If you've looked at videos collected from trail cameras, you might have found that a large fraction of them contain no visible animals. And if you've spent much time looking at blank videos, you might wish there was a better way!
Well, there is. Using automatic classification from Zamba, an AI tool for wildlife research and conservation, you can eliminate a substantial fraction of blank videos, sight unseen, while losing only a small fraction of videos that actually contain animals.

|

|
The goal of this article is to quantify that claim. Here's how we'll do it:
-
To train Zamba's classification model, we collected more than 280,000 videos from researchers at the Max Planck Institute for Evolutionary Anthropology working in West, Central, and East Africa.
-
We used about 250,000 of those videos to train the model (the training set) and reserved about 30,000 for testing (the holdout set). The videos in the holdout set are selected on a transect-by-transect basis; that is, videos from each camera location are assigned entirely to the training set or entirely to the holdout set. So the performance of the model on the holdout set should reflect its performance on videos from a transect the model has never seen.
-
We use selected videos from the holdout set to simulate the use of the model for identifying blank videos. In our holdout set, 42% of videos are blank, so if we can eliminate them, we could save a substantial fraction of viewing time, storage space, and data transfer costs.
Let's see how well we can do.
Probablistic classification¶
Results from machine learning models are often reported in terms of recall and precision. For identifying blank videos, recall is the percentage of blank videos that are correctly classified as blank. Precision is the percentage of videos classified as blank that are, in fact, blank. Of videos in the holdout set, 13,034 are actually blank; of those, 11,288 are classified as blank, so recall is 87%. Going in the other direction, 13,507 videos are classified as blank; of those, 11,288 are actually blank, so precision is 84%.
Those metrics give a general sense of how good the classifications are, but they don't demonstrate the value of the model as well as they could. In particular, they do not take advantage of an important feature of the model: it does not just produce classifications; it assigns a probability to each category. In other words, the model does not just say, "I think this video is blank"; it says, "This video has a 90% chance of being blank". We can use those probabilities for several tasks, including the identification of blank videos.
As a first step, let's see how accurate the probabilities are; then we'll think about how to use them.
Calibration¶
Suppose the model says that a particular video has a 70% chance of being blank. If we watch the video and find that it's blank, does that mean the model was 70% right? Or if the video actually contains an animal, was it 70% wrong? One way to answer that question is to evaluate a set of videos rather just one. For example, suppose there are 100 videos with predicted probabilities near 70%. If 70 of them are actually blank, we'd say that the probability was well calibrated. If 50 of them are blank, or 90 of them, we would be less impressed.
Applying this logic to videos in the holdout set, we can sort them by their probability of being blank, according to Zamba, and put them into groups. Within each group, we compute the average of the predicted probabilities and the actual proportion that are blank. Then we plot one point for each group, as shown in the following figure:
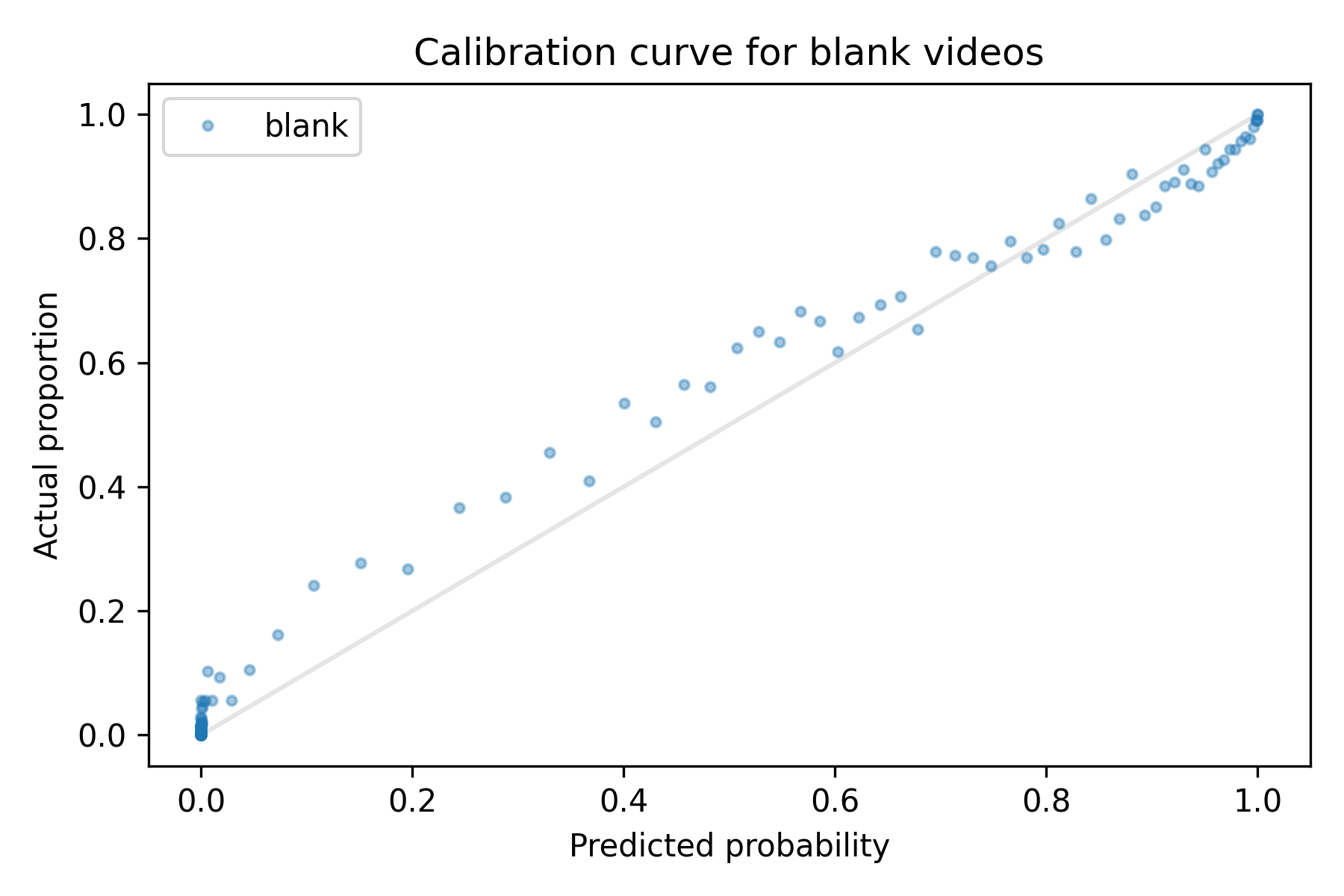
The x-axis shows the predicted probabilities; the y-axis shows the actual proportions. The gray line shows where the two are equal; if the predictions were perfect, all points would fall on this line.
In fact, the predictions are not perfect, but most of the points are close to the line, so the probabilities are generally well calibrated. However, between 0.1 and 0.6, the actual proportions are a little higher than the predicted probabilities; for example, when the predictions from the model are near 30%, the actual proportions are closer to 40%.
Another thing we can see in this figure is that there are more points near 0 and 1 than in the middle. That means that the model is often confident that a video is either blank or not; there are fewer videos where it is unsure. That's good -- it means that the predictions are not just calibrated; they are also likely to be more useful.
Pruning the blanks¶
There are two ways we might use the probabilities Zamba generates:
-
One strategy is to choose a threshold and discard videos whose probability of being blank exceeds the threshold.
-
Another option is to sort videos in increasing order by probability of being blank and view them in that order (left to right in the calibration curve). The first batch of videos would be very likely to contain animals; the next batch a little less likely, and so on. A viewer might continue until they exhaust a budget of viewing time, or stop when the percentage of non-blank videos drops below an acceptable level.
We can use the holdout set to simulate the first strategy with a range of possible thresholds. For each threshold, we compute the fraction of blank videos that would be correctly discarded and the fraction of non-blank videos that would be incorrectly discarded. The first reflects time we could save (as well as storage space and data transfer costs); the second reflects the price we would pay in lost data.
The following curve shows the tradeoff between the benefit on the x-axis and the cost on the y-axis, as we vary the threshold from high (discard nothing) to low (discard everything).
![]()
The triangles indicate the benefit at three level of loss. If it's acceptable to lose 5% of non-blank videos, we can eliminate 63% of the blank videos, sight unseen. If we can tolerate a loss of 10%, we can eliminate 80%, and at a loss of 15%, we can eliminate 90% of blank videos.
Your mileage may vary¶
The previous figure shows results from a mixture of 14 locations in Africa; researchers with videos from different locations might see different results. To get a sense of how much variation we should expect, we identified five researchers who contributed more than 1000 videos in the holdout set. For each researcher, we computed the tradeoff between blank videos removed and non-blank videos lost. The following figure shows the results:
![]()
They are substantially different. In the best case, Researcher E could eliminate 100% of the blank videos while only losing 10% of the non-blanks. In the worst case, Researcher A could only eliminate 28%.
To get a sense of what drives this variation, we made the following table showing the characteristics of each set of videos and the performance metrics:
| researcher | # videos | # species | % blank | recall | precision | reduction at 10% loss |
|---|---|---|---|---|---|---|
| A | 2555 | 17 | 46.2 | 64.7 | 71.8 | 28.4 |
| B | 8217 | 18 | 43.8 | 85.7 | 79.8 | 70.6 |
| C | 14980 | 26 | 41.5 | 88.3 | 85.7 | 86.5 |
| D | 1988 | 13 | 87.3 | 98.8 | 98.5 | 98.7 |
| E | 1649 | 23 | 8.9 | 97.3 | 91.2 | 100.0 |
The first column is the number of videos in the holdout set that came from each researcher. The second column is the number of species seen in each set of videos. The third column is the percentage of videos that are blank, and here we see the first factor that affects performance. Among the videos from researcher E, fewer than 10% are blank, so it is relatively easy to eliminate them. At the other extreme, 87% of videos from researcher D are blank, which means it is relatively easy to find and eliminate them. It turns out that the hardest cases are in the middle, where the prevalence of blank videos is near 50%.
Even among the difficult cases, the videos from researcher A stand out as a challenge. Compared to B and C, which have similar prevalence of blank videos, precision and recall are lower, and the fraction of blank videos we can eliminate is much lower. A small part of this difference can be explained by the mixture of species that appear in the videos, since some animals are easier to classify than others. Other possible explanations are the prevalence of nighttime videos, the presence of obstructions in the field of view, and the general quality of the videos.
Which species are we losing?¶
For the purposes of wildlife research and conservation, not all non-blank videos are equally important. If we mistakenly discard some videos that actually contain animals, it might be more acceptable to miss some species, compared to others, depending on which ones are the subject of interest. And it turns out that Zamba's classifications are more likely to miss some species than others. To quantify those differences, let's consider the entire holdout set again, with a threshold chosen so that we correctly remove 80% of the blank videos while wrongly removing 10% of the non-blank videos.
The following table shows the breakdown of the 10% we would miss (excluding categories with counts smaller than 10):
| count | # lost | % lost | |
|---|---|---|---|
| reptile | 12 | 5 | 41.7 |
| rodent | 738 | 294 | 39.8 |
| porcupine | 347 | 122 | 35.2 |
| mongoose | 293 | 77 | 26.3 |
| civet_genet | 232 | 60 | 25.9 |
| badger | 45 | 8 | 17.8 |
| aardvark | 18 | 3 | 16.7 |
| small_cat | 36 | 6 | 16.7 |
| bird | 379 | 59 | 15.6 |
| pangolin | 53 | 8 | 15.1 |
| leopard | 37 | 4 | 10.8 |
| antelope_duiker | 8298 | 723 | 8.7 |
| wild_dog_jackal | 14 | 1 | 7.1 |
| monkey_prosimian | 2878 | 190 | 6.6 |
| elephant | 835 | 49 | 5.9 |
| hyena | 18 | 1 | 5.6 |
| hog | 753 | 39 | 5.2 |
| chimpanzee_bonobo | 857 | 43 | 5.0 |
| gorilla | 61 | 3 | 4.9 |
| hippopotamus | 21 | 1 | 4.8 |
| cattle | 94 | 4 | 4.3 |
| human | 1442 | 42 | 2.9 |
| equid | 70 | 1 | 1.4 |
| forest_buffalo | 23 | 0 | 0.0 |
The first column shows the number of videos in the holdout set that contain each species or category, as labeled by human viewers. The second column shows the number of those videos that would be wrongly removed as blank; the third column shows the percentage that would be lost.
In the top half of the table, we see mostly animals that are small, and therefore hard to detect, or rare, which means that the model has fewer examples to learn from. At the level where we lose 10% of the non-blank videos overall, we lose a larger percentage of those species; for example, we might lose more than 30% of reptiles, rodents, and porcupines. If those categories are relevant to research interests, eliminating blanks might not be the best strategy; in that case, an alternative is a targeted search, which will be the subject of a future article.
However, if the target categories are primarily large, common animals, we can often do better than 10%. In this example, we would lose fewer than 5% of chimpanzees, gorillas, and hippopotamuses.
Having watched a sample of videos that were wrongly classified as blank, we can say informally:
-
Many of them are at night, in environments where the field of view is obstructed, out of focus, or overexposed.
-
A few were recorded while someone was installing or removing a camera, so the field of view is moving.
-
In many cases, the animal is barely in frame or visible for only a short time.
Here are a few examples so you can see if you would do better than Zamba (answers at the end of the article).
Can you find the duiker in this video?
And can you identify the animal in this video before it fades to black?
Finally, if you are wondering how Zamba missed 49 elephants, here's an example that reminds us of an old joke: "Q: How come you never see elephants hiding in trees? A: Because they're so good at it."
Summary¶
Zamba does not just classify videos; it generates probabilistic predictions, which are useful for several applications. In this article, we considered one application: eliminating blank videos in order to save viewing time, storage space, and data transfer time. We quantified the fraction of blank videos that could be removed while controlling the number of non-blank videos that would be lost. And we explored some of the factors that would affect the performance of this strategy, including the prevalence of blank videos and the mixture of species represented.
In future articles we will explore other use cases where we can take advantage of probablistic predictions, including a targeted search for videos containing a particular species or category of animals.
Answers to the video challenges: (1) The duiker exits on the right side of the screen at 0:01. (2) The mystery animal is a pangolin.



















