

LLM APIs and Prompting¶
I spent last Friday and Saturday at the Full Stack Deep Learning LLM Bootcamp. It was great to take a few days away from normal work and dive deep into LLMs. I’ve spent the last decade building machine learning systems and even working with LLMs for real applications as early as 2019. The pace of progress in this area has demanded dedicated attention, so I’ll try to give my ML practitioner's view here. All the takeaways I had are too much for one post, so I’m starting a series with my observations.
This first post is on working with LLM APIs—that is, using OpenAI’s GPT APIs, including ChatGPT, Anthropic, Cohere, and newer entries like AWS Bedrock and HuggingChat. (Note that as of April 26, Google is still caught in mud with their LLM products; there is no Bard API as of yet, but Google IO is coming up in a couple weeks).
The reason I’m starting with these hosted LLMs is the same as my first takeaway from the workshop:
“Only use open source if you really need it”
This is definitely not how we usually build at DrivenData—often we start with simple open source solutions and scale up to more powerful models and tools as we prove value. Modern LLMs are different for two reasons. First, there’s a step-change in accuracy and therefore usefulness from the scale of these LLMs. It is nearly impossible to replicate this in a sandbox. Second, the compute infrastructure to tune, deploy, maintain, and monitor your own LLM is (currently) hard to incrementally scale up. This means that if you’re building on LLMs, the process should start with using an API. If the hosted model proves valuable, explore self-hosting and more. Don’t start with Llama, Alpaca, Open Assistant, or LorA until you’ve proved you need it.
Fine-tuning is not what you think it is
You see a lot of talk about fine-tuning LLMs these days for specific domains. LLMs for doctors’ notes. LLMs for legal opinions. LLMs for comedy sketches. Almost no one—even launched products—is actually fine-tuning in the classical sense, and it may not even be necessary.
Fine-tuning LLMs requires a careful process and the models are still prone to catastrophic forgetting. If you fine-tune an instruction-trained model (e.g., ChatGPT), it forgets its ability to chat. To fine-tune for a domain, you need to both tune the pretraining task (i.e., next word prediction) and then also retrain with RLHF. Potentially instruction datasets like Alpaca, Dolly, and Open Assistant will make re-training the chat behavior easier in the future, but it’s too early to have evidence this is practical. More on this in my next post.
Everything is context-stuffing
If people aren’t fine-tuning, what are they doing? The answer: stuffing more and more information into the “context.” These models are doing a simple thing: predicting the next word based on input text. There aren’t additional systems that do parsing or retrieval based on a user’s input for the current generation of models. What this means is that everything the model may need to produce results must be part of what is passed in. Here’s how that looks:
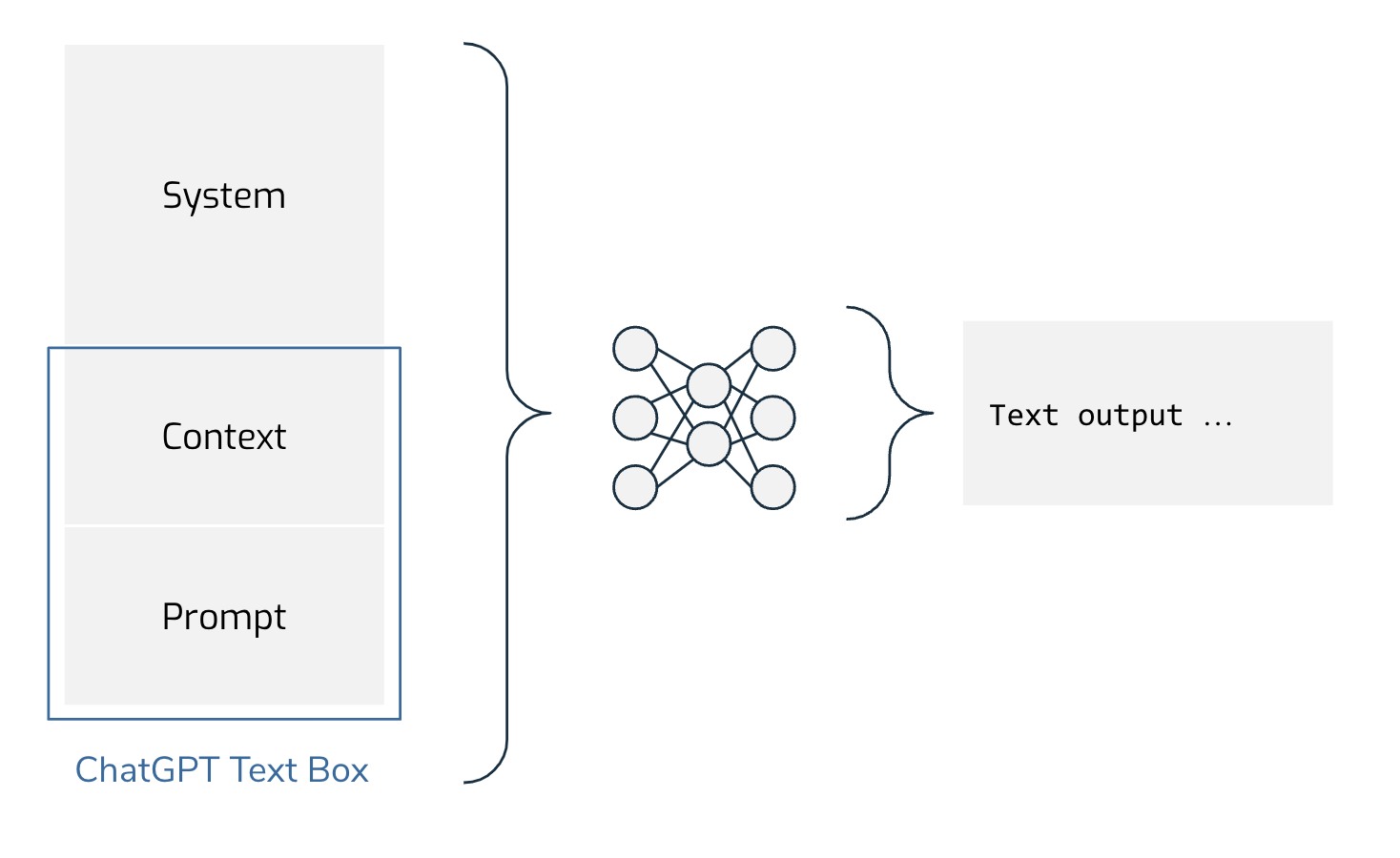
The system portion is the generic prompt provided by the LLM host. For what a user can provide, it is helpful to think about this as divided into a “context” and a “prompt.” In the context, you should put any references, facts, background information that is not in the model. These may be up-to-date facts that the LLM didn’t know at training time, or private knowledge that the model would not have had in its dataset. Many LLM applications are being developed right now by building a retrieval system to drop relevant facts in the context and then leave the prompt open to end users.
For example, if you want the model to generate an article comparing this year’s best picture Oscar nominations, you should put summaries from IMDB of the nominated movies, careers of key actors, and previous work done by the directors into the context so that it can be mentioned in the article. Or, maybe you want a chatbot customer service agent. In this case, your developers will build a retrieval task that reads a user’s last message, searches your knowledge base, and copies relevant articles in the context. The prompt portion will be what the end user asks the agent.
There is one major limitation. Currently, there is around a 4,000 token limit for the context, which means you are restricted in how much of this background you can provide. There is a going to be a boom of compression tricks, context pruning, model architecture revision, retrieval augmentation, and hardware support to try to expand what can be passed in as context—in fact, we saw just this week a paper proposing a method for expanding the effective context length of LLMs to 1 million tokens.
Prompting is a bag of tricks
The quintessential result for prompting “let’s think step by step” shows the dramatic effect prompts can have. You’ll see twitter influencers everywhere building prompting trick threads. The short story is that these tricks work. The long story is this is not where I am investing my time.
First, prompt tricks are likely not robust and vary model-to-model. Retraining, new data, and new architectures may obsolete your most effective prompts, and you have no control over this (and may not even realize it has happened until too late, since you do not control the model). Second, there is currently no good theory of prompt engineering based on reverse-engineering what is in the network. My personal opinion is that this theory is coming. We will be able to interrogate model weights to best understand how to prompt. Memorizing a bag of tricks now has a short shelf life. I will spend time optimizing task-specific prompts, but not breathlessly following all the prompting going on now.
LLMs should replace first-pass NLP models
There was a great paper in 2017 called “A Simple but Tough-to-Beat Baseline for Sentence Embeddings.” A simple baseline that uses “dumb” word vectors is not substantially outperformed by sophisticated neural network based embeddings that were being published at the time. Even more practically, bag-of-words and logistic regression has been a solid baseline for nearly all text classification tasks that we have seen in the past. The previous best practice was to start with these simple solutions and then investigate if these easy-to-code, easy-to-deploy models could be outperformed.
This has changed. Our new baseline for all NLP tasks will be asking an LLM to do the task. This includes all kinds of tasks including NER, deduplication, text classification, ranking, and more. Using the LLM as your baseline obviates a ton of time that we have traditionally spent preparing data, cleaning text, and making tokenization decisions. As this becomes our first-pass approach for NLP tasks, we’re also changing what the second-pass approach will be: ensembling.
Like always, ensembling wins
Ensembling is a common technique in machine learning where you combine the output of different models trained to do the same task. The value of ensembling ML models is proved out in nearly every machine learning competition. This is because ensembling combines the strengths of multiple models, resulting in more accurate predictions. Ensembling may seem impossible for LLMs since you don’t control the models, but it’s not. You can ensemble LLMs in three main ways.
First, by using multiple providers with different LLMs. Calling multiple LLM APIs, storing the results, and combining them (at the embedding level or comparing the actual text output).
Second, you can vary your prompt text. The important thing to realize here is that you should be tracking your prompts and outputs rigorously in a database so that you can actually do the ensembling, not just experimenting in an ad-hoc way and going with what feels best.
Third, a number of the models support varying hyperparameters (e.g., you can prompt ChatGPT to set its temperature parameter, but you can also set it via the API). I’m going to be rigorous in my tracking so I can treat all my generations as potential inputs to an ensemble.
There is enormous opportunity in assessment for LLM output
Metrics have been terrible for automatically assessing language generation for a long time. We still can’t simultaneously measure coherence, factfulness, and relevance (which is why these models are built with RLHF in the first place). All three of these components are critical to good text generation, but every application will have different tolerances for these classes of error. This is going to matter for both generated text and generated code. There’s going to be a huge amount of value created by organizations that can measure each of these in a specific context to best evaluate and harness LLMs. Some of this will be done by other automated agents, some will be human feedback loops—especially ones that can be captured passively—and some will be novel methods.
For me, these were some of the most valuable takeaways when thinking about LLM APIs and prompting. I’d love to hear your thoughts! Stay tuned for a deeper dive on training and building your own models, the future of LLMs, and a deeper dive on LLMs data ethics that builds on my initial thoughts.
If you’re looking for an expert team to work with you to figure out AI strategy, build and refine prototypes, and move ML systems to production, reach out to us at DrivenData Labs.



















