Open Cities AI Challenge: Segmenting Buildings for Disaster Resilience¶
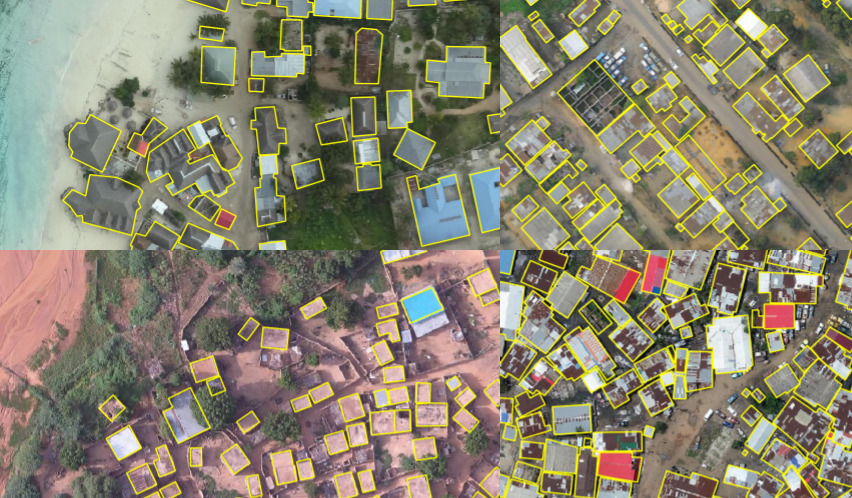
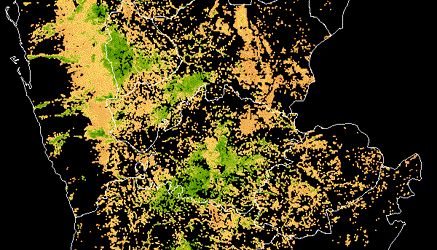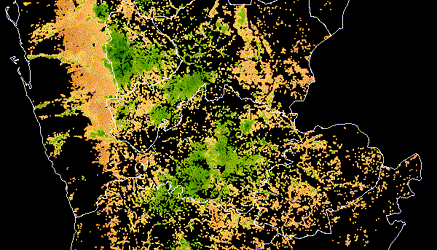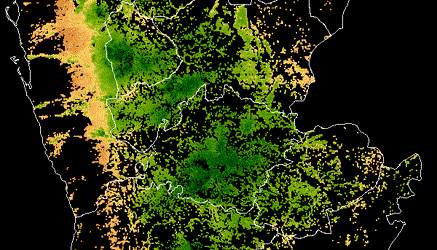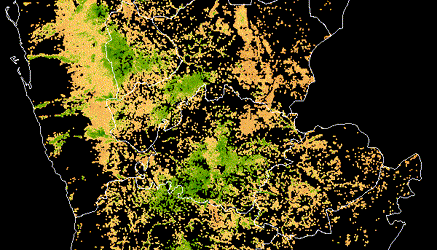
Sample of hand-labeled building footprints overlaid on drone imagery for four African urban areas included in the challenge dataset.
As urban populations grow, more people are exposed to the benefits and hazards of city life. One challenge for cities is managing the risk of disasters in a dynamic built environment. Buildings, roads, and other critical infrastructure need to be mapped frequently, accurately, and in enough detail to represent assets important to every community. Knowing where assets are vulnerable to damage or disruption by natural hazards is key to disaster risk management (DRM).
The goal of the Open Cities AI Challenge was to accelerate the development of more accurate, representative, and usable open-source ML models for disaster risk management in African cities, starting by mapping where buildings are present. To power these models, participants were provided with high-resolution drone imagery from 12 African cities and regions covering more than 700,000 buildings. This imagery was paired with digital building footprints annotated with the help of local OpenStreetMap communities.
But the challenge didn't stop there. While the potential benefits from bringing large-scale data and computer vision to DRM are significant, there is an urgent need to develop a better understanding of the potential for negative or unintended consequences. This competition also featured a novel submission track where participants had the opportunity to engage with the ethical implications of machine learning in DRM. Participants were provided with information about the ML pipeline surrounding the competition — from data collection, annotation, and management through model development, evaluation, and downstream applications — and challenged to provide perspectives on the responsible uses of AI in their work. Submitting to this track was required for prize eligibility of all participants.
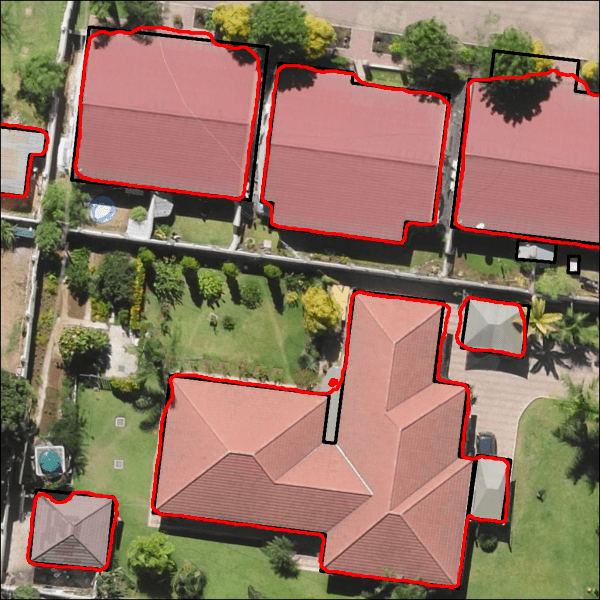
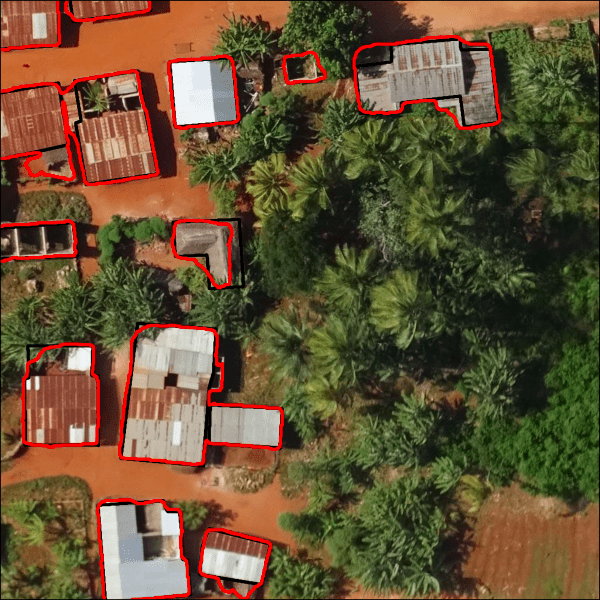
In the end, we saw more than 2,000 submissions generated during this challenge, with the top model achieving an impressive 0.8598 Jaccard score on the private test set! That translated to segmenting buildings with 92% precision (intersection over predictions) and 93% recall (intersection over ground truth)! See below for a couple examples of what that looks like in action.
|
|
Sample outputs reflecting predictions from the winning segementation model (red) compared with ground truth labels (black). Left image from Lusaka, Zambia (chip Jaccard score = 0.93), right image from Zanzibar, Tanzania (chip Jaccard score = 0.88).
This represents a dramatic improvement over what relatively low-effort models would have produced before the challenge (from the Raster-vision benchmark, 0.5915 Jaccard score; and an adapted winning model from a previous Open AI Tanzania Challenge, 0.6235 Jaccard score). What's more, the challenge datasets had enough diversity in locations and sensors to make the winning classifier useful for a range of urban mapping projects in Africa.
All the prize-winning solutions are made available under an open source license for anyone to use and learn from. Meet the winners below and check out their approaches to help cities manage disaster risk!
Meet the winners: Semantic Segmentation Track¶
Pavel Iakubovskii¶

Place: 1st
Prize: $6,000
Hometown: Chebarkul, Russia
Username: qubvel
Background:
My name is Pavel Iakubovskii. I am a researcher at Skoltech (Skolkovo Institute of Science and Technology) and computer vision engineer at GeoAlert. I am professionally working with geospatial data processing using machine learning techniques (especially convolutional neural networks). I am also a github active user with popular open-source projects for image segmentation https://github.com/qubvel and a Kaggle Master.
What motivated you to participate?:
As I am working closely with similar data it was interesting to compare my personal professional skills with other participants.
Summary of approach:
For this challenge I have implemented a 3 stage pipeline for aerial imagery segmentation.
- First stage ensemble of UNet models trained on noisy labels (tier 1) with hard image augmentations.
- Next two stages models trained on noisy train data (tier 1) and automatically labeled by stage 1 models test data (pseudo labels). This allowed significantly improved generalization of model for test data.
Image augmentation is well known technique in computer vision to enlarge your data synthetically. It helps the model not to overfit, each epoch you pass the same image in network, but you modify it with different transforms (brightness, scale, rotation, etc.). Strong augmentations helped a lot for model generalization and improved leaderboard score.
I have also assembled test images to big scenes instead of predicting each image separately. It is not always enough context for the model to decide whether pixels belong to a building or not if the model “sees” only a small corner of a building on the border of an image. So mosaic allowed avoiding errors near borders. I have also implemented “Predicto” which allows sequentially read-predict-write patches of data. The algorithm is as follows:
- read window with shape 1024x1024
- pass through network and get mask with shape 1024 x 1024
- cut 128 pixel from each edge where errors are more likely to appear due to lack of context
- write result to open file
- read next window and so on (windows read with overlap to avoid missing data after edge cutting)
This scheme also allows processing large tiff file without loading them completely to RAM.
Check out qubvel's full write-up and solution in the competition repo.
Kirill Brodt¶

Place: 2nd
Prize: $4,000
Hometown: Almaty, Kazakhstan
Username: kbrodt
Background:
Currently I'm doing research at the University of Montréal in Computer Graphics, using Machine Learning for problem solving, namely animating 3D characters into depicted pose from sketches. I got my Master's in Mathematics at the Novosibirsk State University, Russia.
Lately, I fell in love with machine learning, so I was enrolled in Yandex School of Data Analysis and Computer Science Center created by JetBrains. This led me to develop and teach the first open deep learning course in Russian. Machine Learning is my passion and I often take part in competitions. I think Deep Learning eats the world.
What motivated you to participate?:
If I can share my knowledge with someone, I do it with pleasure. Secondly, I’ve never worked with geospatial data and technologies before, that’s why this competition is a great opportunity to check my own skills and at the same time to get new knowledge from this field. You can also win some prize as a bonus :)
Summary of approach:
You can get good results by training UNet-like models with heavy encoders using only tier 1 data and some tricks. The main idea is to take into account the rare tiles. One way is to assign some class to the tile and use the inverse probability of that class in the dataset to oversample them. It significantly speeds up the learning process. The other trick is to change binary cross-entropy loss to multiclass cross-entropy (in our case 2 output channels) and take argmax instead of searching an optimal threshold. It is also preferred to train the model in the same conditions as at inference, i.e. at inference we have 1024x1024 tiles, so we need maximally to preserve this resolution during training. After obtaining a strong single model, train 5 more models and ensemble them by simple averaging.
Check out kbrodt's full write-up and solution in the competition repo.
Michal Busta¶
![]()
Place: 3rd
Prize: $2,000
Hometown: Prague, Czech Republic
Username: MichalBusta
Background:
I’m a software engineer.
What motivated you to participate?:
I’m using competitions mainly to test interesting papers (not everything is working out of the box…) and improve workflows. The competition has a nice goal, so a perfect playground.
Summary of approach:
Straight-forward approach: end-to-end segmentation with fully convolutional neural network:
Step 1:
- Net architecture: FPN with efficient-net(b1) back-bone (chosen because my machine for experiments is old-school box with GeForce GTX 1060)
- Identify hyper-parameters (weight decay, learning rate)
- Train (one-cycle learning policy, optimizers: AdamW/Over9000, losses: Focal Loss, Dice Loss (in separate heads = train only once, see what work best, try to use all outputs in final ensemble))
- The network has additional 2 heads – direct classification head (is there a building or not – later to be used for negative examples mining) and scale regression head (the samples in dataset are in different scales, so this was a attempt to make things easier/better performing in inference)
- Datasets: tier-1, and some data from SpaceNet dataset (5 fold)
Step 2: Try “Self-training with Noisy Student” and negative mining
- Label test data and data from tier2 (soft labels) with model from step 1 (with TTA)
- Mine negative samples
- Repeat training with efficient-net(b2) back-bone, for soft labels, the KL divergence loss was used.
Notes: The results on validation set and public leaderboard improved against the baseline (cca 1.5 on Jaccard index), but there is no clear evidence that it is not just by using “stronger backbone” (classical mistake – try too many things in one step). I would not use these steps in other than “competition” mode (specially the negative mining can be the problematic point - I’ll share with the code some (perhaps useful) additional charts from the validation phase).
Step 3: Standard “competition madness”
- Average ensemble of models (from steps 1,2) with TTA augumentation (scale, flipping)
Check out MichalBusta’s full write-up and solution in the competition repo.
Meet the winners: Responsible AI Track¶
Catherine Inness¶

Place: Prize 1
Prize: $1,000
Hometown: London, UK
Username: Catherine_I
Background:
I’m eight months into my year-long study for an MSc in Data Science and Machine Learning at UCL, London. Before that, I spent 10 years working for Accenture, implementing complex and business-critical technology.
What motivated you to participate?:
This was my first data science competition. The ethics of machine learning is an interest of mine, and the responsible AI track was a great opportunity to explore applications in disaster risk management.
Submission: Fairness in Machine Learning: How Can a Model Trained on Aerial Imagery Contain Bias?
Machine learning algorithms are optimised to minimise their prediction error, by discovering and exploiting patterns in data.
So far, so good. But in the pure pursuit of prediction accuracy, it's been shown that not everyone is being treated equally (for just one example, see the now well-known ProPublica investigation into the use of algorithms in the United States to rate a defendant’s risk of committing a future crime).
It's commonly said that algorithms learn the inherent bias in the data that they are trained on: 'bias in, bias out'. It's clear how this could work for case studies such as loan acceptance or fraud detection, where models are often trained on individual personal data, past outcomes or decision-making records from previous cases. But in the case of machine learning on aerial imagery for mapping, we're ultimately just working with pixels. How can a model learn a prejudice purely from pixels? (More)
You can also check out Catherine_I’s full write-up and submission in the competition repo.
Chris Arderne¶

Place: Prize 2
Prize: $1,000
Hometown: Cape Town, South Africa
Username: chrisjames
Background:
Originally from South Africa, I’ve been lucky to enough over the last six years to live in Sweden, the US, and now Spain. I love working with data, especially when latitude and longitude are involved, and get a kick when I can apply this to my personal interests (mountains, oceans) and my profession (energy, climate). I consult for international donors like the World Bank, and more recently have started working with smaller startups and research groups using remote sensing to tackle interesting problems.
What motivated you to participate?:
I’d been looking for a good excuse to get to grips with neural networks, but in my day job traditional machine learning and data analysis are normally enough. So I jumped at the chance to work on something relevant to my work, with well-defined inputs and outputs. Cloud instances get expensive quickly, so I only trained and predicted three times. But I’d learned enough for my purposes, so decided I could share my thoughts for the Responsible AI part of the competition.
Submission: Stop pretending technology is value neutral
About six years ago, I was arguing with a wiser friend in a bar in Ghent. I was adamant that science and technology were neutral creations: what mattered was what people did with them. As an engineer, I could wash my hands of those problems. She knew better: you can’t design cigarettes and pretend you don’t know what cigarettes are for.
This is especially true in artificial intelligence and machine learning in particular: they are very easily applied to morally questionable practises, and due to their inscrutability, are very easily misused, even by practitioners with good intentions. (More)
You can also check out chrisjames’s full write-up and submission in the competition repo.
Thomas Kavanagh and Alex Weston¶

|

|
Place: Prize 3
Prize: $1,000
Hometown: Brooklyn, USA
Username: thomkav and alweston
Background:
Thomas Kavanagh shares DrivenData’s hometown of Denver, CO, but now lives in Brooklyn, NY. He spent the first part of his professional career designing interactive media systems for live performance, which led him to rediscover a love of programming. He graduated from Duke University with a major in mathematics. Thomas is currently a data scientist at Alkymi. Alkymi Data Inbox is the first ever Data Inbox for enterprises that breaks the unstructured data logjam by automatically freeing data from email and documents to drive real time decisions and action. His favorite quarantine coping strategies include attending virtual dance parties, teaching yoga, and cold-calling his entire contact list.
Alex Weston is a Brooklyn-based data scientist. After studying Mathematics at Vassar College, he spent the next six years working at a non-profit arthouse cinema in the greater Philadelphia area. The recent explosion in deep learning research inspired him to move to New York and study data science. He is currently a teaching assistant at Metis, a 12-week immersive data science program, where he and Thomas met.
What motivated you to participate?:
THOMAS: I wanted a means to develop my data skills, especially in computer vision, while also contributing to a great cause. DrivenData’s competitions are the perfect place to do that. The stated humanitarian objectives behind the development of this algorithm were clear, and I could imagine how our contribution would serve an immediate need.
ALEX: My top priorities as I begin my data science career are 1) to learn and apply cutting-edge data science technologies, and 2) to use those technologies for the benefit of humanity. This challenge was a slam dunk for both, especially since I was looking to learn more about computer vision.
Our collaboration was very serendipitous. One day, we happened to be taking the same subway back home, and discovered we had both found interest in the Open Cities AI challenge. We worked together mainly in the month of February.
Submission: Contributed Geographic Information: Gray Zones in Collection and Usage
Models that build into their pipeline a requirement for high fidelity data in turn creates plausible justification for further collection of this data. As graphics processors become cheaper to run at scale, there is no longer a computational barrier to the storage and processing of high fidelity data. So researchers and archivists must develop models with explicit objectives to minimize reliance on more intrusive data collection practices. (More)
You can also check out thomkav and alweston’s full write-up and submission in the competition repo.
Thanks to all the participants and to our winners! Special thanks to the Global Facility for Disaster Reduction and Recovery (GFDRR) for enabling this fascinating challenge and assembling the data to make it possible, and to the Azavea team for their expert preparation of the challenge datasets!