliation: UMass Amherst
Background:
We are graduate students at UMass who do research on differential privacy.
What motivated you to participate?:
We are all differential privacy researchers and we found the temporal and geographical aspect of the challenge very interesting.
Summary of approach:
To reduce the sensitivity, we preprocessed the data by subsampling to reduce the max individual contributions. For each epsilon we had different strategies. For epsilon below 1.5 we needed techniques that introduced more modeling assumptions and that for epsilon above 1.5 the Laplace mechanism did quite well. For epsilon below 0.3, we found insignificant incidents from the 2019 data and merged and distributed Laplace noise among them. For epsilon between 0.3 and 1.5, we measured noisy 2-way marginals using the Laplace mechanism. We then used a marginal-based inference engine to estimate a 3-way histogram of the dataset from the marginals.
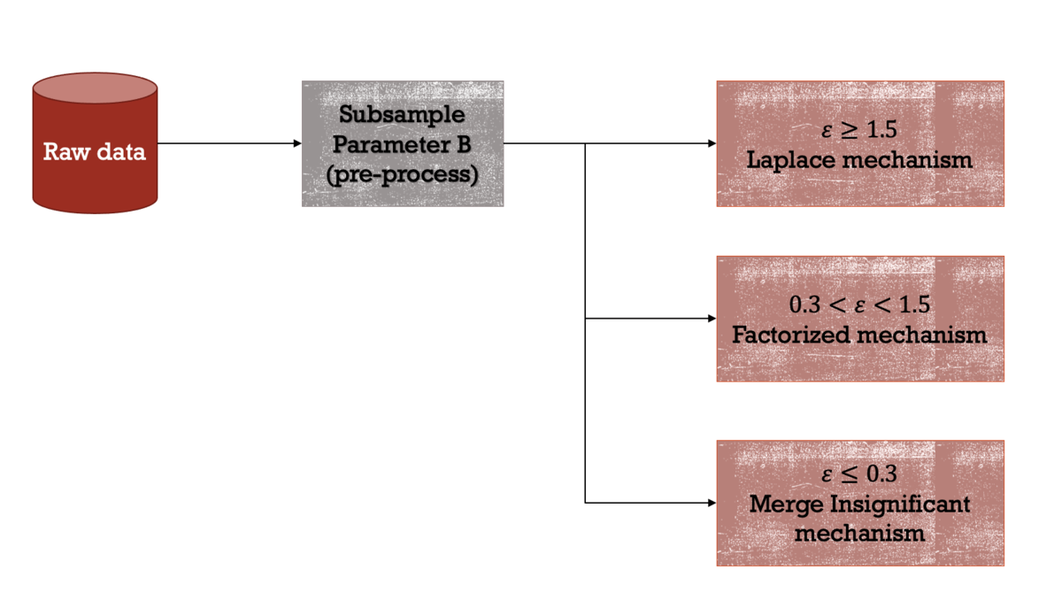
DPSyn_S¶
Place: 2nd
Prize: $7,000
Team members: Ninghui Li, Zitao Li, Tianhao Wang
Hometown: West Lafayette, IN; China
Affiliation: Purdue University
Background:
We are a research group from Purdue University working on differential privacy. Our research group has been conducting research on data privacy for about 15 years, with a focus on differential privacy for the most recent decade. Our group has developed state-of-the-art algorithms for several tasks under the constraint of satisfying Differential Privacy and Local Differential Privacy.
What motivated you to participate?:
We have expertise in differential privacy. We also participated in earlier competitions held by NIST and got very positive results. We believe this is a good opportunity to think more about real world problems and explore the designs of algorithms.
Summary of approach:
The evaluation metric partitions the dataset into 3336 subsets (278 neighborhoods times 12 months), and for each subset, compares the distribution over 174 incident types with the ground truth. This effectively asks for a full contingency table. When the privacy parameter epsilon is sufficiently large, using the Laplacian mechanism to obtain a full contingency table suffices. However, when epsilon is small, the full contingency table is too noisy, and the given public data can provide a better estimate. Our approach privately chooses which method to use.

SyrDP¶
Place: 3rd
Prize: $5,000
Team members: Fernando Fioretto, James Kotary, Cuong Tran, Jingwen Xu
Hometown: Syracuse, NY
Affiliation: Syracuse University
Background:
We are the AIPOpt Lab at Syracuse University. The lab is led by Prof. Fioretto and our research focuses on differential privacy, machine learning, and optimization.
What motivated you to participate?:
We were motivated by wanted to test one of our recent approaches for private data release that seemed to work well on structural datasets.
Summary of approach:
In addition to using a classic output perturbation mechanism, the approach relies on privately answering a selected set of additional queries that are used to improve the accuracy of the data-release mechanism. This post-processing step uses convex optimization to redistribute the noise on the private answers to enforce consistency.
N - CRiPT¶
Place: 4th
Prize: $2,000
Team members: Bolin Ding, Xiaokui Xiao, Kuntai Cai, Ergute Bao
Hometown: China
Affiliation: National University of Singapore; Alibaba Group
Background:
We are people who are interested in differential privacy, including computer scientists and PhD students.
What motivated you to participate?:
Differential privacy is a promising direction which raises a lot of attention of the community. We want to dive into differential privacy and particularly, we want to know how far away we has explored in this field.
Summary of approach:
We query the histogram of the dataset and use two denoising methods to postprocess the histogram. Block-matching and 3D filtering (BM3D) tries to denoise by finding common patterns in the histogram. Graph total variation regularization (GTVR) tries to denoise using the smoothness of the histogram. We believe that common patterns and smoothness are important features for temporal data.

Duke DP Team¶
Place: 5th
Prize: $1,000
Team members: Johes Bater, Yuchao Tao
Hometown: St. Louis, MO; Shanghai, China
Affiliation: Duke University
Background:
We are from the Duke privacy group and we study security and privacy.
What motivated you to participate?:
It’s a good chance to see how privacy technologies can be applied to real problems.
Summary of approach:
Our approach is decomposed into two steps: truncation and reweighting. Truncation is to ignore the incidents that are not in the significant bins learned from the public 2019 data. Reweighting is to reweight each remaining incident so that the total weight associated with each sim_resident is only a constant gamma. The global sensitivity thus is reduced to gamma, so adding laplace noise to each bin with scale gamma / epsilon will satisfy the \epsilon-DP requirement. The value of gamma is chosen carefully to balance the bias from truncation.
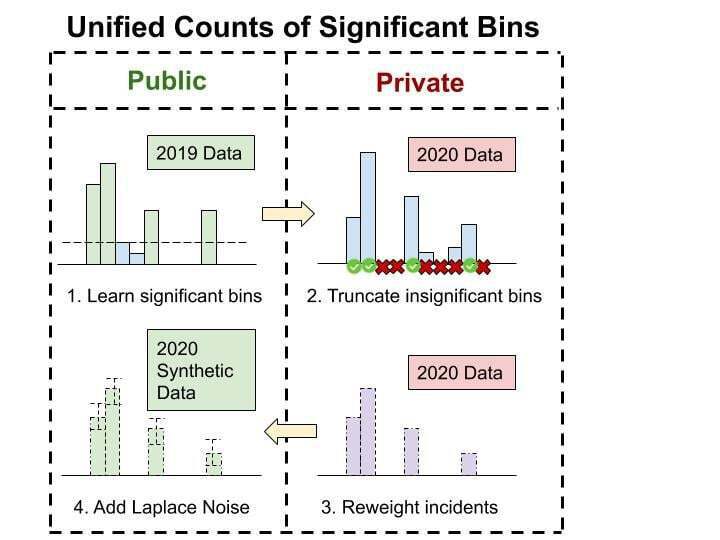
Progressive Prizes¶
Finally, congratulations to Duke DP Team, 3401 Walnut, Minutemen, and DPSyn_S who each won a $1,000 progressive prize this sprint! As a reminder, progressive prizes are awarded part-way through each sprint to four eligible teams with the best scores to date, with precedence given to solutions that are pre-screened as satisfying differential privacy.
Don't forget, submissions are now open for Sprint 2. Head over to the competition for your chance to tackle a new problem and win $39,000 in prizes. Good luck!
Thanks to all the participants and to our winners! Special thanks to NIST PSCR for enabling this fascinating challenge!



















