Image Similarity¶
The methods developed by the contestants are of high quality and set a new standard in research and for the industry in the field of image copy detection.
Matthijs Douze, Facebook AI Research Scientist and Image Similarity Challenge author
Back in June 2021, we launched the Facebook AI Image Similarity Challenge, an ambitious computer vision competition with two tracks and two phases designed to elicit useful approaches to the problem of image copy detection. In the months that followed, the DrivenData community delivered, and we're excited to now share the winning solutions!
Between June and October 2021, 1,236 participants from 80 countries signed up to solve the problems posed by the two tracks, and over 200 went on to submit solutions. For the Matching Track, participants were tasked with identifying which query images were derived from a large corpus of reference images. And for the Descriptor Track, participants were tasked with generating useful vector embeddings of the same query and reference images, such that related image pairs would receive high similarity scores.
One goal of the competition sponsors at Facebook AI was to create an opportunity for participants to explore self-supervised learning (SSL) techniques in solving copy detection. As you'll see in the details to follow, SSL was a key component across all of the winning solutions.
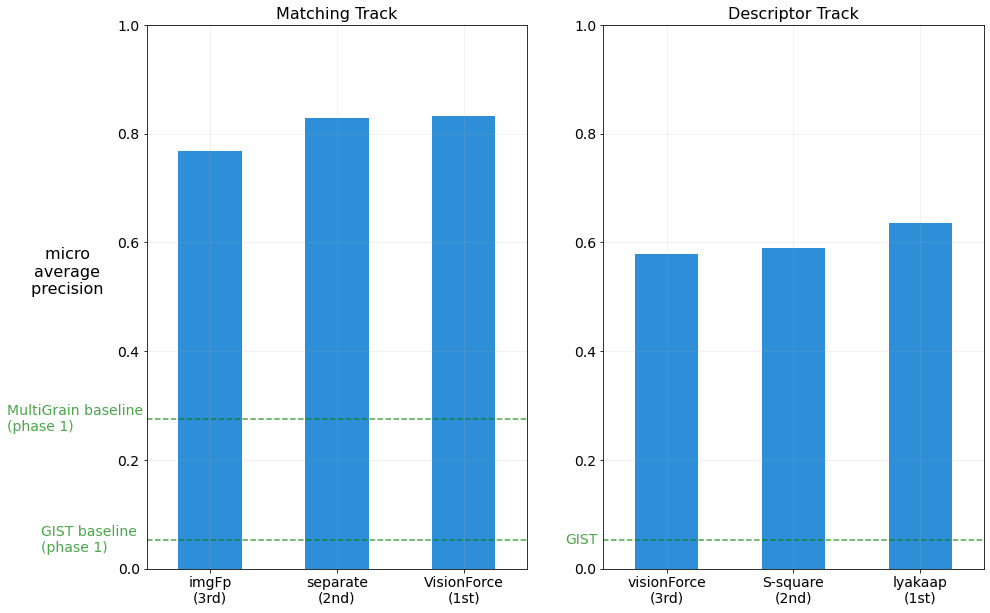
Ultimately, the winning solutions vastly outperformed the competition baseline methods, achieving micro average precision scores of 0.8329 and 0.6354 on the Matching and Descriptor tracks, respectively.
Winner Scores in Phase 2
Congratulations to the winners, runners-up, and all who participated! All prize-winning solutions have been released under an open source license for ongoing development and learning. We'll share details and common themes on the winning solutions below, but first, some background on the competition for those who are new to it.
Competition Background¶
The primary domain of this competition is a field of computer vision called copy detection.
Copy detection is a crucial component on all social media platforms today, used for such tasks as flagging misinformation and manipulative advertising, preventing uploads of graphic violence, and enforcing copyright protections. But when dealing with the billions of new images generated every day on sites like Facebook, manual content moderation just doesn't scale. We need algorithms to help automatically flag or remove bad content.
This competition allowed participants to test their skills in building a key part of that content moderating system, and in so doing contribute to making social media more trustworthy and safe for the people who use it. For more information, check out the competition paper and winners blog post from Facebook AI.
The Core Task¶
Participants had access to 3 archives of competition images.
- 1 million reference images
- 50K query images, a subset of which were derived from the reference images
- 1 million training images, statistically similar to but distinct from the reference archive
The core task in the Matching Track was to determine for each query image whether it originated from one of the reference images and assign a confidence score indicating its similarity to the candidate reference image. The end goal was similar for the Descriptor Track, but in this case participants submitted the image embeddings for all query and reference images, with a similarity search and submission score computed automatically on the competition platform.
For example, the top submissions were able to identify that the first query image below was derived from one of the reference images, while the second query image is a "distractor" with no source image in the reference set.
| "Reference Set" | "Query Set" | |
|

|
|

|

|
Identifying the image pair in the above example was relatively easy. Here are a few examples of more difficult image pairs from Phase 2 that were challenging even for the participants at the top of the leaderboard.
| Reference Image | Query Image | |

|

|
|

|

|
|

|

|
A limited set of ground truth pairs were provided, but we expected that these would be too few for a basic supervised learning approach. The training images were provided to facilitate self-supervised learning.
Common Themes in Winning Solutions¶
Winning solutions varied in their approaches, but some common themes were apparent.
- Self-supervision: All winning solutions took a self-supervised approach to learning (SSL), which is perhaps unsurprising given that many SSL techniques are in effect optimizing for a task like copy detection.
- Diverse image augmentations: Winning solutions used a battery of image augmentations, and many relied heavily on the new AugLy library from FB AI. In addition to the standard set of image augmentations (scaling, cropping, flipping, etc), winning solutions tended to use augmentations like screenshot, text and emoji overlays that are more prevalent in this competition's data set and social media.
- Varying image scales and augmentation intensities: Multiple winning solutions trained or extracted embeddings at several different image scales. Variation in image augmentation intensity, including some strong augmentations, was also a common theme in the top results, and some participants needed to figure out how to progressively add complexity to their model as training progressed.
- Local-global comparison: Most winning solutions compared partial and global views of both query and reference images. These approaches were designed to handle common cases such as query images being cropped from reference images, or reference images being overlayed on distractor images.
- Descriptor normalization: For the Descriptor track, all winning solutions used some form of post-processing to normalize the final embeddings relative to nearby training image descriptors. Participants reported significant score improvements with these transformations, for which they coined new terms like "descriptor stretching" and "escaping the sphere."
Meet the Winners¶
Matching Track Winners¶
Wenhao Wang, Yifan Sun, Weipu Zhang and Yi Yang¶

|

|

|

|
Prize rank: 1st
Prize: $50,000
Hometown: China
Team: VisionForce
Usernames: wenhaowang, zzzc18
Github repo: https://github.com/WangWenhao0716/ISC-Track1-Submission
Arxiv link: D2LV: A Data-Driven and Local-Verification Approach for Image Copy Detection
Background:
Wenhao Wang is a Research Intern in Baidu Research co-supervised by Yifan Sun and Yi Yang. His research interest is deep metric learning and computer vision. Prior to Baidu, he was a Remote Research Intern in Inception Institute of Artificial Intelligence from 2020 to 2021. He gained his bachelor’s degree in 2021, and will join in ReLER Lab to pursue a Ph.D. degree in the near future.
Yifan Sun is currently a Senior Expert at Baidu Research. His research interests focus on deep metric learning, long-tailed visual recognition, domain adaptation and generalization. He has publications on many top-tier conferences/journals such as CVPR, ICCV, ECCV, NIPS and TPAMI. His papers have received over 3000 citations and some of his researches have been applied into realistic AI business.
Weipu Zhang is an undergraduate student majoring in EECS as well as a research intern in Baidu Research. He had learned and practiced traditional algorithms and data structure for about 3 years. Currently he is interested in data science and machine learning, especially in computer vision and game agent.
Yi Yang is a Professor with the college of computer science and technology, Zhejiang University. He has authored over 200 papers in top-tier journals and conferences. His papers have received over 32,000 citations, with an H-index of 92. He has received more than 10 international awards in the field of artificial intelligence, such as the National Excellent Doctorate Dissertations, the Zhejiang Provincial Science Award First Prize, the Australian Research Council Discovery Early Career Research Award, the Australian Computer Society Gold Digital Disruptor Award, the Google Faculty Research Award and AWS Machine Learning Research Award.
What motivated you to compete in this challenge?
Our strong interest on deep metric learning motivated us to compete in this challenge. As a team, we have good experience with deep metric learning techniques such as face recognition and fine-grained image retrieval. We are delighted to contribute our solution for the objective of countering misinformation and copyright infringement, which is the keynote of ISC 2021. We believe ISC 2021 makes good social impact and is of great value to the deep learning research community.
Summary of approach:
Our approach has three advantages, i.e., using unsupervised pre-training, a strong but simple baseline of deep metric learning, and a robust local-global matching strategy.
- Unsupervised pretraining. We use unsupervised pretraining (on ImageNet) instead of the commonly-used supervised pretraining. We empirically find that BYOL (specifically, its M2T implementation) pre-training and Barlow-Twins pre-training are superior (than some other unsupervised pretraining methods) and a further ensemble of these two is even better.
- A strong but simple baseline of deep metric learning. We set up our baseline by combining both the classification loss and the pairwise loss (triplet, in particular). Many recent deep learning works already verify this combination as a good practice. Moreover, to make the sample pairs more informative, we employ a battery of image augmentations to generate sample pairs. We believe the diversity of augmentation promotes learning robust representation.
- A robust local-global matching strategy. We observe two hard cases: a) some queries are cropped from the reference and thus contains only partial patch of the reference image and b) some query images are generated by overlaying a reference image on top of a distractor image. In response, we use both heuristic and auto-detected bounding box to crop some local patches for matching. Ablation study shows that the proposed local-global matching strategy is critical to our solution.
SeungKee Jeon¶

Prize rank: 2nd
Prize: $30,000
Hometown: Seoul, South Korea
Username: separate
Github repo: https://github.com/seungkee/2nd-place-solution-to-Facebook-Image-Similarity-Matching-Track
Arxiv link: 2nd Place Solution to Facebook AI Image Similarity Challenge Matching Track
Background:
- Bachelor's degree in Computer Science at Sungkyunkwan University
- Kaggle Competition Grandmaster(https://www.kaggle.com/keetar)
- Deep Learning Engineer at Samsung Electronics(2017~)
What motivated you to compete in this challenge? The big prize pool was the biggest factor. And the problem was quite interesting.
Summary of approach
In the matching track, I concatenate query and reference image to form as one image and ask ViT to learn to predict from the image if query image used the reference image. In training, augmented train images are used as query images and original train images are used as reference images. Label is 1 if query image used reference image, and 0 if not . This approach enabled the ViT to learn relation between query and reference image directly. I think this approach is more effective with ViT than with CNN, because ViT can learn global-level relation using attention.
Xinlong Sun and Yangyang Qin¶

|

|
Prize rank: 3rd
Prize: $20,000
Hometown: Shenzhen, China
Team: imgFp
Usernames: joeqin, xinlongsun
Github repo: https://github.com/sun-xl/ISC2021
Arxiv link: 3rd Place: A Global and Local Dual Retrieval Solution to Facebook AI Image Similarity Challenge
Background:
We both currently work for Tencent in Shenzhen, China. Our recent research interests include image retrieval, video retrieval, etc.
What motivated you to compete in this challenge?
We mainly want to verify the effects of some new models in image retrieval, image copy detection. And the organizer provided very interesting and challenge datasets.
Summary of approach:
For the Matching Track task, we use a global+local recall method. The global recall model is EsViT, the same as task Descriptor Track. The local recall used SIFT point features (about 600 million features for reference images resize to 300p). And then compute match score of all recall pairs by SIFT feature + RANSCA and merge them (score add). As shown in the figure:
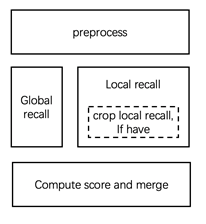
For image preprocess, we trained a pasted image detector as a preprocessing module to detect the overlay augment in query images. If a query image have detection result, the global branch will only use cropped part to extract feature, but the local branch will both use original and cropped image.
For global feature, we use a self-supervised pre-training Transformer EsViT as baseline first, which has better generalization performance in retrieval. And then follow the usual image retrieval method to conduct contrastive learning and training by constructing triples. For the construction of triples, we use augmented images to construct positive sample pairs, and different images are treated as negative sample pairs. And continue to finetune with a small learning-rate on the labeled data in Phase 1.
The most important thing is that we use SIFT local point feature to recall some extreme cases, such as overlay on a background with small part, which promoted our recall. (as shown in question 11)
Descriptor Track Winners¶
Shuhei Yokoo¶

Prize rank: 1st
Prize: $50,000
Hometown: Japan
Username: lyakaap
Github repo: https://github.com/lyakaap/fbisc
Arxiv link: Contrastive Learning with Large Memory Bank and Negative Embedding Subtraction for Accurate Copy Detection
Background:
- Working at DeNA as a data scientist.
- Kaggle Grandmaster.
- My interest area is Computer vision.
What motivated you to compete in this challenge?
I thought copy detection is related to image retrieval, which is one of my interest topics, so I decided to join this challenge.
Summary of approach:
- Pretrain model using train set provided by official to obtain robust descriptors.
- Train model by Contrastive loss accompanied with Cross Batch Memory.
- Use heavy data augmentation using AugLy (https://github.com/facebookresearch/AugLy)
- Fine-tune with query set and reference set.
- Use ground-truths as positive pairs, and irrelevant reference set images as negative pairs.*
- Enhance query and reference descriptors by subtracting their neighbor train descriptors, to make similar but different sample’s descriptors more separated, as a post-process step. This boosted my score a lot.
* Excluding use of negative reference samples results in a score of 0.6297.
Sergio Manuel Papadakis and Sanjay Addicam¶

|

|
Prize rank: 2rd
Prize: $30,000
Hometown: San Carlos de Bariloche, Argentina and Chandler, Arizona USA
Team: S-square
Github repo: https://github.com/socom20/facebook-image-similarity-challenge-2021
Arxiv link: Producing augmentation-invariant embeddings from real-life imagery
Background:
Sergio: I studied the career of Nuclear Engineer. My curious personality led me to be interested in the field of Artificial Intelligence. Starting in 2015, I began to study Artificial Intelligence in a self-taught way. In 2019 I decided to formalize what I learned by obtaining a master’s degree in Artificial Intelligence. Since the end of 2020 I decided to participate in computer vision competitions. Currently I have won several competitions at Kaggle where I hold the title of Competitions Master, best rank of 39 worldwide.
Sanjay: I am a Sr. Principal Engineer and CTO of an Intel group focused on Retail, Banking, Hospitality and education. I am focused on Deploying Autonomous Deep learning solutions on the edge and accomplish training on the edge. I am a Kaggle competition master with a best rank of 23.
What motivated you to compete in this challenge?
Sergio: I like challenges and I believe that the best way to learn a new subject is by solving difficult problems in the field of interest. For this reason, I tend to be attracted to Artificial Intelligence Competitions. To win an AI competition, I must spend a lot of time. Before entering a competition, I must check if it is based on a subject in which I have a lot of interest, if I can learn new tools and more importantly, if I can bring something new to the field. In this case, from my point of view, Facebook's competition fulfilled all my requirements.
Sanjay: It was similar to the Google landscape challenge in Kaggle. I always found it interesting. The huge class imbalance problems are very representative of real-world problems and interest me.
Summary of approach:
At a high level, the problem as we saw, was class imbalance (50k query images vs. 1M reference images). It was immediately evident for us that we needed to reproduce the augmentations used in the query dataset to increase the training samples. For this purpose, we used Augly and created some new augmentations to build synthetic query images.
Next, we summarize some important details:
- We used an ArcFace head and different backbones: EffNet, EffNetV2, NfNet.
- Each class in the ArcFace head corresponds to a different augmented training image. We also vary the number of classes of each model.
- We used different tricks to increase the training speed:
- As the training progressed, we increased the augmentation intensity.
- We gradually increase input resolution as training progressed.
- Drip Training procedure: The idea was to iteratively increase the number of classes the model is trained with. At the beginning of each iteration, the backbone is used to build a new centroids matrix of the ArcFace head.
- All the models were ensembled using PCA to produce 256-dims embeddings. All query and reference embeddings were L2-normalized.
- Query samples normalization: Sergio realized that the competition’s distance is measured using Euclidean distances between samples and given the fact that the output of the ensemble was L2-normalized we had one additional degree of freedom to exploit. We leverage this opportunity to normalize the query embeddings using the training dataset. We could improve our Phase 2 mAP score from 0,53 (without normalization) to 0,59.
Wenhao Wang, Yifan Sun, Weipu Zhang and Yi Yang¶
|
|
|
|
|
Prize rank: 3rd
Prize: $20,000
Hometown: China
Team: visionForce
Usernames: wenhaowang, zzzc18
Github repo: https://github.com/WangWenhao0716/ISC-Track2-Submission
Arxiv link: Bag of Tricks and A Strong baseline for Image Copy Detection
Background:
Wenhao Wang is a Research Intern in Baidu Research co-supervised by Yifan Sun and Yi Yang. His research interest is deep metric learning and computer vision. Prior to Baidu, he was a Remote Research Intern in Inception Institute of Artificial Intelligence from 2020 to 2021. He gained his bachelor’s degree in 2021, and will join in ReLER Lab to pursue a Ph.D. degree in the near future.
Yifan Sun is currently a Senior Expert at Baidu Research. His research interests focus on deep metric learning, long-tailed visual recognition, domain adaptation and generalization. He has publications on many top-tier conferences/journals such as CVPR, ICCV, ECCV, NIPS and TPAMI. His papers have received over 3000 citations and some of his researches have been applied into realistic AI business.
Weipu Zhang is an undergraduate student majoring in EECS as well as a research intern in Baidu Research. He had learned and practiced traditional algorithms and data structure for about 3 years. Currently he is interested in data science and machine learning, especially in computer vision and game agent.
Yi Yang is a Professor with the college of computer science and technology, Zhejiang University. He has authored over 200 papers in top-tier journals and conferences. His papers have received over 32,000 citations, with an H-index of 92. He has received more than 10 international awards in the field of artificial intelligence, such as the National Excellent Doctorate Dissertations, the Zhejiang Provincial Science Award First Prize, the Australian Research Council Discovery Early Career Research Award, the Australian Computer Society Gold Digital Disruptor Award, the Google Faculty Research Award and AWS Machine Learning Research Award.
What motivated you to compete in this challenge?
Our strong interest on deep metric learning motivated us to compete in this challenge. As a team, we have good experience with deep metric learning techniques such as face recognition and fine-grained image retrieval. We are delighted to contribute our solution for the objective of countering misinformation and copyright infringement, which is the keynote of ISC 2021. We believe ISC 2021 makes good social impact and is of great value to the deep learning research community.
Summary of approach:
Our approach has three advantages, i.e., using unsupervised pre-training, a strong but simple baseline of deep metric learning, and a descriptor stretching strategy.
- Unsupervised pretraining. We use unsupervised pretraining (on ImageNet) instead of the commonly-used supervised pretraining. We empirically find that Barlow-Twins pre-training is superior (than some other unsupervised pretraining methods).
- A strong but simple baseline of deep metric learning. We set up our baseline by combining both the classification loss and the pairwise loss (triplet, in particular). Many recent deep learning works already verify this combination as a good practice. Moreover, to make the sample pairs informative, we employ some image augmentations to generate sample pairs. We believe the diversity of augmentation promotes learning robust representation.
- A descriptor stretching strategy. We note that the Track2 setting directly uses the Euclidean distance as the final matching score and thus prohibits the score normalization operation in Track1. In response to this characteristic, we propose a novel descriptor stretching strategy. It rescales (stretches) the descriptors to stabilize the scores of different queries. In another word, it approximates the score normalization effect by directly stretching the descriptors. Empirically, we find this stretching strategy significantly improves the retrieval accuracy.
Honorable Mention: Dongqi Tang, Ruoyu Li, Jianshu Li, Jian Liu¶

|

|

|

|
Rank: The TitanShield2 team was unable to share their solution under an open source license and is therefore not eligible for a cash prize, but their solution topped the Descriptor Track leaderboard at 0.7418.
Hometown: China, Singapore
Team: titanshield2
Usernames: rex_, coura, badpoem, LJSUP
Background:
All the members of our team are from ZOLOZ. ZOLOZ provides global identity verification software, and is the brand for the Ant Group's many security capabilities created while developing and operating the Alipay super-app. We are computer vision engineers under ZOLOZ, engaged in developing algorithms for eKYC, eKYB and content security.
What motivated you to compete in this challenge?
Since this competition is quite similar to our work scenario, we joined the competition and hope to explore the frontier of the field of image retrieval.
Summary of approach:
Basically, we explored some well-established methods in the literature, and combined features of multiple models, using a variety of backbones and training with varieties of metric headers.
To make query image features comparable, we apply feature compatible technique to let different models output the same feature for each reference image. As we believe features ensembled with multiple models will be more powerful than single one.
For the training process, we adopt a multi-task self-supervised learning framework, which has 3 branches for training, one is for self-distillation, one is for image restoration and another is for feature compatibility, to train the representation models. In this way, we are able to build much stronger representation backbones.
Thanks to all the participants and to our winners! Special thanks to Facebook AI Research for enabling this important and exciting challenge and for providing the data to make it possible!



















