Hateful Memes¶
Multimodal hate speech can be particularly challenging for AI to detect because it requires a holistic understanding of the meme. The top submissions substantially exceed the performance of the baseline models we provided as part of the challenge. We hope others across the AI research community will continue to build on their work and be able to improve their own systems.
Dr. Douwe Kiela, Facebook AI Research Scientist and author of Hateful Memes dataset
Take an image, add some text: you've got a meme. Internet memes are often harmless and sometimes hilarious. However, by using certain types of images, text, or combinations of each of these data modalities, the seemingly non-hateful meme becomes a multimodal type of hate speech, a hateful meme.
Detecting hateful content can be quite challenging, since memes convey information through both text and image components. The modes of a meme are both independently informative––a text segment or image by itself can be hateful or not––and jointly informative, as demonstrated by the example memes below. Each image or text segment is independently innocent, but taken together the image-text combinations yield content that is not very nice, to say the least!

Independently innocent text or image content can become harmful content when combined into a meme.
While the above toy example may seem relatively harmless, it conveys a very real complexity that makes detecting hateful memes online a subtle and difficult task.
The objective of this competition was to develop multimodal models––which combine text and image feature information––to automatically classify memes as hateful or not. The team at Facebook AI created the Hateful Memes dataset to reflect this challenge and engage a broader community in the development of better multimodal models for problems like this. The challenge data is also currently available for ongoing research and development.
Model performance and leaderboard rankings were determined using the AUC ROC, or, the Area Under the Curve of the Receiver Operating Characteristic, a number between 0 and 1 (higher is better). The metric measures how well your binary classifier discriminates between the classes as its decision threshold is varied, effectively telling us how good a model is at ranking samples in addition to classifiying them. The top five submissions achieved AUC ROC scores of 0.79–0.84, all exceeding the baselines reported in the paper accompanying the dataset release. These scores also corresponded to accuracies of 70–75%, compared to accuracy under 65% for the top benchmark from the paper.
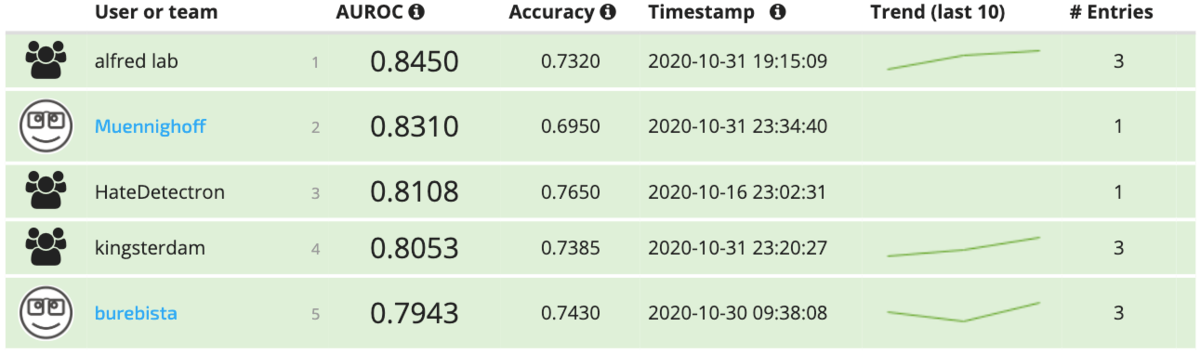
Over the course of the competition, we saw over 3,000 participants enter the challenge, visiting the site from more than 150 countries around the world! Congratulations to all the participants, and to the five teams that managed to top the leaderboard. All prize-winning solutions from this competition are linked below and made available for anyone to use and learn from. ** Meet the winners and learn how they manufactured their multi-modal models! **
Meet the winners¶
Chu Po-Hsuan¶

Place: 1st
Prize: $50,000
Hometown: Keelung, Taiwan
Team: alfred lab
Username: ToggleC
Background:
I’m a ML engineer with two years of experience working at a startup that builds mobile surveillance camera apps. My expertise is mainly on computer vision and image processing.
What motivated you to compete in this challenge?
The main reason I will participate in this challenge is to challenge myself to solve challenging problems I normally don't encount in my day job. And the chance to work with models that deal with both image and text is pretty rare.
Summary of approach:
- First using OCR and inpaint model to find and remove the text from the image. This will improve the quality of both object detection and web entity detection.
- Using the clean meme image to do bottom-up-attention feature extraction, web entity detection, human race detection. Those tags will give the transformer models much more diverse information to work with.
- Train the following models: extended VL-BERT, UNITER-ITM / VILLA-ITM, vanilla ERNIE-Vil
- Average all predictions
- Apply simple rule-base racism detection using meme text, race tag, entity tag, skin tone.
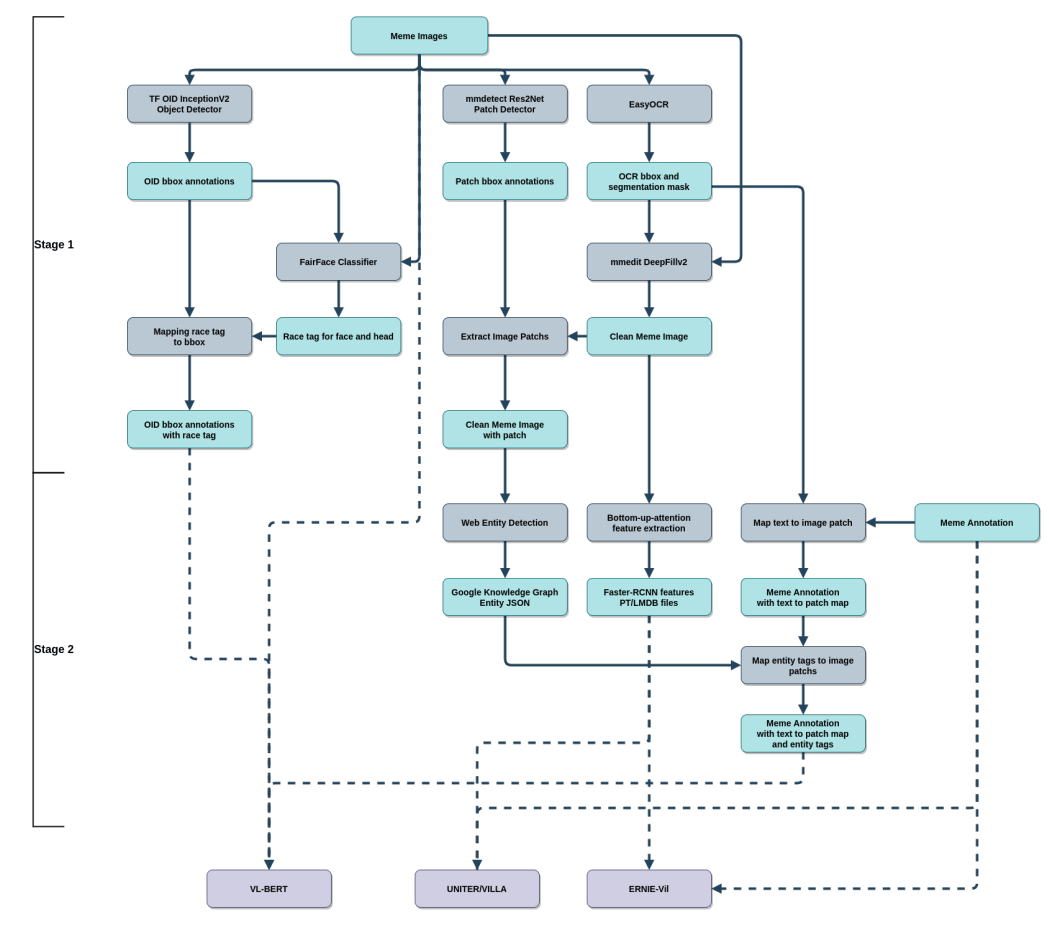
Diagram of the component parts of alfred lab's model.
Check out alfred lab's full write-up and solution in the competition repo.
Niklas Muennighoff¶

Place: 2nd
Prize: $25,000
Hometown: Munich, Germany
Username: Muennighoff
Background:
I’m an undergrad at PKU studying Comp. Science & Business Management. I’m really humbled (& fascinated) that today we can create something more intelligent than ourselves (even if only in narrow areas), so I devote most of my time to studying AI. Especially transformers, graph neural networks, reinforcement learning & putting the software to work in robotics are my areas of interest!
What motivated you to compete in this challenge?
I really want to intern at Facebook AI Research, so I thought this would be a great opportunity to learn more about the work they do. I think we learn best if we’re in an environment surrounded by people smarter than us, so it was pretty tough participating in this competition alone – I hope I’ll be able join such an environment at a place like FAIR one day!
Summary of approach:
Current state of the art (2020) in NLP tend to be transformer models. Since the problem at hand requires combining image & text input, it lends itself to the opportunity of applying the same NLP transformers to images. Yet since images contain far more information than words, it makes sense to pre-extract the most important content first via CNN’s such as FasterRCNN due to hardware limits. The transformer models I have implemented then take two different approaches of dealing with the extracted images and the text:
Run them through separate transformers and then combine them at the very end; A two-stream model Run them in parallel through the same, big, transformer; A one-stream model
The second approach is superior as it allows the model to early-on understand the connections between the image and the text, yet I still include both types of models and average all of their predictions to obtain more diverse & stable results.
I think the approach could be improved by feeding in the original images into transformers / graph-like networks without extraction, however current hardware limits make this unfeasible and hence we make use of locally limited convolution operations in the extraction.
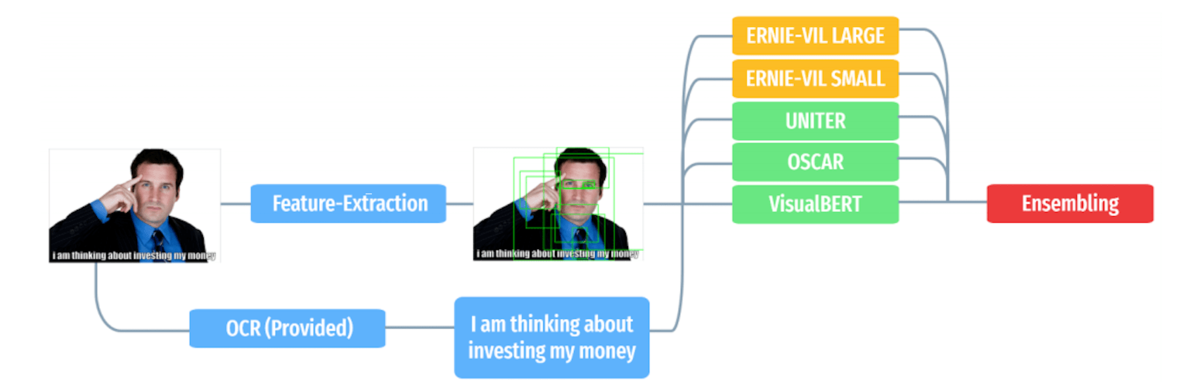
Schematic of Muennighoff's ensemble
Check out Muennighoff's full write-up and solution in the competition repo.
Riza Velioglu and Jewgeni Rose¶

|

|
Place: 3
Prize: $10,000
Hometown: Bursa, Turkey and Brunswick, Germany
Team HateDetectron
Usernames: riza.velioglu, jewgeni
Background:
Riza Velioglu: After receiving my bachelor’s degree in Electrical & Electronics Engineering from Istanbul Bilgi University in 2018, I directly started to my master’s degree in Intelligent Systems at Bielefeld University. Currently, writing the master’s thesis and planning to graduate in February 2021. At the same time, I have been the Teaching Assistant of the courses; Intro to Machine Learning, Intro to Neural Networks, and Intro to Computer Algorithms for the previous 1.5 years. In addition, I am actively looking for PhD opportunities in the areas of Vision and Language Representations, Multi-Modal Deep Learning, Self-Driving Cars (Semantic Segmentation, Lane Detection, Image Classification, Object Detection, etc.)
Jewgeni Rose: I completed my Master's degree in Computer Science at the University of Brunswick in 2017. After that, I started at the VW Group Innovation Center in Europe on the topic of digital assistants. At the same time, I began as a PhD student at the University of Bonn under the supervision of Prof. Dr. Jens Lehmann. My research area is Question Answering, specifically Context-aware Question Answering, whereby context is external knowledge (e.g. sensory data), chat history, or a user profile.
What motivated you to compete in this challenge?
I have a background on Image Processing and Natural Language Processing through university projects and as a personal interest. Therefore, Hateful Memes Challenge was a perfect chance for me to take part because it tries to leverage from joining the two modalities, that is multi-modality, which is perfect for someone working in both areas.
Moreover, I always try to do something that can have a direct impact in the real-world! With this challenge, it was possible to work on Hate Speech which we face in every day of our lives.
Summary of approach:
The approach could be summed up as follows:
- Growing training set by finding similar datasets on the web,
- Extracting image features using object detection algorithms (Detectron)
- Fine-tuning a pre-trained V+L model (VisualBERT)
- Hyper-parameter search and applying Majority Voting Technique
Growing training set. The more samples one has, the better score one will get! Therefore, we added more samples to the training data. We found out that there are 100 memes in dev_seen which are NOT in dev_unseen! First, we added those 100 memes to the training data.
Secondly, we searched for open-sourced datasets available on the web that is somewhat similar to Hateful Memes dataset. There was none because Hateful Memes was the first dataset on this regard. But we found the one called ‘Memotion Dataset’ which was planned to be one of the tasks at SemEval 2020, to be specific Task 8 ([Paper], [SemEval]). The dataset is open-sourced and can be downloaded [by this link].
In this dataset all 14k samples were annotated the class labels as Humorous, Sarcasm, Offensive, and Motivational and quantified the intensity to which a particular effect of a class is expressed. For instance, a meme can be annotated as: “Not Funny, Very Twisted, Hateful Offensive, Not Motivational”. We added all the “Hateful Offensive” and “Very Offensive” to the training data as hateful memes and added “Not Offensive” ones as non-hateful memes. We discarded the “Slight Offensive” memes because we thought it might confuse the model. With this training data the model did not achieve a better score. Later we found out that the memes are not labelled correctly (in our opinion). Therefore, we labelled the dataset manually! We searched for the memes that are somewhat similar to the ones in Hateful Memes challenge considering the idea of the challenge. After cherry-picking the “similar” memes, we ended up having 328 memes. Then, we added those 328 memes to the training set.
Extracting image features using object detection algorithms (Detectron). After collecting the whole dataset, we extracted our own image features using Facebook’s Detectron. To be specific we used Mask R-CNN and ResNet 152 as the backbone network architecture.
Fine-tuning a pre-trained V+L model (VisualBERT). After trying different models and different pre-trained VisualBERT models, we found out that the model which was pre-trained on the Masked Conceptual Captions gave the best score. The pre-trained model is provided by Facebook’s MMF and reachable via this link (pretrained key= visual_bert.pretrained.cc.full).
Hyper-parameter search and applying Majority Voting Technique. We then did a hyper-parameter search and ended up having multiple models having different ROC-AUC scores on “dev_unseen” dataset. We sorted them by the ROC score and took the first 27 models (27 is chosen arbitrarily). Then, predictions are collected from each of the models and the majority voting technique is applied: the ‘class’ of a data point is determined by the majority voted class. For instance, if 15 models predicted Class1 for a sample and 12 models predicted Class0, the sample is labelled as Class1 cause it’s the majority voted class. The ‘proba’ which stands for the probability that a sample belongs to a class is then determined as follows: if the majority class is 1, then the ‘proba’ is the maximum among all the 27 models else if the majority class is 0, then the ‘proba’ is the minimum among all the 27 models
We would argue that this technique works because it brings the “experts of the experts”! Imagine that one model is very good at -in other words it’s expert in- detecting hate speech towards Woman but might not be an expert in detecting hate speech towards Religion. Then we might have another expert which has the opposite case. By using the majority voting technique, we bring such experts together and benefit from them as a whole.
Check out HateDetectron's full write-up and solution in the competition repo.
Phillip Lippe, Nithin Holla, Shantanu Chandra, Santhosh Rajamanickam, Georgios Antoniou, Helen Yannakoudakis, Ekaterina Shutova¶

|

|

|

|

|

|

|
Place: 4th
Prize: $8,000
Hometowns: Amsterdam, The Netherlands; Glasgow, UK; London, UK
Team: kingsterdam
Usernames: GANTONIOU, sTranaeus, heleny, santhoshrajamanickam, katia, shaanc, phlippe, nholla
Background:
Ekaterina: I am an Assistant Professor at the Institute for Logic, Language and Computation (ILLC) at the University of Amsterdam, where I lead the Amsterdam Natural Language Understanding Lab. Previously, I was a Leverhulme Early Career Fellow at the University of Cambridge and a Research Scientist at the University of California, Berkeley. I received my PhD in Computer Science from the University of Cambridge. My research is in the area of natural language processing, with a specific focus on machine learning for natural language understanding tasks. My current interests include few-shot learning and meta-learning, joint modelling of language and vision, multilingual NLP and societal applications of NLP, such as hate speech and misinformation detection.
Helen: I am an Assistant Professor at King's College London and a Visiting Researcher at the University of Cambridge. Previously, I was an Affiliated Lecturer and a Senior Research Associate at the Department of Computer Science and Technology of the University of Cambridge, a Fellow and Director of Studies in Computer Science at Murray Edwards College, and a Newton Trust Teaching Fellow at Girton College, Cambridge. I hold a PhD in Natural Language and Information Processing from the University of Cambridge. Current research interests include transfer and multi-task learning, few-shot learning, continual learning, dialogue systems, and explainable machine learning, as well as machine learning for real-world applications and non-canonical forms of language.
George: I am currently working as part of a machine learning research team for a medical diagnosis start-up. Previously, I was a short-term Visiting Researcher at King’s College London working on multimodal approaches for hate speech detection. I hold a PhD in Pure Mathematics from the University of Glasgow and Master’s degree in Applied Mathematics from the University of Cambridge.
Nithin: I am a recent graduate from the MSc AI program at the University of Amsterdam. I worked on meta-learning for few-shot and continual learning in NLP as part of the master thesis.
Phillip: I'm a first-year PhD student at the University of Amsterdam working on temporal causality and deep learning. Before starting the PhD, I have completed a Master degree in Artificial Intelligence at the University of Amsterdam.
Santhosh: I am a Machine Learning Engineer (NLP) at Slimmer AI, and I am part of the team responsible for building and maintaining various AI products used by Springer Nature. I graduated from University of Amsterdam with a Masters degree in Artificial Intelligence in 2019 and my thesis was on joint modelling of emotion and abusive language detection.
Shantanu: I am currently working as an AI Research Scientist at ZS. Before this role, I did my Masters in Artificial Intelligence from University of Amsterdam. My masters thesis was on graph-based modeling of online communities for misinformation detection in collaboration with Facebook AI and King’s College London.
What motivated you to compete in this challenge?
We had never got a chance to work on a multi-modal problem and we saw this challenge as the perfect opportunity to get acquainted with the field and solve an important social problem in the process. Learning jointly from the two modalities poses its own unique set of challenges and this competition was a great learning experience. Also, the monetary reward for top 5 teams served as an incentive to be competitive and improve our solution to the best of our abilities.
Summary of approach:
The late-fusion baselines for the task were shown to underperform whereas the early fusion systems seemed promising. Thus, we experimented with two early-fusion pretrained models, namely UNITER, OSCAR as well as LXMERT. We found that UNITER performed the best, which could perhaps be attributed to its diverse set of pre-training tasks.
We observed that simple fine-tuning on the HatefuMemes dataset led to poor performance on text confounders in the training set whereas the model could overfit on the image confounders and non-confounders. Thus, we decided to upsample these text confounders to give additional weight to these examples. Additionally, we added more weight to the hateful examples to combat the class imbalance. Furthermore, we performed cross-validation style training for better generalizability of the model.
The final prediction was obtained as a weighted ensemble where the ensemble weights were optimized using an evolutionary algorithm (EA) on the development set predictions. We also observed that the dev_seen split had a higher percentage of truly multimodal examples than the training set. Thus, we included part of the dev_seen set into the cross-validation training. Specifically, for each fold, we split the dev_seen set in two halves, and used one part for training, and the other for testing. Thereby, we included text confounder pairs with different labels together to increase the confounder amount for training. This means that examples that make a confounder pair are not split between the train and test set. Finally, the predictions on the test parts were used for the EA optimization.
Check out kingsterdam's full write-up and solution in the competition repo.
Vlad Sandulescu¶

Place: 5th
Prize: $7,000
Hometowns: Copenhagen, Denmark
Usernames: burebista
Background:
Machine learning researcher working on digital marketing automation at Wunderman Nordic in Copenhagen. Previously worked on computational advertising models at Adform. Won the KDD Cup in 2016.
What motivated you to compete in this challenge?
I am doing some research on multimodal models and the competition provided a good opportunity to learn more about this through a practical task.
Summary of approach:
I adapted a couple of multimodal pretrained architectures and did simple ensembling to smooth out the predictions. I also tried LXMERT and VLP, because I wanted to see how the architectures and pre-training procedures impacted the finetuning for a downstream task.
Check out burebista's full write-up and solution in the competition repo.
Thanks to all the participants and to our winners! Special thanks to Facebook AI Research for enabling this important and exciting challenge and for providing the data to make it possible!



















