

Privacy-enhancing technologies (PETs) have the potential to unlock more trustworthy innovation in data analysis and machine learning. Federated learning is one such technology that enables organizations to analyze sensitive data while providing improved privacy protections. These technologies could advance innovation and collaboration in new fields and help harness the power of data to tackle some of our most pressing societal challenges. That’s why the U.S. and U.K. governments partnered to deliver a set of prize challenges to unleash the potential of these democracy-affirming technologies to make a positive impact.
The goal of the U.S.-U.K. PETs Prize Challenges was to advance privacy-preserving federated learning solutions that provide end-to-end privacy and security protections while harnessing the potential of AI for overcoming significant global challenges. The challenge utilized a red team/blue team approach with two types of participants: blue teams developed privacy-preserving solutions, while red teams acted as adversaries to test those solutions. This post introduces the U.S. winners of Phase 2 and Phase 3 of this three-part challenge:
- In Phase 1: Concept Paper, blue teams wrote technical concept papers proposing their privacy-preserving solutions. You can read about the results of Phase 1 in our previous "Meet the Winners" post.
- In Phase 2: Solution Development, blue teams developed working prototypes of their solutions. These were submitted to a remote execution environment which ran federated training and evaluation.
- In Phase 3: Red Teaming, independent red teams of privacy researchers scrutinized and tested the blue team prototypes for privacy vulnerabilities.
You can meet the U.K. winners in this blog post by Innovate UK.
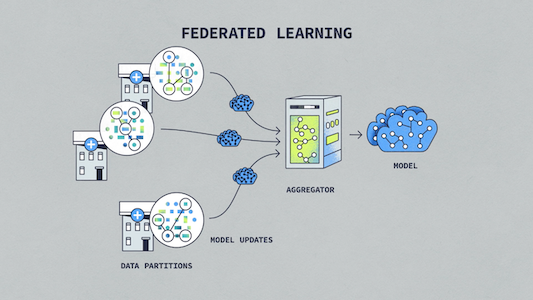
The goal of the challenge was to accelerate the development of efficient privacy-preserving federated learning solutions that leverage a combination of input and output privacy techniques to:
- Drive innovation in the technological development and application of novel privacy-enhancing technologies.
- Deliver strong privacy guarantees against a set of common threats and privacy attacks.
- Generate effective models to accomplish a set of predictive or analytical tasks that support the use cases.
Teams competing in the challenge participated in two separate data tracks: Track A dealt with the identification of financial crime, and Track B was about bolstering pandemic forecasting and response. A total of $675,000 in prizes are being awarded to teams over the course of the entire competition.
|
Read on for summaries of what we saw in Phase 2 and Phase 3 of the challenge, or skip ahead to meet the winning teams.
Phase 2: Solution Development¶
Phase 2 of the challenge took place from October 2022 to late January 2023. All blue teams that submitted concept papers in Phase 1 meeting minimum requirements were invited to participate in Phase 2. Teams were tasked with turning their proposals into working software: they were required to submit runnable code for their privacy-preserving federated learning (PPFL) solution, as well as a centralized version without privacy techniques that was used for comparison.
For the challenge, DrivenData created a federated evaluation harness that simulated federated model training and subsequent test set inference using teams' submitted code. The evaluation harness measured solutions' computational resource usage—including runtime, memory, and simulated network load—which factored into the judging. Solutions were run under three different federation scenarios with the dataset split up into different numbers of partitions in order to evaluate scaling properties.
Teams' solutions were judged on the following criteria:
- Privacy: Information leakage possible from the PPFL model during training and inference. Ability to clearly evidence privacy guarantees offered by solution in a form accessible to a regulator and/or data owner audience.
- Accuracy: Absolute accuracy of the PPFL model developed (measured by AUPRC). Comparative accuracy of PPFL model compared with a centralized model.
- Efficiency and Scalability: Time to train PPFL model and comparison with the centralized model. Network overhead of model training. Memory (and other temporary storage) overhead of model training. Ability to demonstrate scalability of the overall approach taken for additional nodes.
- Adaptability: Range of different use cases that the solution could potentially be applied to, beyond the scope of the current challenge.
- Usability and Explainability: Level of effort to translate the solution into one that could be successfully deployed in a real world environment. Extent and ease of which privacy parameters can be tuned. Ability to demonstrate that the solution implementation preserves any explainability of model outputs.
- Innovation: Demonstrated advancement in the state-of-the-art of privacy technology, informed by above-described accuracy, privacy and efficiency factors.
At the end of Phase 2, Track A: Financial Crime had complete submissions from 7 teams, while Track B: Pandemic Forecasting had complete submissions from 4 teams. After a round of review and judging, 4 finalists from Track A and 3 finalists from Track B moved onto red team attacks. The results of the red team attacks informed a final round of judging to select the top three winners for each track.
To be effective, the winning teams needed to be thoughtful in how they approached the privacy and modeling aspects of their tasks.
Privacy¶
Federated learning is a technology that allows multiple data providers to jointly train machine learning models on sensitive data without directly transmitting any of that data. However, there still exist risks when using federated learning alone that sensitive information can be extracted, such as from either eavesdropping on the learning process (input privacy) or from the fitted models (output privacy). Consequently, successful teams in the challenge incorporated a variety of additional privacy-enhancing technologies as part of their solution.
All top teams from both tracks used differential privacy as part of their solution. Differential privacy is a formal mathematical methodology for adding noise to a dataset and measuring how that noise affects the ability to infer information about individuals in the dataset. The formalism of differential privacy offered a systematic way for the teams to mathematically prove and quantify the privacy properties of intermediate computations as well as the final model.
Most teams additionally incorporated cryptographic techniques as a part of their solution in order to protect data as it is exchanged between parties during the federated learning. Techniques used include homomorphic encryption and/or secure multiparty computation (SMPC) protocols such as secure aggregation and private set intersection.
Modeling¶
Most teams experimented with a variety of modeling algorithms, and many noted that the privacy techniques in their solutions could be paired with more than one family of machine learning models.
In Track A, teams were asked to perform anomaly detection on a synthetic dataset of financial transactions held by an interbank messaging network supplemented by associated synthetic account data held by banks. Of the two tracks, this track's task was closest to a typical tabular classification task. The first- and third-place teams chose to use XGBoost for their submitted implementation, while the second-place team used a multilayer perceptron neural network.
For Track B's pandemic forecasting task, teams had to model a complex dynamical system representing a disease outbreak in a simulated population of Virginia. The underlying mechanics of infections was fairly straightforward—exposures lead to infections—but this problem was made hard by the enormity of the system, with over 7 million individuals involved in a complex graph of daily contact over nine weeks of simulation. All top three teams opted for a relatively simple machine learning approach: some form of a linear model on top of graph-derived features. The first- and third-place teams' models were a form of logistic regression, while the second-place team used Poisson regression.
Phase 3: Red Teaming¶
Phase 3 of the challenge for red team participants began in November 2022. Red teams were given access to the blue team concept papers from Phase 1 in order to plan and prepare for conducting privacy attacks. During the two-and-a-half-week attack period in February 2023, red teams were given full access to blue teams' code in order to evaluate their privacy claims under both white box and black box privacy attacks.
Red teams were judged based on:
- Effectiveness: How completely do their attacks break or test the privacy claims made by the target solutions?
- Applicability/Threat Model: How realistic is the attack? How hard would it be to apply in a practical deployment?
- Generalizability: Is the attack specific to the target solution, or does it generalize to other solutions?
- Innovation: How significantly does the attack improve on the state-of-the-art?
The evaluation by red teams was a valuable input to the judging of blue teams. Red teams were able to examine blue team solutions at significant depth to scrutinize aspects such as the empirical privacy of specific parts of the dataset and the actual impact of the privacy techniques on models' accuracy.
What's next?¶
The PETs Prize Challenge was a unique competition that successfully brought together a large number of researchers and spurred interesting and innovative work in advancing privacy technology. In addition to soliciting over 50 white papers describing the conceptual approach and benefits of different solutions, this challenge also experimented with ways to push forward the applied implementation and evaluation of solutions in a common environment and a red teaming contest to pressure test their assumptions.
If you're interested in deeper dives on teams' solutions beyond the summaries below, be on the lookout for follow-up information. Many of the teams involved in the challenge intend to publish details and results of their approaches. The challenge also will be inviting selected winners to open-source their solution code for the Open Source Awards. We're looking forward to following the impact of all the teams and their developments on the field of PETs research.
Meet the winners¶
Without further ado, let's meet the winners and hear how they approached this fascinating challenge!
| Award | Phase 2 | Phase 3 | |
|---|---|---|---|
| Track A | Track B | Red Teams | |
| 1st | Scarlet Pets | puffle | ETH SRI |
| 2nd | PPMLHuskies | MusCAT | Entmoot |
| 3rd | ILLIDAN Lab | ZS_RDE_AI | Blackbird Labs |
| Special Recognition | Visa Research | ||
Track A: Financial Crime Prevention ¶
Scarlet Pets¶




Place: 1st in Track A: Financial Crime Prevention
Prize: $100,000
Team members: Hafiz Asif, Sitao Min, Xinyue Wang, Jaideep Vaidya
Hometown: Harrison and East Brunswick, NJ
Representing: Rutgers University
Social Media: /in/h-asif, /in/jaideep-vaidya
Background:
We are a group of privacy researchers at the Rutgers Institute for Data Science, Learning, and Applications (Rutgers I-DSLA).
- Hafiz Asif is a postdoc at I-DSLA. He received his Ph.D. from Rutgers University. His research is developing SAFE (secure & private, auditable, fair, and equitable) theoretical approaches and practical frameworks to leverage the power of data to solve real-world problems.
- Sitao Min is pursuing his Ph.D. at Rutgers University, focusing on developing methods for privacy- and fairness preserving data analysis in federated data settings.
- Xinyue Wang is pursuing her Ph.D. at Rutgers University. She is developing privacy-preserving methods to generate high-fidelity synthetic data and analyze genomic data.
- Jaideep Vaidya is a Distinguished Professor at Rutgers University and Director of I-DSLA. His general area of research is in privacy, security, data management, and data analytics, especially at their intersection. He is an IEEE and AAAS Fellow and ACM Distinguished Scientist.
What motivated you to participate?:
Machine learning applied over large datasets has the potential to result in significant scientific and societal advances. However, we strongly believe that the benefits of machine learning do not need to be at the cost of our individual liberty, including privacy and equity. There is an urgent need to devise methods that can enable the socially responsible use of machine learning technologies and to demonstrate their use in practice. The PETs Challenge was the ideal opportunity to show that machine learning can be privacy enhancing and that practical systems can be realized that provide both privacy and utility.
Summary of approach:
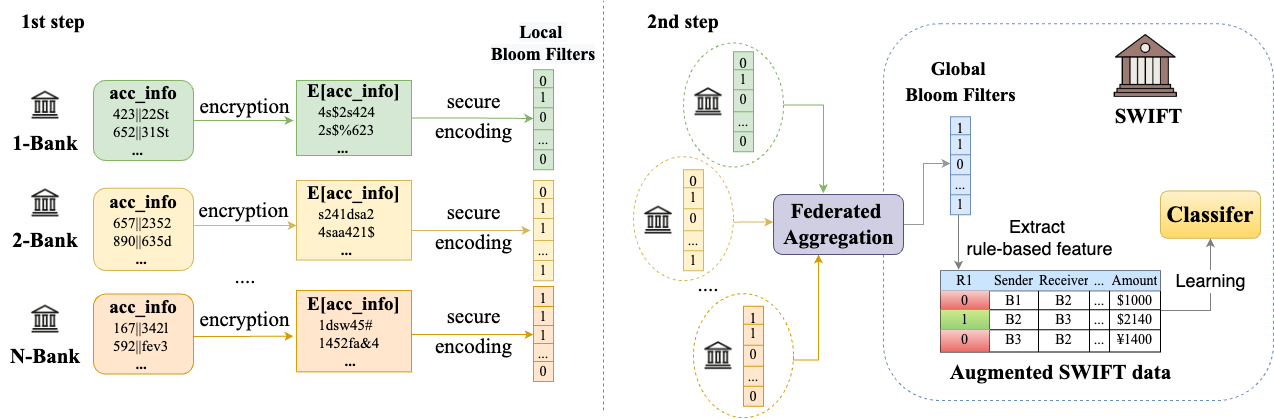
We developed a novel privacy-preserving (PP) two-step federated learning approach to identify anomalous financial transactions. In the first step, we performed PP feature mining for account-level banks’ data, followed by their augmentation to the messaging network’s data using a PP encoding scheme. In the second step, a classifier is learned by the messaging network from the augmented data. A key benefit of our approach is that the performance in the federated setting is comparable to the performance in the centralized setting, and there is no significant drop in accuracy. Furthermore, our approach is extremely flexible since it allows the messaging network to adapt its model and features to build a better classifier without imposing any additional computational or privacy burden on the banks.
PPMLHuskies¶









Place: 2nd in Track A: Financial Crime Prevention
Prize: $50,000
Team members: Martine De Cock, Anderson Nascimento, Sikha Pentyala, Steven Golob, Dean Kelley, Zekeriya Erkin, Jelle Vos, Célio Porsius Martins, Ricardo Maia
Hometown: Bellevue, University Place, Seattle, Tacoma, and Port Orchard, WA; Delft, The Netherlands; Brasília, Brazil
Affiliations: University of Washington Tacoma, Delft University of Technology, and University of Brasília
Social Media: /in/decockmartine, /in/anderson-nascimento-43a4852, /in/sikhapentyala, /in/steven-golob, /in/dean-kelley-0a7616103, @JelleVVos, /in/celio-porsius-martins-a0ab65202, /in/ricardojmm
Background:
Team PPMLHuskies was created specifically for the PETs Prize Challenge, bringing together research groups who had never collaborated before the competition. Consisting of professors and students from the University of Washington Tacoma, Delft University of Technology, and the University of Brasilia, team PPMLHuskies has strong interdisciplinary expertise in machine learning and cryptography. Spanning across three continents, the researchers on Team PPMLHuskies are united by a common goal of developing privacy-enhancing technologies to protect users in our data-driven society. The team’s members have a proven track record in privacy-preserving machine learning with 1st place positions in the iDASH2019 and 2021 competitions on secure genome analysis, a U.S. patent on cryptographically-secure machine learning, and publications in NeurIPS, ICML, PoPETS, IEEE Transactions on Dependable and Secure Computing, and IEEE Transactions on Information Forensics and Security, among others. From the University of Washington Tacoma: Dr. Martine De Cock, Professor; Dr. Anderson Nascimento, Associate Professor; Sikha Pentyala, graduate student; Steven Golob, graduate student; and Dean Kelley, graduate student. From Delft University of Technology: Dr. Zekeriya Erkin, Associate Professor; Jelle Vos, graduate student; Célio Porsius Martins, graduate student. From the University of Brasilia: Ricardo Maia, graduate student.
What motivated you to participate?:
We specialize in the development of technologies for privacy-preserving machine learning. We were particularly attracted to the financial crime detection track because it challenged participants to build a working solution for a critical problem with data that is horizontally and vertically distributed across data holders. Given that much of the existing work in federated learning has been developed for horizontally partitioned data only, we saw room for novel methodological contributions in this track. Finally, we greatly enjoy tackling difficult intellectual challenges with real-life impact. To say it with our team’s motto: "Problems worthy of attack prove their worth by fighting back." The financial crime detection track definitely fell in that category!
Summary of approach:
In our solution, the financial transaction messaging system and its network of banks jointly extract feature values to improve the utility of a machine learning model for anomalous payment detection. To do so in a privacy-preserving manner, they engage in a cryptographic protocol to perform computations over their joint data, without the need to disclose their data in an unencrypted manner, i.e. our solution provides input privacy through encryption. To prevent the machine-learning model from memorizing instances from the training data, i.e., to provide output privacy, the model is trained with an algorithm that ensures differential privacy.
ILLIDAN Lab¶





Place: 3rd in Track A: Financial Crime Prevention
Prize: $25,000
Team members: Jiayu Zhou, Haobo Zhang, Junyuan Hong, Steve Drew, Fan Dong
Hometown: East Lansing, MI
Affiliations: Michigan State University, University of Calgary
Social Media: /in/jiayuzhou, @hjy836, /in/fan-dong-1203b9147
Background:
The team is comprised of esteemed individuals from two prestigious universities: Professor Jiayu Zhou, head of the ILLIDAN Lab at Michigan State University, and his doctoral students, Haobo Zhang and Junyuan Hong, as well as Professor Steve Drew, head of the DENOS Lab at the University of Calgary, and his graduate student, Fan Dong. The ILLIDAN lab has made significant contributions to the advancement of machine learning, with a particular focus on transfer learning, robust learning, and federated learning methodologies and theories. On the other hand, the DENOS lab has spearheaded cutting-edge research in distributed learning systems, federated learning, AIOps, edge computing, and cloud-native initiatives for blockchain services. Working collaboratively, these two labs have made remarkable strides in developing federated learning algorithms and systems for real-world applications. Their collaboration has resulted in a dynamic and innovative approach to machine learning, one that will undoubtedly continue to impact the field for years to come.
What motivated you to participate?:
Our team is driven by a shared vision that data is the ultimate source of power for artificial intelligence. We believe that the effective integration of information from distributed data owners is key to continually improving our decision-making capabilities. However, the sensitive nature of data and issues surrounding ownership have presented significant barriers to achieving this goal. To overcome these challenges, we have focused our research efforts on developing federated learning systems. We firmly believe that such systems will become the most critical machine learning infrastructure in real-world applications in the next decade. Our team has been extensively investigating federated learning systems to better serve real-world applications, and this opportunity provides the perfect platform for us to challenge ourselves and put our algorithms and systems to the test. We are excited to take on this challenge and continue pushing the boundaries of machine learning research.
Summary of approach:
Our novel approach for detecting financial crime utilizes a hybrid of vertical and horizontal federated learning. We train an encoder to extract features from private data horizontally, while vertically fusing the features from different nodes. To protect data privacy, we incorporate encryption and noise injection during feature transfer and classifier training. Our privacy-preserving framework allows us to collaboratively learn a classifier for financial crime detection while maintaining privacy.
Visa Research¶












Place: Special Recognition Prize in Track A: Financial Crime Prevention
Prize: $10,000
Team members: Sebastian Meiser, Andrew Beams, Hao Yang, Yuhang Wu, Panagiotis Chatzigiannis, Srinivasan Raghuraman, Sunpreet Singh Arora, Harshal Shah, Yizhen Wang, Karan Patel, Peter Rindal, Mahdi Zamani
Hometown: Blacksburg and Fairfax, VA; San Jose, CA; Walla Walla, WA; Lübeck, Germany; Beijing and Anhui, China; Bangalore, Gurgaon, Ahmedabad, and Vadodara, India; Tehran, Iran
Representing: Visa Research
Social Media: /in/hao-yang-bb6ab429, /in/panos-chatzigiannis, /in/harshalbshah, /in/yizhen-wang-05194045, /in/karantech9, /in/peterrindal, /in/mahdi-zamani
Background:
Our team is comprised of members of Visa Research, with background in cryptography, security, privacy enhancing technologies, blockchain, secure computation, machine learning, and deep learning. We conduct fundamental and applied research on challenging problems in the payment industry, pushing the boundaries and driving innovation in the payments ecosystem.
What motivated you to participate?:
Visa and, by extension, our Visa Research team, has a special interest in payment fraud detection, and is committed to treating data with care and exploring privacy-preserving settings. Participation in the challenge of transforming Financial Crime Prevention was motivated by our team’s research interests and expertise in Artificial Intelligence and Security.
Summary of approach:
In our solution, we leverage the observation that the only additional data field the banks hold is an account "flag" attribute, which can be simplified into "normal" and "abnormal" states. The messaging network computes model updates for both assumed flags for each transaction in batches. Then, the messaging network, bank, and an "aggregator" participate in a multi-party computation (MPC) protocol. The messaging network provides the two possible updates, bank provides the flag, and aggregator adds noise (for differential privacy) to prevent inference attacks. The MPC ensures parties obliviously select the correct update, achieving privacy. For transaction classification, the messaging network derives two possible model outputs, then performs two-party computation (2PC) with the bank, ensuring it obliviously selects the correct output.
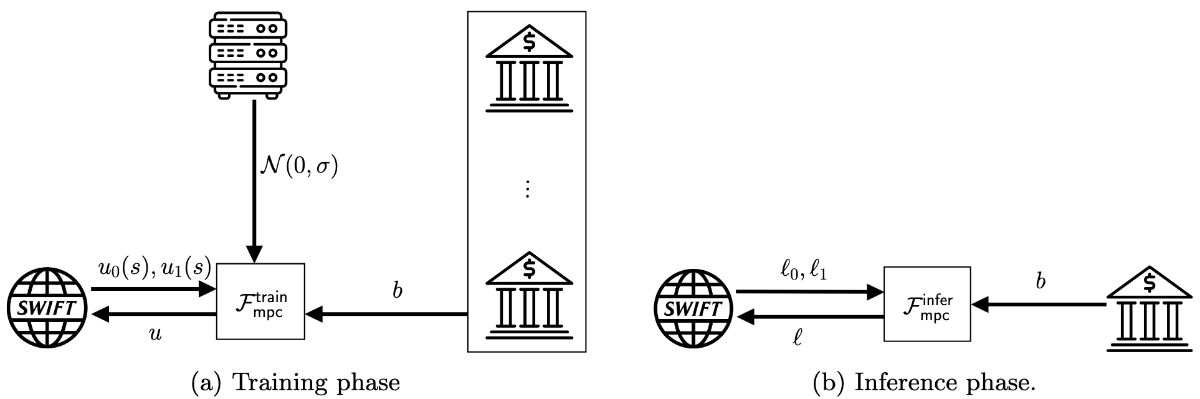
Track B: Pandemic Forecasting and Response ¶
puffle¶





Place: 1st in Track B: Pandemic Forecasting and Response
Prize: $100,000
Team members: Ken Ziyu Liu, Shengyuan Hu, Tian Li, Steven Wu, Virginia Smith
Hometown: Pittsburgh, PA
Affiliation: Carnegie Mellon University
Social Media:@kenziyuliu, @zstevenwu, @gingsmith
Background:
We are a group of students and professors at Carnegie Mellon University studying federated learning and privacy-preserving machine learning.
- Ken Ziyu Liu is an MS student at Carnegie Mellon University working with Virginia Smith and Steven Wu and previously a researcher at Google AI. His interests are in privacy-preserving machine learning, particularly in the areas of differential privacy, ML security, and federated learning.
- Shengyuan is a PhD student at Carnegie Mellon University working with Virginia Smith with expertise in federated learning and differential privacy.
- Tian Li is a PhD student at Carnegie Mellon University working with Virginia Smith with expertise in federated learning and optimization.
- Steven Wu is an Assistant Professor in the School of Computer Science at Carnegie Mellon University, with his primary appointment in the Software and Societal Systems Department, and affiliated appointments with the Machine Learning Department and the Human-Computer Interaction Institute. His research interests are in machine learning and algorithmic decision-making, especially in the areas of privacy, fairness, and game theory.
- Virginia Smith is an assistant professor in the Machine Learning Department at Carnegie Mellon University with expertise spanning machine learning, optimization, and distributed systems, including federated and collaborative learning systems.
What motivated you to participate?:
We have been studying federated learning and differential privacy for several years, and were excited for the opportunity to explore our methodologies on an important real-world application.
Summary of approach:
We build on our prior research to propose a simple, general, and easy-to-use multi-task learning (MTL) framework to address the privacy-utility-heterogeneity trilemma in federated learning. Our framework involves three key components: (1) model personalization for capturing data heterogeneity across data silos, (2) local noisy gradient descent for silo-specific, node-level differential privacy in contact graphs, and (3) model mean-regularization to balance privacy-heterogeneity trade-offs and minimize the loss of accuracy. Combined together, our framework offers strong, provable privacy protection with flexible data granularity and improved privacy-utility tradeoffs; has high adaptability to gradient-based parametric methods; and is simple to implement and tune.
MusCAT¶






Place: 2nd in Track B: Pandemic Forecasting and Response
Prize: $50,000
Team members: Hyunghoon Cho, David Froelicher, Denis Loginov, Seth Neel, David Wu, Yun William Yu
Hometown: Cambridge and Boston, MA; Austin, TX; Toronto, Canada
Affiliations: Broad Institute of MIT and Harvard, MIT, Harvard Business School, University of Texas Austin, University of Toronto
Social Media: @Hoon_Cho//in/hyunghoon-cho-5a410333, @DavidFroelicher//in/david-froelicher-b412a298, /in/denis-loginov-8a969618, @sethvneel
Background:
We are a group of privacy-enhancing technology experts who are passionate about developing rigorous and practical privacy-preserving solutions to address real-world challenges. Hyunghoon Cho is a Schmidt Fellow at Broad Institute, where his research involves solving problems in the areas of biomedical privacy, genomics, and network biology with novel computational methods. David Froelicher is a Postdoctoral Researcher at MIT and Broad Institute with expertise in distributed systems, applied cryptography, and genomic privacy. Denis Loginov is a Principal Security Engineer at Broad Institute with the Data Sciences Platform with expertise in application security and cloud computing. Seth Neel is an Assistant Professor at Harvard Business School, where he works on theoretical foundations of private machine learning, including differential privacy, membership inference attacks, and data deletion. David Wu is an Assistant Professor at the University of Texas at Austin and works broadly on applied and theoretical cryptography. Yun William Yu is an Assistant Professor at University of Toronto, where he works on developing novel algorithms and theories for bioinformatics applications; his expertise also includes private federated queries on clinical databases and digital contact tracing.
What motivated you to participate?:
We viewed this challenge as an exciting opportunity to apply our expertise in privacy-enhancing technologies to help address a timely and meaningful real-world problem. We also believed that the range of relevant backgrounds our team covers, which include both theoretical and applied research in security, privacy and cryptography, algorithms for biomedicine, as well as cloud-based software engineering and deployment, would uniquely enable us to develop an effective solution for the challenge.
Summary of approach:
Our solution introduces MusCAT, a multi-scale federated system for privacy-preserving pandemic risk prediction. For accurate predictions, such a system needs to leverage a large amount of personal information, including one’s infection status, activities, and social interactions. MusCAT jointly analyzes these private data held by multiple federation units with formal privacy guarantees. We leverage the key insight that predictive information can be divided into components operating at different scales of the problem, such as individual contacts, shared locations, and population-level risks. These components are individually learned using a combination of privacy-enhancing technologies to best optimize the tradeoff between privacy and model accuracy.
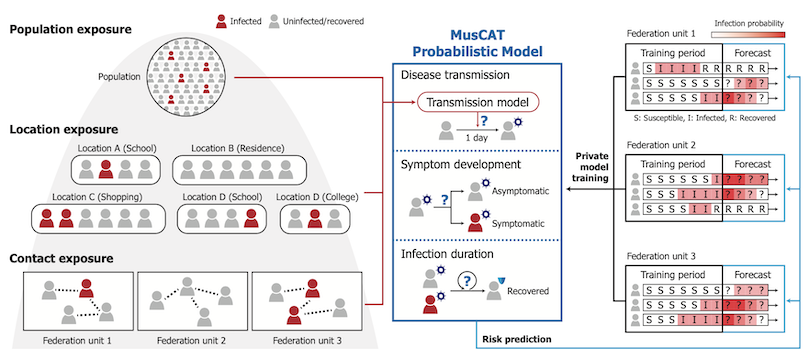
ZS_RDE_AI¶




Place: 3rd in Track B: Pandemic Forecasting and Response
Prize: $25,000
Team members: Qin Ye, Sagar Madgi, Mayank Shah, Shaishav Jain
Hometown: Washington, DC; Bangalore, New Delhi, and Gujarat, India
Representing: ZS Associates
Background:
- Dr. Qin Ye is the Global Integrated Evidence lead for ZS. Qin joined ZS in 2016, where he has been focusing on helping clients realize the value of their RWD and AI investment in R&D through our strategy, data science, and technology capabilities. In his role, Qin leads the development of our RWE team, oversees the development of our innovative RWE offerings, and works directly with clients on evidence generation and advanced data sciences programs across clinical, HEOR, medical, and market access functions. As a trained physician, outcome researcher and data scientist, Qin has over 20 years of health informatics and data analytics experiences with in-depth knowledge of medical terminologies, data standards, various EHR products, and wide range of RWD use cases throughout life sciences product lifecycle.
- Mayank Shah is a Data Science Consultant at ZS and holds a Bachelor’s in Technology for Computer Science from Maharaja Agrasen Institute of Technology. He is an experienced data scientist with experience in Medical Imaging AI, Biomedical NLP, and Statistical analysis with interests in improving clinical trials with AI.
- Shaishav Jain is a Data Science Associate Consultant at ZS. He has a Bachelor’s in Electrical and Electronics Engineering from the Vellore Institute of Technology. He has experience working on different data modalities and problem fields like Medical Imaging AI, NLP, and Patient Identification using EHR data.
- Sagar Madgi is an Associate Principal with the R&D Excellence team in ZS. In this current role, he’s specifically focused on building AI products as well as executing be-spoke AI projects leveraging both clinical and real-world patient data sources. He is experienced in the use of multiple real world data source (claims, EHR) and advanced data science to build products as well as execute be-spoke projects to produce actionable insights across R&D and commercial in the life sciences industry.
What motivated you to participate?:
This was one of our team’s key priorities—federated learning/PETs in the context of healthcare and we determined that this contest would be a good fit to demonstrate our capability. As healthcare entities and government agencies across the globe are becoming more reluctant to allow data sharing in a central place to protect provicy and confidentiality, PPFL concepts are going to be critical to achieve our patient centered objectives. With the world just came out of massive impact of COVID 19 pandemic, the topic of predicting the next pandemic is high on the radar of the world leaders and every ordinary people, this challenge would give us the opportunity to learn from other teams and organizations and how we can collaborate and develop a private and secure AI environment within healthcare to solve such meaningful problem.
Summary of approach:
We present our solution for covid forecasting in a privacy/security preserving manner while optimizing for accuracy using different PETs – FedProx, Differential Private-SGD, Learning with Errors (LWE) Homomorphic Encryption. Our solution provides privacy and security at different layers of data gathering, training, and sharing of model as well as inference from models. Our current solution is currently limited to Logistic Regression since its ease of implementation in Pytorch as compared to Random Forest and XGBoost but these models can be used in a centralized model with ease. A noise vector is additionally added to the data, model, loss function & optimizer by using DP-SGD, which defends against privacy inference attacks while maintaining computational resourcing. Next stage includes sharing gradients/hyperparameters from the various local servers to the central server, where we use LWE to ensure that the weight updates are encrypted with local server key and only the encrypted gradients are shared with the central server to counterfeit model poisoning attacks. The updated central-server global model is shared with local servers (in case of FL) to improve the global model to provide defense against different attacks like model inversion & model extraction which we aim to reduce by controlling overfitting.
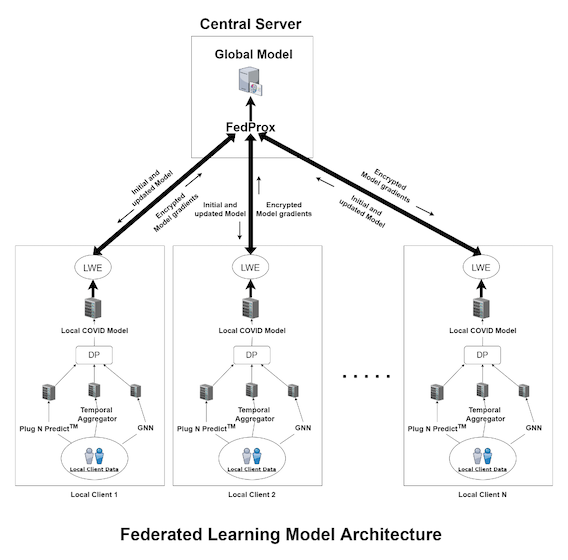
Red Teams ¶
ETH SRI¶







Place: 1st
Prize: $60,000
Team members: Petar Tsankov, Dimitar Iliev Dimitrov, Nikola Jovanović, Martin Vechev, Mark Vero, Jasper Dekoninck, Mislav Balunović
Hometown: Marietta, GA; Zürich, Switzerland
Affiliation: ETH Zurich
Social Media: @ptsankov//in/petartsankov, @dimitrov_dimy, @ni_jovanovic, @mvechev//in/martinvechev, https://twitter.com/mbalunovic
Background:
The Secure, Reliable, and Intelligent Systems Lab (SRI) is a research group in the Department of Computer Science at ETH Zurich. Our current research focus is on the areas of reliable, secure, robust and fair machine learning, probabilistic and quantum programming, and machine learning for code. Our team has published several research papers about privacy attacks on federated learning (FL), such as gradient leakage attacks and its extensions to natural language processing and tabular data.
What motivated you to participate?:
Our team has a proven record of uncovering and documenting privacy threats in FL. The competition provided an excellent opportunity to apply our expertise to real-world FL problems, gaining valuable insights into how FL is used outside the research labs and into the security pitfalls resulting from this. The competition further informed our research by challenging us to generalize existing attacks to broader settings and explore new attack methods. Ultimately, the competition taught us to expand the scope of the privacy issues we look for in FL systems in ways we haven't thought of before.
Summary of approach:
The highly custom solutions to both tracks presented in the Challenge required us to work out a good approach for each track separately. In the financial crime track we considered the safety of the flag value at the banks as an essential part of any good solution. We therefore focused on attacks exposing this as a boolean value and found highly generalizable attacks with near-perfect accuracy. For the pandemic track however, we focused more on the privacy-utility trade-off. We showed successfully that the blue teams' solutions had little utility, and that they did not outperform more private locally trained models.
Entmoot¶

Place: 2nd
Prize: $40,000
Team members: Anthony Cardillo
Hometown: New York, NY
Social Media: /in/anthony-cardillo-md
Background:
Anthony Cardillo, MD is a Clinical Informatics fellow and Clinical Instructor in Pathology at NYU in New York City. His research interests include the implementation of secure artificial intelligence and in-silico laboratory testing methods.
What motivated you to participate?:
My goal is to transfer the brilliant learning approaches devised by engineers and computer scientists into the world of medicine. Federated learning, in particular, applies so perfectly to the medical landscape that I want to do my part in fostering its uptake.
Summary of approach:
In the preparatory phase, I read every paper and made sure I understood the theoretical concepts behind homomorphic encryption, differential privacy, and secure multiparty computation. These are rock-solid technologies, but there is a huge difference between a solution saying they use these privacy techniques versus implementing them correctly. My goal during the preparatory and attack periods was to look for the incredibly subtle ways these powerful techniques could be incorrectly implemented. This involved tracing the logic of all the source code, looking for small holes in otherwise impenetrable armor.
Blackbird Labs¶

Place: 3rd
Prize: $20,000
Team members: Kenneth Ambler, Kevin Liston, Mike Gemmer
Hometown: Akron, OH
Background:
Blackbird Labs is a team of professionals that craft real world solutions today for theoretical problems in the future. Composed of a three-member core group and several affiliate members, BBL members work in the financial field finding financial fraud, build software for creating and enhancing healthcare data solutions, and spend time teaching the next generation of professionals who will continue our work into the future. One team member works for a financial institution, another is an application developer, and third member teaches at the university level. We find that our diversity in background is our strength.
What motivated you to participate?:
For us, this is personal. Our team has members who worked during the height of the pandemic, providing support and care to frontline hero’s and we also have members that track financial fraud and prevent fraud. For both tracks, this affects real people in their everyday lives, and we want to help create a practical solution for future problems.
Summary of approach:
Our approach involves simulating the attacks that we've seen in the wild, using profit over prestige as the motivation of the attacker. We start with the information that they provided the endpoints and leverage the weaknesses in their implementations to identify signals and oracles in the data to work our way back to the plaintext. To assist in our approach, we would read through their plan and try to come up with an approach they hadn't considered, then examined their implementation for any errors, and used that to develop the exploit paths.
Thanks to all the participants and to our winners! Special thanks to the National Institute for Standards and Technology (NIST) and the National Science Foundation (NSF) for enabling this fascinating challenge, the Office of Science and Technology Policy (OSTP) and NASA for their collaboration, the UVA Biocomplexity Institute and Swift for providing the synthetic datasets, and the judges and reviewers for their time and input!



















