
Welcome to our series on using Azure Machine Learning. We've been using these tools in our machine learning projects, and we're excited to share everything we've learned with you!
- The missing guide to AzureML, Part 1: Setting up your AzureML workspace
- The missing guide to AzureML, Part 2: Configuring your compute script and compute target (This post!)
- The missing guide to AzureML, Part 3: Connecting to data and running your machine learning pipeline
In Part 1 of this guide, you became familiar with the core Azure and AzureML concepts, set up your AzureML workspace, and connected to your workspace using the AzureML Python SDK. In this post, we'll give an overview of what a complete machine learning workflow looks like, and we'll go into detail about how to configure two components of the workflow: the code that you want to run (the compute script) and the cloud "hardware" you want to run it on (the compute target).
AzureML pipelines¶
A machine learning workflow is specified as an AzureML pipeline. A typical pipeline comprises a few pieces:
- Compute script: a Python script containing code that runs our algorithm and exposes a command line interface (we will also need to specify an environment containing all of the dependencies for the script)
- Input data: a path to load our input data from
- Additional parameters: anything that can be passed to the compute script as a command line argument
- Output data: a path to save our output data to
A more concrete example of a pipeline might be one that trains a classifier (compute script) on training dataset (input data) with a regularization hyperparameter (additional parameter), runs inference on held-out data and saves out the predicted labels (output data). For the sake of simplicity, we will focus on a much simpler pipeline: one that adds (compute script) a scalar value (additional parameter) to an input array (input data) and saves the resulting array (output data). In spite of the fact that one of these pipelines is kind of useful and the other is quite dumb, the structure of both pipelines is the same:
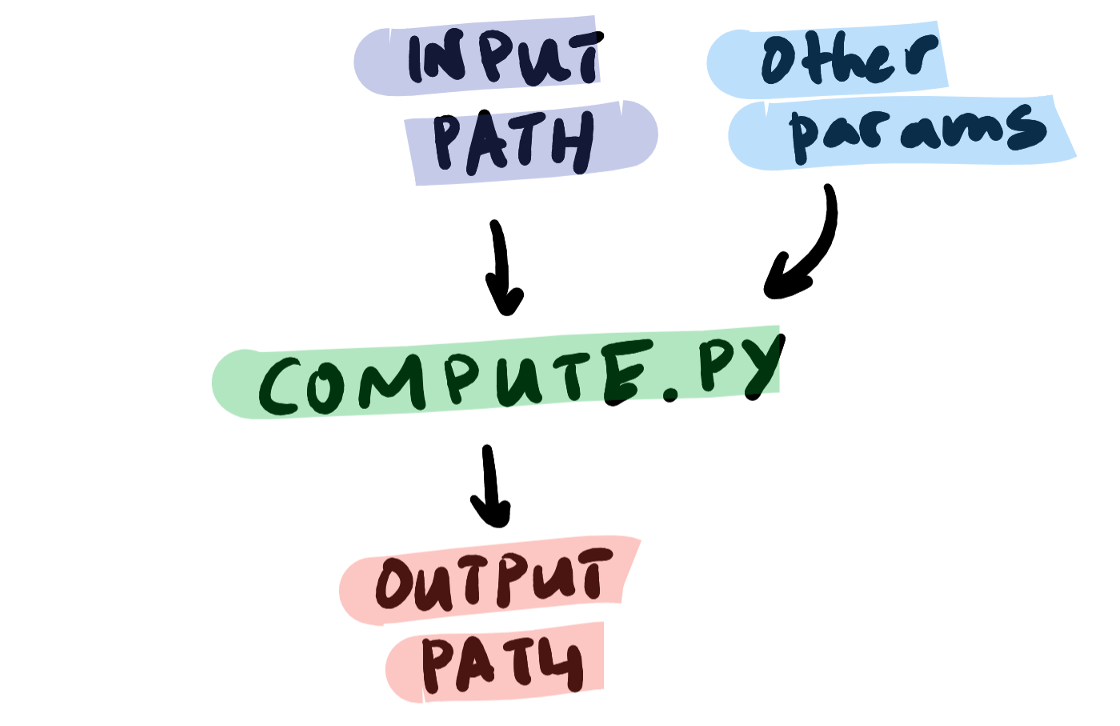
You describe a pipeline (the nodes and connections between the nodes) with an orchestrate script (not official AzureML terminology ― just useful to distinguish it from the compute script). The orchestrate script uses the azureml Python package to tell AzureML which data to load, which compute script to use, which environment to run it in, which compute resources to use, and where to store outputs. The basic form will look like this:
# Connect to your AzureML workspace
from azure.core import Workspace
workspace = Workspace.from_config()
# Input data
from azureml.data.data_reference import DataReference
input_path = DataReference(...)
# Additional parameters
from azureml.pipeline.core import PipelineParameter
other_parameter = PipelineParameter(...)
# Output data
from azureml.pipeline.core import PipelineData
output_path = PipelineData(...)
# Specify the environment
from azure.core import Environment
environment = Environment(...)
run_config = RunConfiguration()
run_config.environment = environment
# Specify the compute target
compute_target = workspace.compute_targets[...]
run_config.target = compute_target
# Compute script
from azureml.pipeline.steps import PythonScriptStep
step = PythonScriptStep(
script_name="script.py",
arguments=[input_path, output_path, other_parameter]
inputs=[input_path],
outputs=[output_path],
runconfig=run_config,
...,
)
# Connect the pieces of the pipeline
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=workspace, steps=[step])
# Run the pipeline
experiment_name = "my_experiment"
pipeline.submit(experiment_name)
In the remainder of this post we'll go over how to configure the compute script, the software environment, and the compute target. (We'll leave the input data, output data, additional parameters, and putting it all together for the next post).
Sources:
- What are Azure Machine Learning pipelines?
- Azure Machine Learning Pipelines: Getting Started
- Azure Machine Learning Pipelines with Data Dependency
Compute script and its runtime environment¶
A Python script is incorporated into your AzureML pipeline via the PythonScriptStep class, which combines a compute script with a run configuration. The run configuration itself combines a software environment and compute target.
Compute script¶
The compute script is some Python code that carries out the desired analysis. It typically uses machine learning packages like sklearn or pytorch and does something like fit a model or run inference on an existing model. It generally doesn't use much AzureML-specific code (logging is an exception that we'll cover later). It must have a command line interface, which can take any number of parameters. Input and output are accomplished by reading and writing files.
Software environment¶
In addition to the compute script, we need to specify the runtime environment for the script. Typically speficying your environment boils down to providing a list of the Python packages used in your compute script. Environments are stored and tracked in your AzureML workspace. Your workspace already contains some built-in "curated" environments covering common machine learning software. You can use the Environment object to interact with the environments in your workspace. For example, to view existing environments in your workspace:
from azureml.core import Environment, Workspace
workspace = Workspace.from_config()
environments = Environment.list(workspace=workspace)
for environment_name in environments:
print(environment_name)
# AzureML-Tutorial
# AzureML-Minimal
# AzureML-Chainer-5.1.0-GPU
# AzureML-PyTorch-1.2-CPU
# AzureML-TensorFlow-1.12-CPU
# ...
The configuration of an individual environment is a dict with a lot of parameters. Some of the relevant ones are:
environments["AzureML-Tutorial"]
{
...
"name": "AzureML-Tutorial",
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"condaDependencies": {
"channels": [
"conda-forge",
"pytorch"
],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-core==1.4.0.post1",
...
"sklearn-pandas"
]
},
"pandas",
"numpy",
"tqdm",
"scikit-learn",
"matplotlib"
...
],
"name": "azureml_f626..."
},
"docker": {
"enabled": false,
"baseImage": "mcr.microsoft.com/azureml/base:intelmpi2018.3-ubuntu16.04",
...
},
...
}
Sources:
Creating a custom environment via pip and requirements.txt¶
You can also create your own environments if the curated environments don't have what you need. It's easy with the azureml SDK. For example, let's say I want to use spaCy, and I have a requirements.txt like so:
spacy==2.2.4
AzureML lets you configure an environment directly from the requirements.txt file using Environment.from_pip_requirements:
from azureml.core import Environment, Workspace
from pathlib import Path
requirements_path = Path("./requirements.txt").resolve()
environment = Environment.from_pip_requirements(
name="SpacyEnvironment", file_path=requirements_path
)
environment
# "name": "SpacyEnvironment",
# "version": null,
# "environmentVariables": {
# "EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
# },
# "python": {
# "userManagedDependencies": false,
# "interpreterPath": "python",
# "condaDependenciesFile": null,
# "baseCondaEnvironment": null,
# "condaDependencies": {
# "name": "project_environment",
# "dependencies": [
# "python=3.6.2",
# {
# "pip": [
# "spacy==2.2.4
# ]
# }
# ],
# "channels": [
# "conda-forge"
# ]
# }
# },
# ...
# save the environment to the workspace
workspace = Workspace.from_config()
environment.register(workspace=workspace)
This will create a new environment containing your Python dependencies and register that environment to your AzureML workspace with the name SpacyEnvironment. You can try running Environment.list(workspace) again to confirm that it worked. You only need to do this once — any pipeline can now use your new environment.
Source:
Compute target¶
Finally, we need to specify the compute target, i.e., the hardware that the compute script should run on. AzureML offers a wide range of compute targets. While you can configure new compute targets using the azureml package (AmlCompute), the simplest way is to set one up in the AzureML studio. Click "Compute" > "Compute clusters" > "New". You can view the compute targets associated with your AzureML workspace using the workspace.compute_targets attribute, a dictionary of compute targets by compute target name.
from azureml.core import Workspace
workspace = Workspace.from_config()
# List the names of existing compute targets
workspace.compute_targets.keys()
# dict_keys(['cpu'])
compute_target = workspace.compute_targets["cpu"]
compute_target
# AmlCompute(workspace=Workspace.create(name='Machine-Learning', subscription_id='01234567-890a-bcde-f012-3456789abcde', resource_group='Resource-Group'), name=cpu, id=/subscriptions/01234567-890a-bcde-f012-3456789abcde/resourceGroups/Resource-Group/providers/Microsoft.MachineLearningServices/workspaces/Machine-Learning/computes/cpu, type=AmlCompute, provisioning_state=Succeeded, location=westus, tags=None)
RunConfiguration¶
To pass an environment and compute target to your PythonScriptStep, you need to instantiate a RunConfiguration object and update its attributes. It looks a bit strange, but that's how it is!
from azureml.core import Workspace
from azureml.core.runconfig import RunConfiguration
workspace = Workspace.from_config()
run_config = RunConfiguration()
environment # curated or custom environment
environment.docker.enabled = True # preferred for AzureML compute jobs
run_config.environment = environment
compute_target = workspace.compute_targets["cpu"]
run_config.target = compute_target
Sources:
To review: in this post, we gave an overview of the AzureML pipeline, which completely specifies a computational task including the inputs, code, runtime environment, and outputs. We went into more detail about how exactly to specify the code and its runtime environment — from wrapping your custom Python script into a PythonScriptStep, to configuring the software environment with Environment, to configuring the hardware using AzureML studio and Workspace.compute_targets. In the third and final post in the series, we'll go even further to cover how to direct your pipeline to some data and save the output. By the end of it, you'll be able to run your first pipeline on AzureML!



















