

The challenge¶
Finding more efficient and accurate ways to extract insights from unstructured medical data helps public health researchers better understand the circumstances behind older adult falls. This helps drive communication, policy, and further research initiatives to reduce morbidity and mortality.
Royal Law, Data Science Team Lead, CDC's National Center for Injury Prevention and Control
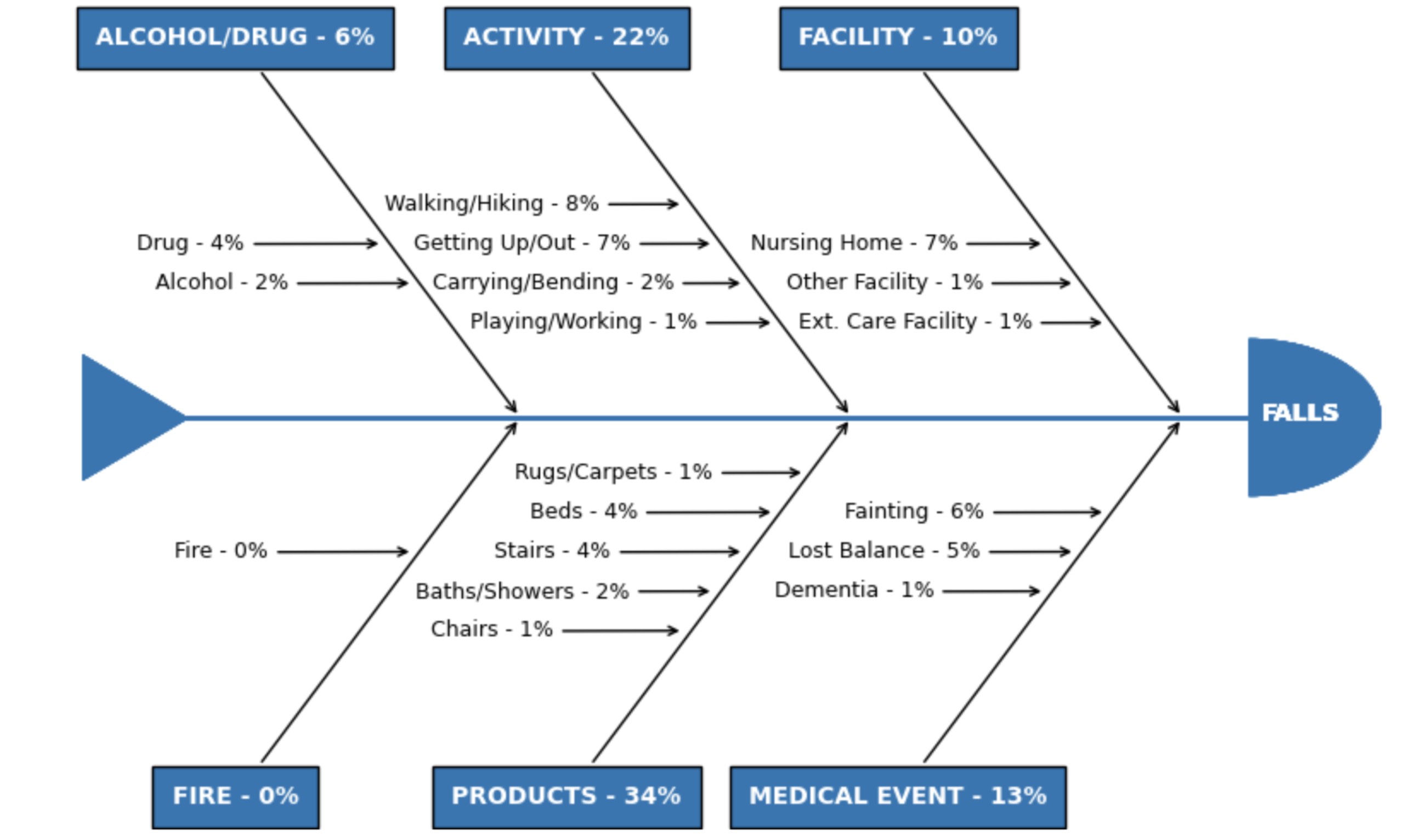
Falls are the leading cause of injury-related deaths among adults 65 and older. Fall risk can be mitigated through treatment of vision problems, exercise for strength and balance, removal of tripping hazards, and other interventions that appropriately target common fall causes.
In the Unsupervised Wisdom Challenge, participants were tasked with identifying novel, effective methods of using unsupervised machine learning to extract insights about older adult falls from narrative medical record data. The challenge was sponsored by the Centers for Disease Control and Prevention's National Center for Injury Prevention and Control (CDC/NCIPC) and used data that typically requires time-intensive manual coding procedures to get insights from: emergency department narratives in the National Electronic Injury Surveillance System (NEISS). Efficient methods of understanding how, when, and why older adults fall using emergency department narratives can potentially inform interventions that reduce fall risk.
Setup of an unsupervised machine learning challenge¶
Since this was an unsupervised machine learning problem, it was set up differently than our typical prediction-focused challenges.
Solution format. In this challenge, solvers submitted an analysis notebook (in R or Python) and a 1-3 page executive summary that highlighted their key findings, summarized their approach, and included selected visualizations from their analyses.
Guiding questions. To help solvers engage with such an open-ended problem, the competition website included guiding questions and examples of analyses that would and would not be a good fit for the competition.
Mid-point review and challenge Q&A event. This challenge included two optional milestones to help solvers understand the challenge goals and learn how well their solution aligned with those goals, an opportunity to get feedback via a mid-point review and a Q&A event.
Overall and bonus prize structure. In this challenge, solvers competed for overall prizes as well as six types of bonus prizes that emphasized particular challenge priorities. For overall prizes, solutions were evaluated against the weighted criteria of novelty (35%), communication (25%), rigor (20%), and insight (20%).
All submissions were also considered for the following bonus prizes:
- Most novel approach
- Most compelling insight
- Best visualization
- Best null result
- Most helpful shared code
- Most promising mid-point submissions (three awarded)
Results¶
The goal in this challenge was to apply unsupervised machine learning to medical record narratives in a way that was novel, well-communicated, rigorous, and yielded insights about older adult falls. Solvers submitted a wide range of methodologies to this end, including using open-source and third party LLMs (GPT, LLaMA), clustering (DBSCAN, K-Means), dimensionality reduction (PCA), topic modeling (LDA, BERT), sentence transformers, semantic search, named entity recognition, and more. LLMs were most frequently used to extract information from narratives, with many participants prompting LLMs to answer specific questions and using the answers to create variables that could be used in downstream analysis, such as clustering or statistical models.
Among prize-winning solutions, there was a lot of diversity of both approaches and participants, with winners coming from over 8 countries across 5 continents.
The four solutions that won overall prizes each used different approaches and tools, including ChatGPT, Text2Text Generation, FAISS (Facebook AI Similarity Search), and DBSCAN clustering. However, it wasn't the use of sophisticated tools alone that made for strong submissions. Rather, it was how solvers applied and combined tools to derive insights from the narrative text that most impressed the judges.
There was no one common methodological pattern among the top solutions. For example, some solvers used the provided OpenAI embeddings and others did not; some used Community Code while others were the ones to provide it; most winners used Python, but one used R.
Many overall prize winners took home bonus prizes, but additional bonus prize winners brought yet more creative strategies and strengths to their submissions, like strong visualizations, an in-depth exploration of an approach that did not work out, and a novel approach that combined K-Means clustering, PCA dimensionality reduction, LLaMA 2, GPT 3.5, and DistilBERT.
All the prize-winning solutions from this competition are linked below and made available for anyone to use and learn from.
Meet the winners¶
Let's meet the winners and hear about how they approached the challenge!
| Ranked prize | Team | Bonus prize | ||
|---|---|---|---|---|
| 1st | artvolgin | Most compelling insight, Most promising mid-point submission | ||
| 2nd | zysymu | Most helpful shared code | ||
| 3rd | saket | Most promising mid-point submission | ||
| 4th | xvii | |||
| - | RyoyaKatafuchi | Most promising mid-point submission | ||
| - | jimking100 | Best visualization | ||
| - | Research4Good | Best null result | ||
| - | SeaHawk | Most novel approach |
artvolgin¶


Overall rank: 1st
Bonus prize: Most compelling insight and most promising mid-point submission
Prize earned: $25,000
Team members: Artem Volgin, Ekaterina Melianova
Usernames: artvolgin
Hometown: Manchester, UK
Social handle or URL: @artvolgin and @egmelianova
Background: Artem Volgin is currently a PhD candidate in Social Statistics at the University of Manchester, UK. His main research interests revolve around applications of Network Analysis and Natural Language Processing methods. Artem has versatile experience in working with real-life data from different domains and was involved in several data science projects at the World Bank and the University of Oxford. He actively participates in data science competitions, consistently achieving top places.
Ekaterina Melianova is currently a PhD candidate in Advanced Quantitative Methods at the University of Bristol, UK. She focuses on applying innovative statistical techniques to tackle real-world social issues, with a particular emphasis on social epidemiology and education. She has contributed to projects at the World Bank and various market research organizations. Ekaterina actively participates in data analytics competitions, continuously seeking opportunities to apply her skills in novel substantive and methodological domains.
What motivated you to participate?:
There were many factors in play: the desire to try the latest developments in Large Language Models in practice, the flexibility of the challenge format allowing us to experiment with ChatGPT-based solutions beyond prediction tasks, an interesting dataset with a lot of hidden value to unpack, and an opportunity to contribute to a socially impactful task.
Summary of approach:
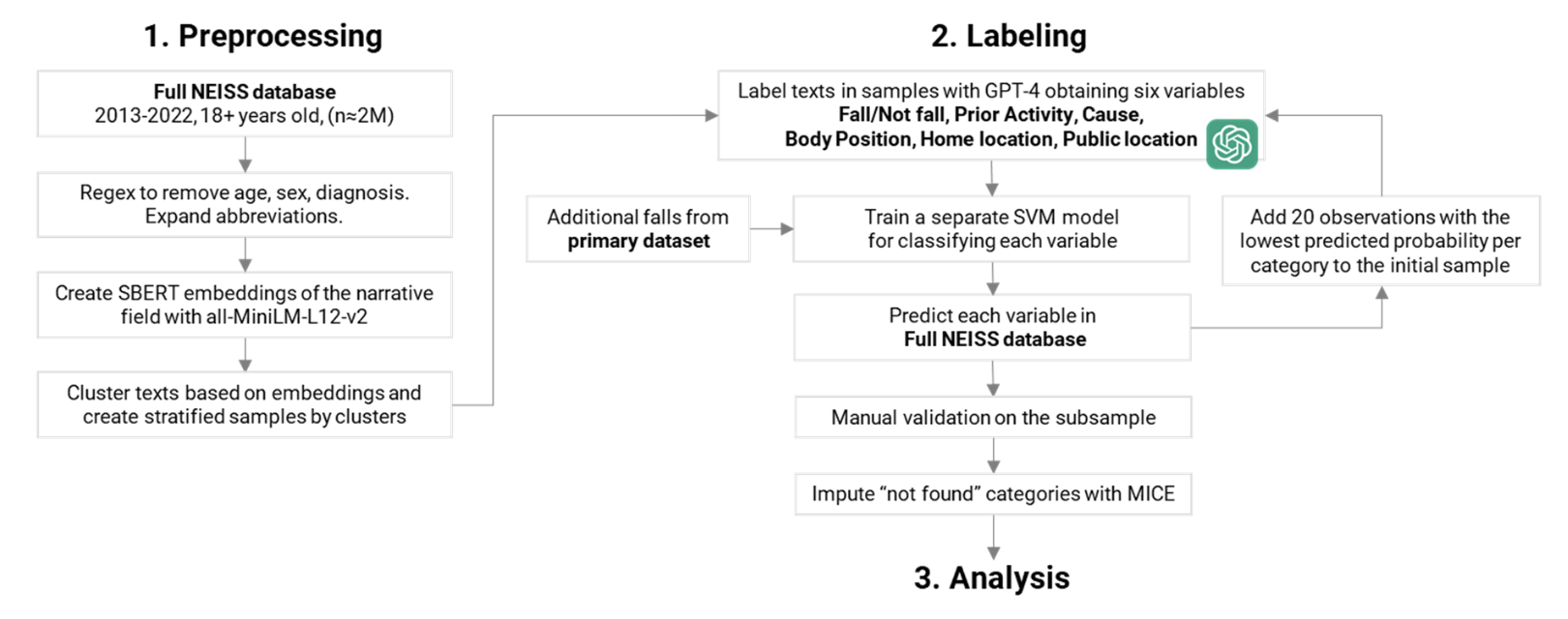
Using a downsampling method with ChatGPT and ML techniques, we obtained a full NEISS dataset across all accidents and age groups from 2013-2022 with six new variables: fall/not fall, prior activity, cause, body position, home location, and facility. We showed how these new indicators vary by age and sex for the fall-related cases and how they impact the likelihood of falls and post-fall hospitalization of older people. We also revealed seasonal and yearly trends in falls and provided a comparative age-based perspective, underscoring the value of the full ED narratives dataset in studying falls of older adults.
Check out artvolgin's full write-up and solution in the competition repo.
zysymu¶

Overall rank: 2nd
Bonus prize: Most helpful shared code
Prize earned: $17,500
Team members: Marcos Tidball
Usernames: zysymu
Hometown: Santa Cruz do Sul, Rio Grande do Sul, Brazil
Social handle or URL: /in/zysymu/
Background:
I am currently a 1st year master's student at the University of Padova, having previously worked as a Data Scientist at BTG Pactual.
What motivated you to participate?:
My strong interest in learning more about LLMs and how they can be used in conjunction with tabular data motivated me to compete in this challenge. Having no previous applied experience with LLMs I used this project as a way to learn more about how these models can be applied to real-world scenarios. Also knowing older adults that have experienced serious falls motivated me more to contribute to this competition in order to potentially reduce the occurrence of falls.
Summary of approach:
The main idea of my approach is to develop an information extraction pipeline to aid in obtaining more specific details about what happened in the fall events. Inspired by TabLLM I created a custom prompt in a human-readable format for each data point, combining information contained in tabular variables and event narratives (which are "translated" so that technical terms are easier to understand). Six questions, each related to a different characteristic of the fall (cause, diagnosis, etc.), are appended to the prompts and fed to a Text2Text Generation LLM that extracts information by answering the questions. Finally, I train one LDA model for each kind of question to model the topics of the answers, creating a granular way of analyzing and recovering falls given their different characteristics.
Check out zysymu's full write-up and solution in the competition repo.
saket¶

Overall rank: 3rd
Bonus prize: Most promising mid-point submission
Prize earned: $12,500
Team members: Saket Kunwar
Usernames: saket
Hometown: Kathmandu, Nepal
Social handle or URL: /in/saketkunwar
Background:
I am a computer-vision/remote-sensing and data-science freelance researcher from Nepal. Amongst other ML competitions, I have been in a prize-winning position for NASA SOHO comet search, NOAA Precipitation Prediction (Rodeo 2), the Spacenet-8 flood detection, and 2019 IEEE GRSS data fusion contest. When I am not trying to keep up with the rapidly evolving and fast-paced AI field or optimizing algorithms I find myself optimizing my performance in trail running or diving.
What motivated you to participate?:
I enjoy participating in machine learning/data-science challenges and have been doing it for a while. This particular competition gave me the opportunity to use/evaluate recent trends/SOTA in Large Language models, semantic search, knowledge graphs, and vector databases, which was different from my computer-vision background. After exploring the data, specifically extracting insights from the narrative, I became quite intrigued and so went ahead iteratively developing my workflow. I also appreciated the open evaluation nature of this competition and the freedom it gave to come up with creative solutions.
Summary of approach:
We leveraged the ‘OpenAI’s text-embedding-ada-002’ embeddings provided by the host to create a vector store in FAISS (Facebook AI Similarity Search). This allowed us to query the narrative using range search that returned relevant results. A key part of our solution involved meaningful context-aware and narrative (limited character) imposed query construction and understanding/categorizing actions that cause a fall. We also dug into the coding manual to understand how the narrative was structured and how best to extract precipitating events. We compared our solution to samples from OpenAI Chat GPT 3.5 and concluded ours was just as effective. Graphs were constructed for visualization and data exploration.
Check out saket's full write-up and solution in the competition repo.
xvii¶

Overall rank: 4th
Prize earned: $5,000
Team members: Ifechukwu Mbamali
Usernames: xvii
Hometown: Onitsha, Nigeria
Social handle or URL: /in/ifechukwu-mbamali/
Background:
Ifechukwu is an experienced Data Scientist in the CPG industry. His background is in engineering, and he holds a master’s degree in analytics from Georgia Institute of Technology.
What motivated you to participate?:
I was driven by the opportunity to work with medical related data, while contributing to solving an important challenge that could positively impact the lives of many.
Summary of approach:
My approach made use of embeddings, dimensionality reduction, clustering algorithms, network graphs and text summarization techniques to effectively identify and understand themes from medical narratives on older adults falls. The methods include:
(i) Clustering: The analysis employed DBSCAN algorithm in conjunction with UMAP processing on the dimension reduced (PCA) embeddings data to uncover key themes cluster.
(ii) Network graphs: these were used to explore keyword pair occurrences within narratives for the different clusters, with keyword ranking via the PageRank algorithm highlighting significant terms.
(iii) Text ranking and summarization: These methods were applied to generate summaries for narrative clusters to provide insights into key themes.
Check out xvii's full write-up and solution in the competition repo.
RyoyaKatafuchi¶

Bonus prize: Most promising mid-point submission
Prize earned: $2,500
Team members: Ryoya Katafuchi
Usernames: RyoyaKatafuchi
Hometown: Fukuoka Prefecture, Japan
Social handle or URL: @ml_xst
Background:
I am a data scientist at a Japanese tech company. My current role involves promoting and facilitating the efficient use of ChatGPT in business, as well as exploring innovative applications of generative AI. I have 2 years of experience in data analysis and over 3 years of experience in developing deep learning architectures. Outside of work, I enjoy traveling and comedy shows.
What motivated you to participate?:
During an actual data analysis project that I was involved in, I had the opportunity to extract insights from a large-scale text dataset similar to what we used for this project. I wanted to apply the knowledge I gained from that experience to other data science projects and also developed an interest in exploring new ways to utilize Large Language Models (LLMs). I'm eager to apply the insights I've gained here to our ongoing projects.
Summary of approach:
I believed that there is a preceding action that caused the fall as information unique to narrative. While there is information about the object that caused the fall, it alone cannot infer the fundamental cause of the fall, which would help in devising fall prevention measures. Hence, I focused on the information, "What action led to the fall?” As my approach to get the information, I carried out the extraction of actions by ChatGPT using the OpenAI API. And with this result, I analyzed the primary data to try to gain some insights with other columns.
Check out RyoyaKatafuchi's full write-up and solution in the competition repo.
jimking100¶

Bonus prize: Best visualization
Prize earned: $2,500
Team members: Jim King
Usernames: jimking100
Hometown: Mill Valley, CA
Background:
I’m a successful real estate agent who happens to like data science. My Computer Science degree, MBA in Finance and 20 years in the tech field also help.
What motivated you to participate?:
I love learning, a challenge and competition! The fact that the work may have a positive social impact is an added bonus.
Summary of approach:
I used a custom Named Entity Recognition (NER) model to identify cause and precipitating event keywords in the narrative section of the primary data. The custom keywords were organized into four major categories: method of fall (fall, trip, slip), care facility involvement, medical event involvement, and activity involvement. There are several reasons for selecting this approach:
-
Most of narrative is detailed in the other features, so the few words remaining often refer to the cause or precipitating event. The key is to identify “cause” keywords and a NER model is an excellent method.
-
A custom NER model allows for the very specific medical terms and events used in the narrative.
-
A NER model can be used to highlight cause factors in the text and provide real-time feedback to those entering and using narrative data.
Check out jimking100's full write-up and solution in the competition repo.
Research4Good¶


Bonus prize: Best null result
Prize earned: $2,500
Team members: YWT and Chung Wai Tang
Hometown: Hong Kong
Background:
YWT is a computer scientist by training and currently works as a researcher developing methods based on computer vision, machine learning, and deep learning for applications in public health. During her free time, she volunteers as a mentor for junior research trainees.
Chung Wai Tang is a graduate student researcher from the University of Nottingham. He is passionate about writing, gerontology and computer applications in healthcare. Outside of his graduate studies, he is a full-time secondary school instructor and leader of the “Business and Economics” department, with over ten years of experience from two different internationalized schools.
What motivated you to participate?:
We are passionate in gerontology and love to contribute in every minor way to advance knowledge that helps promote the health and wellness of older adults. This is our second team competition/ experience. Compared to our previous competition experience in a different platform, the series of challenge deadlines and prizes offered in this competition strongly motivated us to place our first baby steps on the research field of natural language processing, a completely foreign territory to us. We especially appreciated the thoughtfulness behind planning this competition, such as the live (and recorded) information sessions with the host/ domain-knowledge experts.
Summary of approach:
Research statement: We investigated the potential of various survival model candidates that were trained to map data collected at baseline to patients’ future outcomes, as measured using disposition categories, as a surrogate to patients’ severity levels. If successful, these models, when deployed on a web application for instance, will help assess the necessity of hospital visits at baseline.
Details on methods: In representing the textual narratives, we explored various large language models. In creating the outcome definitions, which involved the use of survival objects, i.e. each outcome represented by an event indicator and corresponding event time (e.g. number of hours from fall to hospital visit, or treatment at the hospital), we extracted time to event data from the textual narratives via keyword searches that account for typos. To aid the secondary analysis of seasonal trends in falls that may help the prediction results, we also extracted month and year from the “treatment_date” baseline variable.
To interpret how different language models generate different word embeddings, we used the UMAP algorithm to reduce the dimensionality of each word embedding and then plotted them on two-dimensional plots and coloured each sample based on the value of a categorical demographic variable (e.g. race and sex). In terms of baseline categorical variables to exclude in the prediction task, we dropped “fire involvement” due to its sparsity in order to bypass degenerate mathematical formulation. We also omitted “diagnosis” as they correlated with disposition (likewise, other diagnostic information in the narratives were also stripped out before calculating the word embeddings).
Finally, we fitted different model candidates using different combinations of input data (e.g. using a single set of word embeddings alone, using their dimensionality reduced versions, combining all types of word embeddings with select demographic variables).
In summary, we observed that using all compressed feature representations have led to the best prognostic accuracies of survival models that were fitted using the eXtreme Gradient Boosting (XGB) models. To compare with a reference approach, we employed Cox’s regression, which is a commonly adopted baseline for survival data analysis. The log of the hazard ratios and their confidence intervals are shown in the figure below (see competition repo).
Check out Research4Good's full write-up and solution in the competition repo.
SeaHawk¶




Bonus prize: Most novel approach
Prize earned: $2,500
Team members: Md Umarfaruque, Aayush Khurana, Gaurav Yadav, and Yash Aggarwal
Usernames: umarfaruque, aayushkh, gd_404, YAggarw1
Hometown: Saharsa, Bihar, India; New Delhi, India; Kurukshetra, Haryana, India; New Delhi, India
Social handle or URL: /in/umaruza, /in/aayush-khurana-8ab7b9169, /in/gd404, /in/yash-aggarwal-57a293152
Background:
Umar is a senior Data Science Associate Consultant at ZS in New Delhi, specializing in the R&D AI domain.His technical proficiency spans a wide range of fields, including Statistical Modeling, Probabilistic Programming, Operations Research, Natural Language Processing (NLP), Recommender Systems, and Advanced Machine Learning. In his role, Umar strives to harness these technical capabilities to deliver innovative data-driven solutions, ultimately helping pharmaceutical clients optimize their clinical trial processes and make informed decisions.
Aayush is a Senior Data Scientist based at the ZS New Delhi office, specializing in the R&D AI domain. Within the AI RDE life sciences space at ZS, he plays a key role in developing advanced data science solutions aimed at accelerating clinical trials, drug discovery, and building NLP-based pipelines. His technical proficiency spans a wide range of fields, including Natural Language Processing, Transfer Learning, Ensemble Learning, and a deep understanding of Deep Learning libraries such as TensorFlow, Keras, and Pytorch. Aayush is adept at creating insightful visualizations using libraries like Autoviz, Matplotlib, Seaborn, and Plotly, enhancing the interpretability of data-driven insights. His proficiency extends to utilizing Large Language Models toolkits such as HuggingFace, LangChain, OpenAI and LlamaIndex, showcasing his ability to leverage cutting-edge natural language processing capabilities.
Gaurav Yadav holds the position of Senior Data Scientist at ZS and has contributed to the Research and Development unit for over two years. He specializes in crafting and implementing data science solutions within the healthcare sector. His proficiency in Data Science revolves predominantly around text data and natural language processing with a focus on various research initiatives, notably exploring the efficacy of Large Language Models in resolving intricate business challenges.
Yash Aggarwal, a seasoned Senior Data Scientist at ZS Associates, boasts over four years of dedicated service in the Research and Development domain. Specializing in healthcare, Yash has played a pivotal role in optimizing processes for drug discoveries, formulating market strategies, and refining study designs for clinical trials through the application of AI. Yash's proficiency in Data Science is particularly pronounced in the realm of Natural Language Processing (NLP) and text data analysis.
What motivated you to participate?:
Our motivation was fueled by a genuine desire to make a positive impact on public health by unraveling the complexities surrounding older adult falls. The commitment to understanding and addressing this critical issue not only propelled us through the challenge but also underscored our team's broader mission of applying data science for the betterment of society.
Summary of approach:
Our approach consists of a two-step methodology to effectively work with the primary dataset. In the initial phase/step, we leverage Large Language Models (LLMs) to create a gold standard dataset, which serves as training data for fine-tuning a classification model. This involves a unique clustering approach, where representative samples are extracted from the dataset utilizing PCA for dimension reduction and KMeans for cluster creation. Subsequently, LlaMA2 and OpenAI’s GPT-3.5 are employed for zero-shot classification to extract important information such as the severity of fall, action performed just before fall, and risk factors associated/reason for the fall from the ED visit narrative texts. The reliability of this gold dataset is confirmed through manual validation and extensive Exploratory Data Analysis (EDA).
Then in the second step, we fine-tune a DistilBERT model using the golden dataset to classify severity, action before fall, and reason for fall. This fine-tuned model is then applied to predict classification labels for the complete primary dataset thereby enabling us to generate insights.
A distinctive feature of our approach is a novel data sampling strategy, wherein the data is segmented into 10,000 diverse clusters. To ensure maximum diversity in the sample dataset, we select the data point closest to each cluster's centroid. This approach is designed to capture the essence of the original dataset. It was observed that the sampled data followed similar distribution as that of the actual primary data. This is supported by the data analysis performed on the sample data as well as the actual data. Thorough data analysis validates the reliability of our sampling strategy, affirming the consistency between insights derived from the sample and the actual dataset.
Check out SeaHawk's full write-up and solution in the competition repo.
Thanks to all the challenge participants and to our winners! Thanks, too, to the CDC/NCIPC and NASA for sponsoring the challenge.



















