Wind-dependent Variables: Predict Wind Speeds of Tropical Storms¶
Tropical cyclones have become more destructive in the last decades as we experience a warmer climate. These winning solutions help estimate the potential consequences of storms and provide near real-time insight into these phenomena, saving lives and reducing damages.
The performance of the top models from the competition underscores the opportunities that machine learning techniques provide for addressing the real-world problems we are facing due to a changing climate.
Hamed Alemohammad, Executive Director and Chief Data Scientist at Radiant Earth Foundation
The motivation¶
Tropical cyclones, which include tropical depression, tropical storms, hurricanes, and major hurricanes, are one of the costliest natural disasters globally. Hurricanes can cause upwards of 1,000 deaths and $50 billion in damages in a single event, and have been responsible for well over 160,000 deaths globally in recent history.
During a tropical cyclone, humanitarian response efforts hinge on accurate risk approximation models. These models depend on wind speed measurements at different points in time throughout a storm’s life cycle, as wind speed is the main factor that contributes to a storm’s death toll.
For several decades, forecasters have relied on adaptations of the Dvorak technique to estimate cyclone intensity, which involves visual pattern recognition of complex cloud features in visible and infrared imagery. While the longevity of this technique indicates the strong relationship between spatial patterns and tropical cyclone intensity, visual inspection is manual, subjective, and often leads to inconsistent estimates between even well-trained analysts.

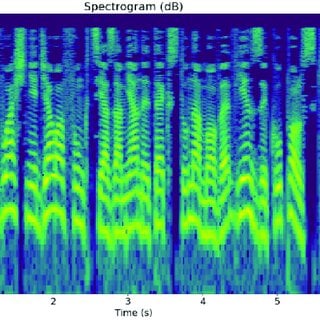
Single-band satellite images of storms at a long-wave infrared frequency from the competition dataset assembled by Radiant Earth Foundation and the NASA IMPACT team
There is a vital need to develop automated, objective, and accurate tropical cyclone intensity estimation tools from satellite image data. In 2018, the NASA IMPACT team launched an experimental framework to investigate the applicability of deep learning-based models for estimating wind speeds in near-real time. An initial model was trained on storm images from 2000 to 2016 and demonstrated the effectiveness of using Convolutional Neural Networks (CNNs) to capture these key patterns in storm imagery. This challenge sought to improve upon this model for operational applications and short-term intensity forecasting.
The results¶
The goal of Wind-dependent Variables: Predict Wind Speeds of Tropical Storms was to estimate the wind speeds of storms at different points in time using satellite images captured throughout a storm’s life cycle. A dataset of single-band satellite images and wind speed annotations from over 600 storms was prepared by Radiant Earth Foundation and the NASA IMPACT team. Because participants were provided with each image’s relative time since the beginning of the storm, models could take advantage of this temporal data but could not use images captured later in a storm to predict earlier wind speeds.
Over 700 participants stepped up to this important challenge, generating more than 2,700 entries! To measure performance, we used a metric called Root Mean Square Error (RMSE), a common measure of accuracy that quantifies differences between estimated and observed values. Each of the top three models achieved at least a 50% reduction in RMSE as compared to the existing model!

The top-performing models obtained RMSEs between 6.25 and 6.50 knots, demonstrating a significant improvement over the original deep learning-based Hurricane Intensity Estimator and our benchmark solution. They were able to take advantage of the relative timing of images in a storm sequence to produce targeted wind speed estimates based on temporal trends. As a result, these solutions can help to improve disaster readiness and response efforts around the world by equipping response teams with more accurate and timely wind speed measurements.
All of the prize-winning solutions from this competition are linked below and made available for anyone to use and learn from. ** Meet the winners and learn how they built their models! **
Meet the winners¶
Igor Ivanov¶

Place: 1st
Prize: $6000 and $8000 Azure credit
Hometown: Dnipro, Ukraine
Username: vecxoz
Background:
My name is Igor Ivanov. I'm a Deep Learning Engineer from Dnipro, Ukraine. I specialize in computer vision and natural language processing and I work at a small local startup.
What motivated you to compete in this challenge?
First, there was a high quality dataset and a very interesting task. The organizers did a great job collecting a large and deeply representative set of satellite images. Also, during this period I received support from the TFRC program offering TPU resources to researchers. Given that I had enough time and compute resources, and the task directly relates to my specialization and personal interests, I just couldn’t pass it by.
Summary of approach:
My final solution is an ensemble of 51 models based on several different architectures, which are trained with different backbones and on different depths of historical frames. The data is a time series of monochrome images depicting the evolution of tropical storms. From the beginning, it was evident that there are two important directions to take advantage of:
- State-of-the-art convolutional models and their pretrained weights, and
- Time-related information (i.e. process sequences of images)
First, I train a model using 3-channel RGB images consisting of the current frame and two previous frames. This approach performs better than using monochrome images because it fully utilizes ImageNet pretrained weights. See the figure below for an example of this technique.
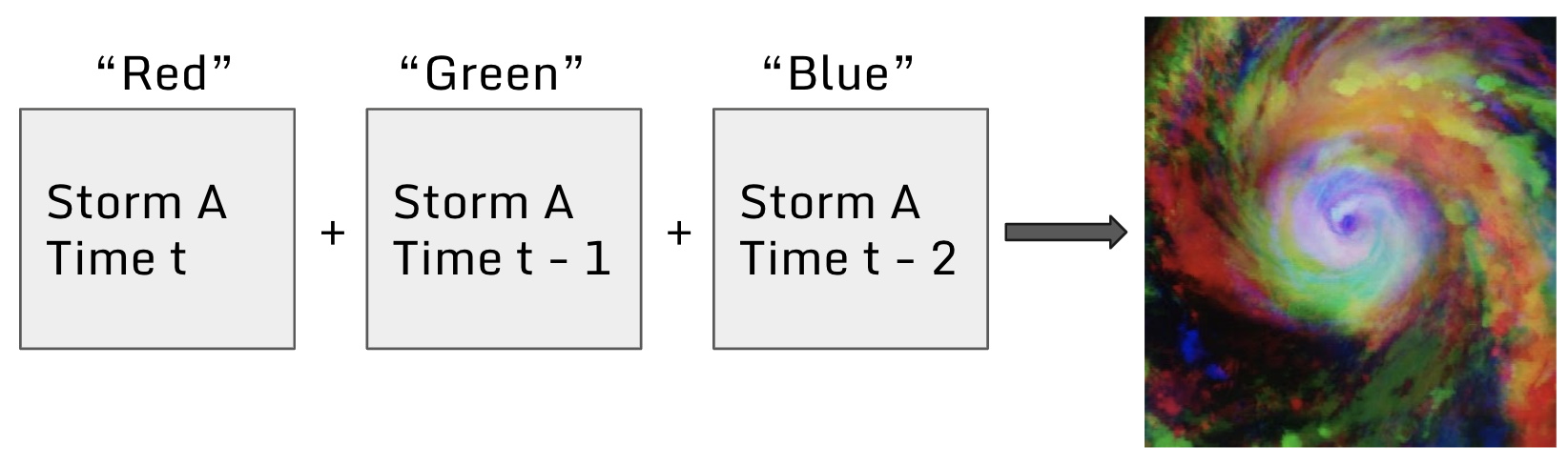
Concatenating monochrome image frames to produce a 3-channel image introduces time-related information to the model
Building on this idea, I use images from different historical depths as channels. The best combination is 9 steps (i.e. [t, t-9, t-18]). Image processing includes augmentations (flips and rotations) and corresponding Test Time Augmentation (TTA).
Next, I extract features from series of 3-channel images using a Convolutional Neural Network (CNN) and process these extracted features with a Long Short-term Memory network (LSTM) or Gated Recurrent Units (GRU) (see this paper for additional information). To process sequences of images, I use a TimeDistributed layer. The best configuration is 24 consequent monochrome frames represented as sequences of 8 RGB images trained with a unidirectional LSTM without attention. The final ensemble leverages a weighted average optimized using pairwise greedy search over sorted predictions.
Check out vecxoz’s full write-up and solution in the competition repo. The write-up also includes helpful instructions for how to use a subset of these models to achieve similar performance.
Karim Amer¶

Place: 2nd
Prize: $4500 and $6000 Azure credit
Hometown: Cairo, Egypt
Username: KarimAmer
Background:
I am the head of AI/ML at Visual and AI Solutions (a Nile University spinoff). I previously worked as a research assistant with the Ubiquitous and Visual Computing Group at Nile University, where I published several papers about satellite image analysis between 2016 and 2018. In 2019, I became a research intern at Siemens Healthineers Technology Center, NJ, USA where I worked on the development of cutting edge segmentation models that can be used in multiple clinical applications.
What motivated you to compete in this challenge?
I wanted to contribute to analyzing tropical storms since it can affect many people’s lives.
Summary of approach:
My approach has three stages. In the first stage, ImageNet pretrained Convolutional Neural Networks (CNNs) are fine-tuned on the image dataset with different time steps in multiples of three (current image and two prior images). These images are concatenated channelwise to create 3-channel images that are passed through a CNN for feature extraction. The features from each 3-channel image are concatenated and passed through a fully connected layer to produce intermediate predictions. Some models are trained using 1, 3, 6, 9, or 12 consecutive time steps, and some models are trained using 6 time steps with spacing between each step (eg. every other prior image). In addition to rotation and flipping, time augmentation is applied by dropping or repeating one of the input images besides the main image. All models are trained using 224 x 224 pixel images. Test Time Augmentation (TTA) is also applied on all predictions.
In the second stage, approximately 200 models are trained on the intermediate predictions from the first stage models, taking into consideration a history of 25-30 time steps. The models include CNNs, Long Short-term Memory networks (LSTM), Gated Recurrent Units (GRU), Multilayer perceptrons (MLP), eXtreme Gradient Boosting (Xgboost), Transformers, Decision Trees, and Linear Regression. Each model is trained on a different CNN output using Deep Adaptive Input Normalization.
In the final stage, ensemble selection is applied to combine the best group of second stage models.
Check out KarimAmer’s full write-up and solution in the competition repo.
Daniel F.¶

Place: 3rd
Prize: $2500 and $4000 Azure credit
Hometown: Bristol, UK
Username: Daniel_FG
Background:
I’m a Machine Learning Researcher who specializes in computer vision and deep learning. I very much enjoy facing new challenges, so I spend part of my spare time participating in machine learning and data science competitions.
What motivated you to compete in this challenge?
The topic and the dataset.
Summary of approach:
My approach is based on a two layer pipeline. The first layer is 14 Convolutional Neural Network (CNN) based regression models and the second is a Gradient Boosting Machine (GBM) that adds extra features to the first layer predictions and past predictions.
The first layer is trained over a stratified k-folds split scheme. I fine-tune models on sequences of 8 or 12 3-channel images created by joining an image with two prior timesteps using a block sampling strategy, or repeating a single channel image. I apply flip, rotation, crop, and time augmentations as well as Test Time Augmentation (TTA) to obtain intermediate predictions. I also fine-tune one model using Optical Flow Vectors on a sequence of 5 images spaced 1 hour apart.
In the second layer, lightGBM is used to predict wind speeds based on first level model predictions at time t, first level model predictions at prior times (eg. t-1, t-8, t-24), the ocean, and the image’s relative time field. At prediction time, the model substitutes past predictions for actual wind speeds from the training data, taking advantage of known past velocities.
While ensembling 14 models achieves the highest performance, a comparable RMSE of 6.65 can be achieved by ensembling a smaller subset of 4 models.
Check out Daniel_FG’s full write-up and solution in the competition repo.
--
Thanks to all the participants and to our winners! Special thanks to Radiant Earth Foundation for enabling this important and interesting challenge and for providing the data to make it possible!