

Video Similarity Challenge¶
Meet the top teams who identified copied and manipulated videos!¶
Participants in the Meta AI Video Similarity Challenge found creative ways to improve representations used for copy detection, as well as localization techniques that allow copied sections to be identified efficiently within longer videos.
Ed Pizzi, Meta AI Research Scientist and Video Similarity Challenge author
The ability to identify and track content on social media platforms, called content tracing, is crucial to the experience of billions of users on these platforms. Previously, Meta AI and DrivenData hosted the Image Similarity Challenge in which participants developed state-of-the-art models capable of accurately detecting when an image was derived from a known image. The motivation for detecting copies and manipulations with videos is similar — enforcing copyright protections, identifying misinformation, and removing violent or objectionable content.
In December 2022, DrivenData and Meta AI launched the Video Similarity Challenge. Across two competition tracks and two phases of data release, competitors were challenged to build models capable of identifying whether a given query video contained content derived from any video in a set of over 40,000 reference videos. In the months that followed, members of the DrivenData community participated in the challenge, and we're excited to share the winning teams' solutions!
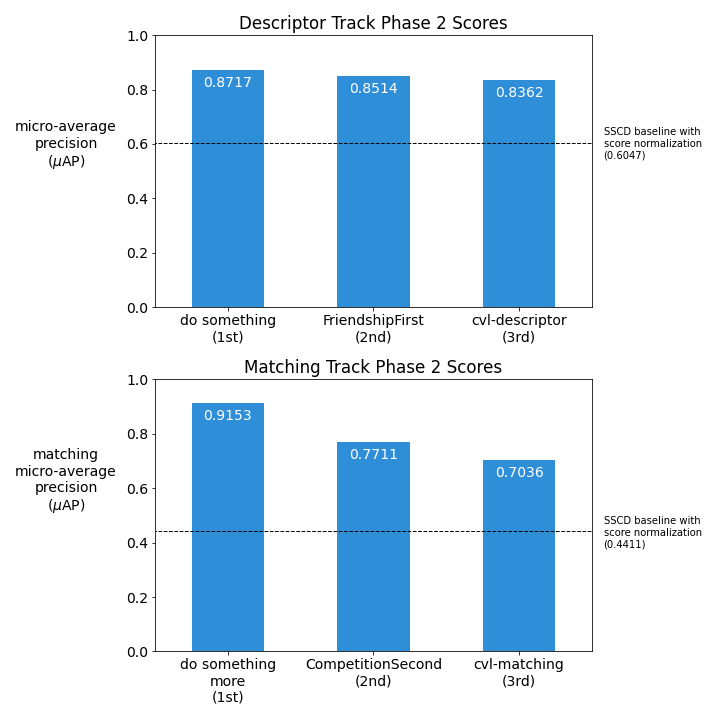
Between December 2022 and April 2023, 404 participants from 59 countries signed up to solve the problems posed by the two tracks, and 82 went on to submit solutions. For the Descriptor Track, participants were tasked with generating useful vector embeddings for videos, up to one embedding per second of video, such that derived videos would receive high similarity scores to their corresponding reference video. For the Matching Track, participants were tasked with identifying the segments of a query video derived from corresponding segments of a reference video; Meta AI designed a segment-matching micro-average precision metric to measure performance on this Matching Track task.
The winning solutions significantly improved on the baseline models provided by Meta. The top Descriptor Track solution improved on the baseline model by more than 40% (from 0.6047 to 0.8717), and the top Matching Track solution improved on the baseline model by more than 105% (from 0.4411 to 0.9153).
Congratulations to the winners, runners-up, and all who participated! All prize-winning solutions have been released under an open source license for ongoing development and learning. We'll share details and common themes on the winning solutions below, but first, some background on the competition for those who are new to it.
Competition Background¶
Manual content moderation has challenges scaling to meet the large volume of content on platforms like Instagram and Facebook, where tens of thousands of hours of video are uploaded each day. Accurate and performant algorithms are critical in flagging and removing inappropriate content. This competition allowed users to test their skills in building a key part of that content tracing system, and in so doing contribute to making social media more trustworthy and safe for the people who use it.
Data¶
For this competition, Meta AI compiled a new dataset composed of approximately 100,000 videos derived from the YFCC100M dataset. This dataset was divided into a training set, a Phase 1 test set, and a Phase 2 test set. Both the train and test sets are further divided into a set of reference videos, and a set of query videos that may or may not contain content derived from one or more videos in the reference set. The following examples show some of the different ways in which content from reference videos was included in query videos.
The video on the left is a reference video. The video on the right is a query video that contains a clip that has been derived from the reference video — in this case, a portion of the query video (from 0:00.3 to 0:05.7) contains a portion of the reference video (from 0:24.0 to 0:29.43) that has been surrounded in all four corners by cartoon animals and had a static effect applied:
|
|
|
| Credit: walkinguphills | Credit: walkinguphills, Timmy and MiNe (sfmine79) |
Edited query videos may have been modified using a number of techniques. The portion of the following reference video (from 0:05.0 to 16.6) inserted into the query video (from 0:05.6 to 16.9) has been overlayed with a transparency effect:
|
|
|
| Credit: Timo_Beil | Credit: Timo_Beil and Neeta Lind |
Editing techniques employed on the challenge data set included:
- blending videos together
- altering brightness or contrast
- jittering color or converting to grayscale
- blurring or pixelization
- altering aspect ratio or video speed, looping
- rotation, scaling, cropping, padding
- adding noise or changing encoding quality
- flipping or stacking horizontally or vertically
- formatting as a meme; overlaying of dots, emoji, shapes, or text
- transforming perspective and shaking; transition effects like cross-fading
- creating multiple small scenes; inserting content in the background
Please also note that as part of the data cleaning process, faces were obscured from the videos using a segmentation mask.
Although synthetically created by our sponsors at Meta AI, the transformations are similar to those seen in a production setting on social media platforms, with a particular emphasis on the ones that are more difficult to detect. Some query videos contained content derived from multiple reference videos.
Performant solutions needed to differentiate between videos that had been copied and manipulated and videos that are simply quite similar. Below are two examples of such similar, but not copied, videos.
|
|
|
| Credit: thievingjoker | Credit: thievingjoker |
|
|
|
| Credit: Gwydion M. Williams | Credit: Gwydion M. Williams |
Code Execution and Resource Constraint¶
This challenge was a hybrid code execution challenge. In addition to submitting video descriptors or predictions for the test dataset of each phase, participants packaged everything needed to do inference and submitted that for containerized execution on a subset of the test set. Prize-eligible participant solutions were required to satisfy a resource constraint — for each track, inference on a representative subset of videos from the test dataset must take, on average, no more than 10 seconds per query video on the hardware provided in the execution environment.
This resource constraint provided an additional layer of complexity to the competition, and challenged competitors to design solutions that would be directly relevant to the demanding environments of production systems.
Common Approaches in Winning Solutions¶
Winning solutions varied in their approaches, but some common themes were apparent.
- Image models, not video models: All winning solutions found that pipelines and models built on frames sampled from videos, rather than video clips, were sufficient for the descriptor-generation and matching tasks. Image models are also less computationally intensive, making it easier to satisfy the resource constraint.
- Self-supervision: As in the Image Similarity Challenge, all winning solutions used self-supervised learning and image augmentation (or models trained using these techniques) as the backbone of their solutions. Self-supervised learning allows for effective use of unlabeled data for training models for representation learning tasks.
- Edit detection and inference-time augmentation: Two of the winning solutions additionally trained models that attempted to classify whether a given query video had been edited and, if so, to classify the edit as a particular type of augmentation (e.g., two videos edited so they were side-by-side vertically or horizontally). This classification was then used to de-couple videos so that the generated descriptors corresponded to an image containing only the content from a particular reference video.
- Leveraging the baseline: All winning submissions leveraged parts of code from the baseline provided by Meta AI.
Meet the Winners¶
Below are the winners of the Video Similarity Challenge, along with information about their submissions. All the winners were invited to present their solutions at the Visual Copy Detection Workshop of the 2023 Conference on Computer Vision and Pattern Recognition (CVPR)!
Tianyi Wang, Zhenhua Liu, Feipeng Ma, Fengyun Rao¶

|

|

|

|
Prize rank: 1st place Descriptor Track, 1st place Matching Track
Prize: $50,000 ($25,000 Descriptor Track, $25,000 Matching Track)
Hometown: China
Team: do something / do something more
Usernames: forsha, mafp, tyewang, JiangNan
Github repo: https://github.com/FeipengMa6/VSC22-Submission
Documentation links: Descriptor Track: A Dual-level Detection Method for Video Copy Detection, Matching Track: A Similarity Alignment Model for Video Copy Segment Matching
Background:
Tianyi Wang is a senior researcher at WeChat focusing on multi-modal pre-training and LLMs (Large Language Models).
Zhenhua Liu is a senior researcher at WeChat focusing on copy detection.
Feipeng Ma is an intern at WeChat and a Ph.D. candidate at the University of Science and Technology of China focusing on multi-modal learning and video understanding.
Fengyun Rao is an expert researcher at WeChat focusing on video understanding.
What motivated you to compete in this challenge?
Given the proliferation and widespread sharing of videos on social media, video copy detection has emerged as a critical technology for copyright protection. Our team possesses extensive expertise in copy detection and is excited to participate in competitions that will enable us to evaluate and validate our advanced technology. We also look forward to sharing our solutions to further advance this field.
Summary of approach:
Descriptor Track:
- We train a basic model based on the provided baseline, but with advanced backbones and strong augmentation to improve performance. Our single model is very strong.
- We train a model to discriminate whether a video has been edited or not, with videos that lack any edited portions having a lower probability of being classified as a copied video. And we use a random vector with very small norm as a descriptor of unedited video.
- To address the issue of stacked videos, we employed traditional methods to detect and split them into multiple distinct videos. A similar method is also applied to strip the extra edges attached around the video.
Matching Track:
- We developed a pipeline method to align video copy segments. With the video pair embedding similarity matrix as input, we first trained a classifier to filter a large numbers of non-copy recalls from the descriptor stage. Then an align-refine model is trained to learn the matching relationships based on local and global features. Our matching method is strong and robust, and even with baseline descriptor features it can achieve superior result.
- To address the issue of stacked videos, we employed traditional methods to detect and split them into multiple distinct videos. A similar method is also applied to strip the extra edges attached around the video.
Wenhao Wang, Yifan Sun, Yi Yang¶

|

|

|
Prize rank: 2nd place Descriptor Track, 2nd place Matching Track
Prize: $30,000 ($15,000 Descriptor Track, $15,000 Matching Track)
Hometown: China
Team: FriendshipFirst / CompetitionSecond
Username: wenhaowang, evermore, xlover
Github repo: https://github.com/WangWenhao0716/VSC-DescriptorTrack-Submission, https://github.com/WangWenhao0716/VSC-MatchingTrack-Submission
arXiv link: Feature-compatible Progressive Learning for Video Copy Detection
Background:
Wenhao Wang is a Ph.D. student in ReLER, University of Technology Sydney, supervised by Yi Yang. His research interest is deep metric learning and computer vision. Prior to Baidu, he was a Research Intern in Baidu Research from 2021 to 2022 and a Remote Research Intern in Inception Institute of Artificial Intelligence from 2020 to 2021.
Yifan Sun is currently a Senior Expert at Baidu Inc. His research interests focus on deep representation learning, data problem (e.g., long-tailed data, cross-domain scenario, few-shot learning) in deep visual recognition and large visual transformers. He has publications on many top-tier conferences/journals such as CVPR, ICCV, ICLR, NeurIPS and TPAMI. His papers have received over 5000 citations and some of his researches have been applied into realistic AI business.
Yi Yang is a Professor with the college of computer science and technology, Zhejiang University. He has authored over 200 papers in top-tier journals and conferences. His papers have received over 52,000 citations, with an H-index of 111. He has received more than 10 international awards in the field of artificial intelligence, such as the National Excellent Doctorate Dissertations, the Zhejiang Provincial Science Award First Prize, the Australian Research Council Discovery Early Career Research Award, the Australian Computer Society Gold Digital Disruptor Award, the Google Faculty Research Award and AWS Machine Learning Research Award.
What motivated you to compete in this challenge?
Our strong interest on deep metric learning motivated us to compete in this challenge. As a team, we have good experience with deep metric learning techniques such as image copy detection, face recognition, and fine-grained image retrieval. We are delighted to contribute our solution for the objective of countering misinformation and copyright infringement, which is the keynote of VSC 2022. We believe VSC 2022 makes good social impact and is of great value to the deep learning research community.
Summary of approach
We propose a Feature-compatible progressive learning for Video Copy Detection. We first train a base model. Then we train six models which generate features that are compatible with the base model. Finally, we tune the six models on the ground truth pairs. The ensemble result of the six models is regarded as the final submission.
Shuhei Yokoo, Peifei Zhu, Junki Ishikawa, Rintaro Hasegawa¶

|

|

|

|
Prize rank: 3rd place Descriptor Track, 3rd place Matching Track
Prize: $20,000 ($10,000 Descriptor Track, $10,000 Matching Track)
Hometown: Tokyo, Japan; China; Tokyo, Japan; Saitama, Japan
Team: cvl-descriptor / cvl-matching
Usernames: lyakaap, PeifeiZhu, cafeal, rintaro121
Github repo: https://github.com/line/Meta-AI-Video-Similarity-Challenge-3rd-Place-Solution
arXiv link: 3rd Place Solution to Meta AI Video Similarity Challenge
Background:
Shuhei Yokoo works at LINE Corporation. He is a Kaggle Grandmaster and an enthusiast of data science competitions. His interest area is image and video retrieval.
Peifei Zhu works for LINE Corporation in Tokyo, Japan. Currently her research interest is computer vision and machine learning, especially video retrieval and adversarial attack.
Junki Ishiakwa is an ML engineer at LINE Corporation, developing billion-scale recommendation system for chat-room sticker and internal ML platform.
Rintaro Hasegawa is currently a master's student at Keio University.
What motivated you to compete in this challenge?
We currently working on a video copy detection to apply contents moderation for a short video sharing service. Since the problem settings in this competition is very similar to our settings, we decided to participate in order to accelerate research and development and obtain useful knowledge.
Summary of approach:
We propose a simple yet powerful video copy detection pipeline, based on an image copy detection model (ISCdt1). Our approach utilizes test time augmentation based on the predictions of an editing prediction model. We exploit the properties of videos through various techniques: emphasizing copy videos more in search results by calculating frame consistency, concatenating adjacent frames followed by dimensionality reduction using PCA, and localizing copied frames by employing Temporal Network.
Thanks to all the participants and to our winners! Special thanks to Meta AI Research for enabling this important and exciting challenge and for providing the data to make it possible!
No FOMO!¶
If you are worried that you missed out on your opportunity to explore this dataset and try your hand at each of the competition's tracks, fear not! The dataset is currently available in the Open Arena for ongoing learning and research. Take a look and see how you would have scored against the top competitors.



















